some example
当x为binary时

structure
以四层的multi-class classification为例(以01向量列表示分类预测。第i个最接近1则预测为第i个)
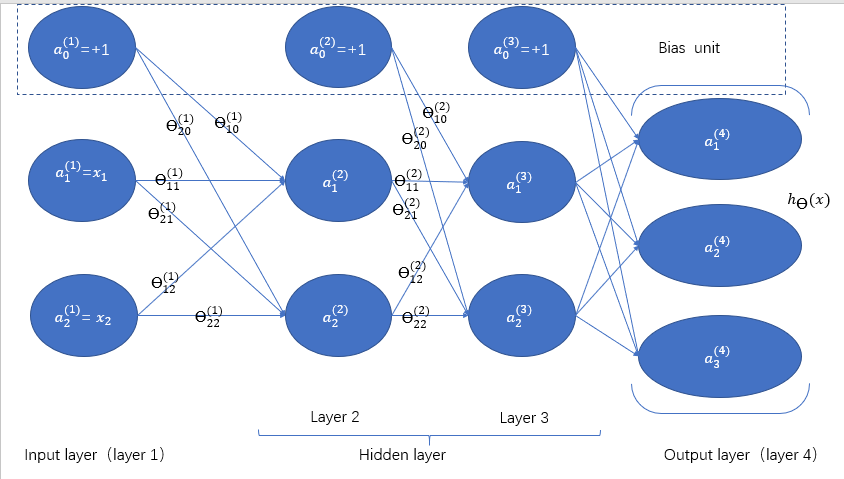
( heta^{(l)}_{ji})表示第(l)层第(i)个神经元到下一层第(j)个神经元的转移的系数
记(S_l)为第(l)层除了bias unit之外的unit个数
则( heta^{(l)})大小为(S_{l+1} imes(S_l + 1))
(a^{(l+1)}=sigmoid( heta^{(l)} a^{(l)})) (别漏了sigmoid)
存储时每层一个列向量这样比较好
cost function
对于multiclass-classification
(h_{ heta})是指从input到output
注意(i)不从0开始
这个J是non-convex,有local minimum
FP & BP原理
记输入层为X, 各层向量为 ( heta_1 cdots heta_l)
则 (F(X, heta_1, cdots, heta_l) = loss(f_n(f_{n-1}(cdots f_2( f_1(X, heta_1), heta_2)cdots, heta_{n-1}), heta_n)))
期中(f_1cdots f_n) 为向量值函数, (F, loss) 为单值函数
我们要 求各 ( heta) 的偏导,步骤都是偏导拆括号,偏没有theta那边,然后直到theta是自己的theta了,然后偏theta那边
前面疯狂拆括号的步骤的类似的,且可叠加
所以有了反向传播算法
gradient (FP & BP)
P = propagation
F = forward
B = backward
先忽略掉regularization的部分
相当于求(-frac 1 msum_{k=1}^K sum_{i=1}^m y_k^{(i)} ln(a^{(L)}_k) + (1-y_k^{(i)}) ln(1 - a^{(L)}_k))
根据之前在classification中的推导,我们记得配合sigmoid函数可以把这个复杂的函数求导后变得很简单
因为转移为(z^{(L)}_j = a^{(L-1)}_i heta^{(L-1)}_{ji}), (a^{(L)}_j = g(z^{(L)}_j)), 换一下
令(f(z) =-frac 1 m sum_{k=1}^K sum_{i=1}^m y_k^{(i)} ln(g(z)) + (1-y_k^{(i)}) ln(1 - g(z)))
求导得(frac{df}{dz} =-frac 1 m sum_{k=1}^K sum_{i=1}^m y_k^{(i)} frac{g'(z)}{g(z)} + (1-y_k^{(i)}) frac{-g'(z)}{1-g(z)})
利用sigmoid函数性质, 推得(frac {df}{dz} = g(z)_k - y_k^{(i)} = a^{(L)}_k - y_k^{(i)})
现在我们要求所有( heta^{(l)}_{ji})的偏导,即(frac{partial f}{partial heta} = frac{df}{dz} frac{partial z}{partial heta})
举个简单得例子,考虑神经网络得得正向路径a->b->c->d
(z^{(L)}_d = heta^{(L-1)}_{dc} a^{(L-1)}_c = heta^{(L-1)}_{dc} g( heta^{(L-2)}_{cb} a^{(L-2)}_b)= heta^{(L-1)}_{dc} g[ heta^{(L-2)}_{cb} g( heta^{(L-3)}_{ba} a^{(L-3)}_a)])
(frac{partial z}{partial heta^{(L-3)}_{ba}} = heta^{(L-1)}_{dc} g'(z^{(L-1)}_c) heta^{(L-2)}_{cb} g'(z^{(L-2)}_b) a^{(L-3)}_a) (注意g里面是z别和a搞混了)
前面系数两两一组,每组第一个是从后一层转移,第二个是乘当前层系数
最后单独剩一个系数
考虑线性性,所有像例子中这样的路径叠加就是结果
首先我们对于每组数据((x^{(i)}, y^{(i)})),进行FP,得到每一层的激活值。
然后我们进行BP,得到每个theta在这组数据下的J的偏导
先考虑两两一组的系数,我们记(delta^{(l)}_i)记录第(l)层第(i)个非bias unit的后续系数和
那么$delta^{(L)}_k = a^{(L)}_k -y_k^{(i)} $
转移:(delta^{(l)} = ( heta^{(l)})^T delta^{(l+1)})
乘当前层:(delta^{(l)}) .* (g'(z^{(l)})) ,其中由sigmoid性质得 (g'(z^{(l)}) = a^{(l)}) .* ((1 - a^{(l)}))
剩下的单独那个系数就好办了。
(Delta^{(l)}_{ji} = delta^{(l+1)}_j a^{(l)}_i)。这居然也可以矩阵化: (Delta^{(l)} = delta^{(l+1)} (a^{(l)})^T) (竖的乘横的)
最后补上regularization那项就好了,注意(i=0)得(Delta)不用补
。
可以用对每个单独theta进行类似(frac{J(x+epsilon)-J(x-epsilon)}{2epsilon})的操作近似求偏导,来进行debug确保上述复杂求导过程的正确性
initial theta
不能全部theta设为同一个相同的值
否则得到的每层内部的a都一样(除了input层),BP时得到每层内部的(delta)都一样(除了output层)
进而(Delta)都一样(除了input层),进而导致梯度下降后得到的图每两层之间的所有边权重相同(除了一二层间)
一二层间同一起点连出的边权重相同
这样第二次梯度下降又是类似的,打破不了“对称性”
所以要随机设theta为([-epsilon,epsilon])
实现问题
传参:没有三维矩阵这种东东
V = [theta1(:);theta2(:)] 配合 theta2=reshape(V(l, r), a, b)。 其中l,r为vector化后所在区间,a,b为目标的原来theta2的长和宽