原创转载请注明出处:https://www.cnblogs.com/agilestyle/p/12251503.html
DataFrame
DataFrame代表一个矩阵数据表,并包含一个有序的列集合,每个列可以是不同的值类型(数字,字符串,布尔值等)。
DataFrame同时具有行索引和列索引;可以将其视为所有共享相同索引的Series的字典。
在后台,数据存储为一个或多个二维块,而不是列表,字典或其他一些一维数组的集合。

创建DataFrame
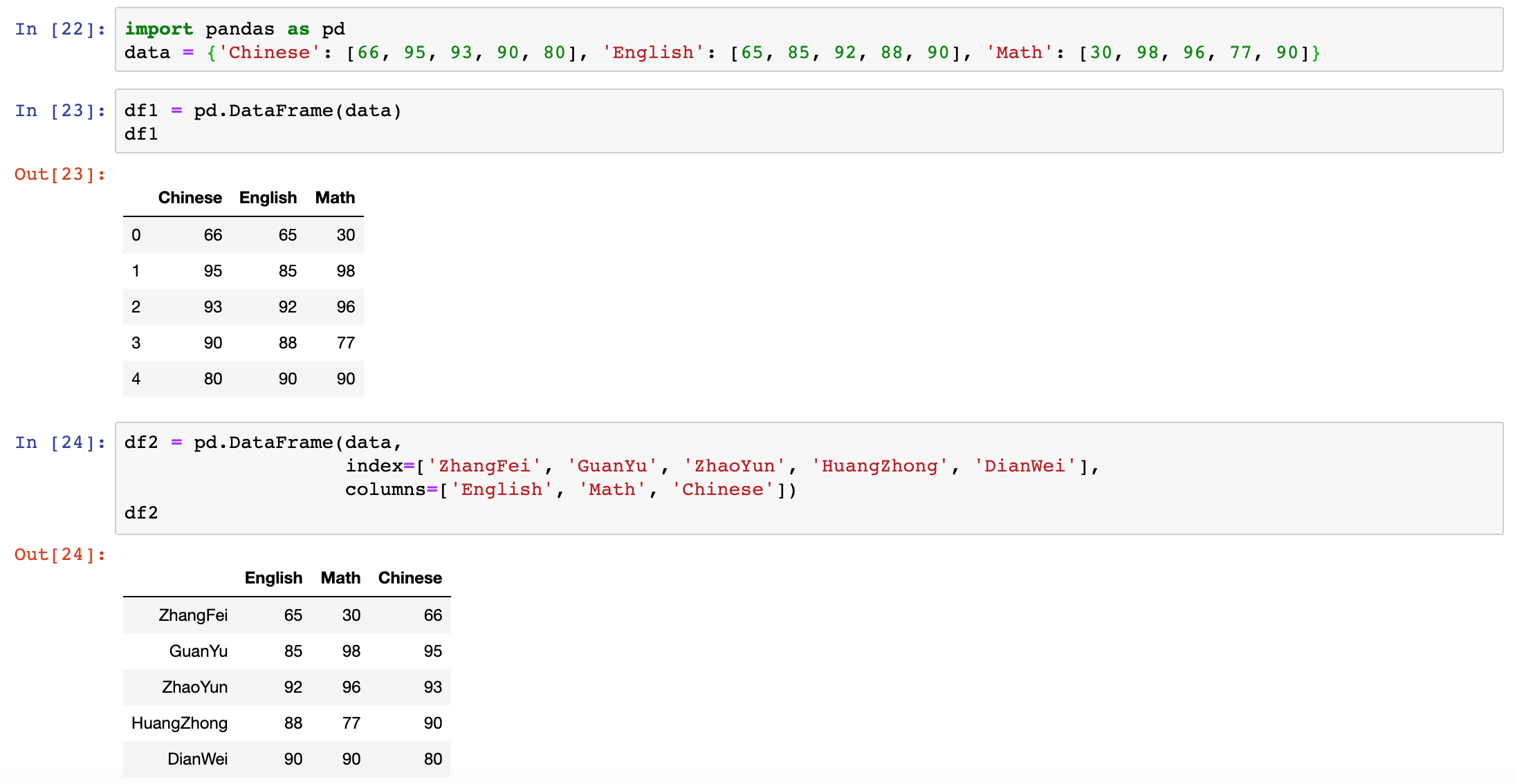
Note: df2的列索引是[‘English’, ‘Math’, ‘Chinese’],行索引是[‘ZhangFei’, ‘GuanYu’, ‘ZhaoYun’, ‘HuangZhong’, ‘DianWei’]
数据导入与导出
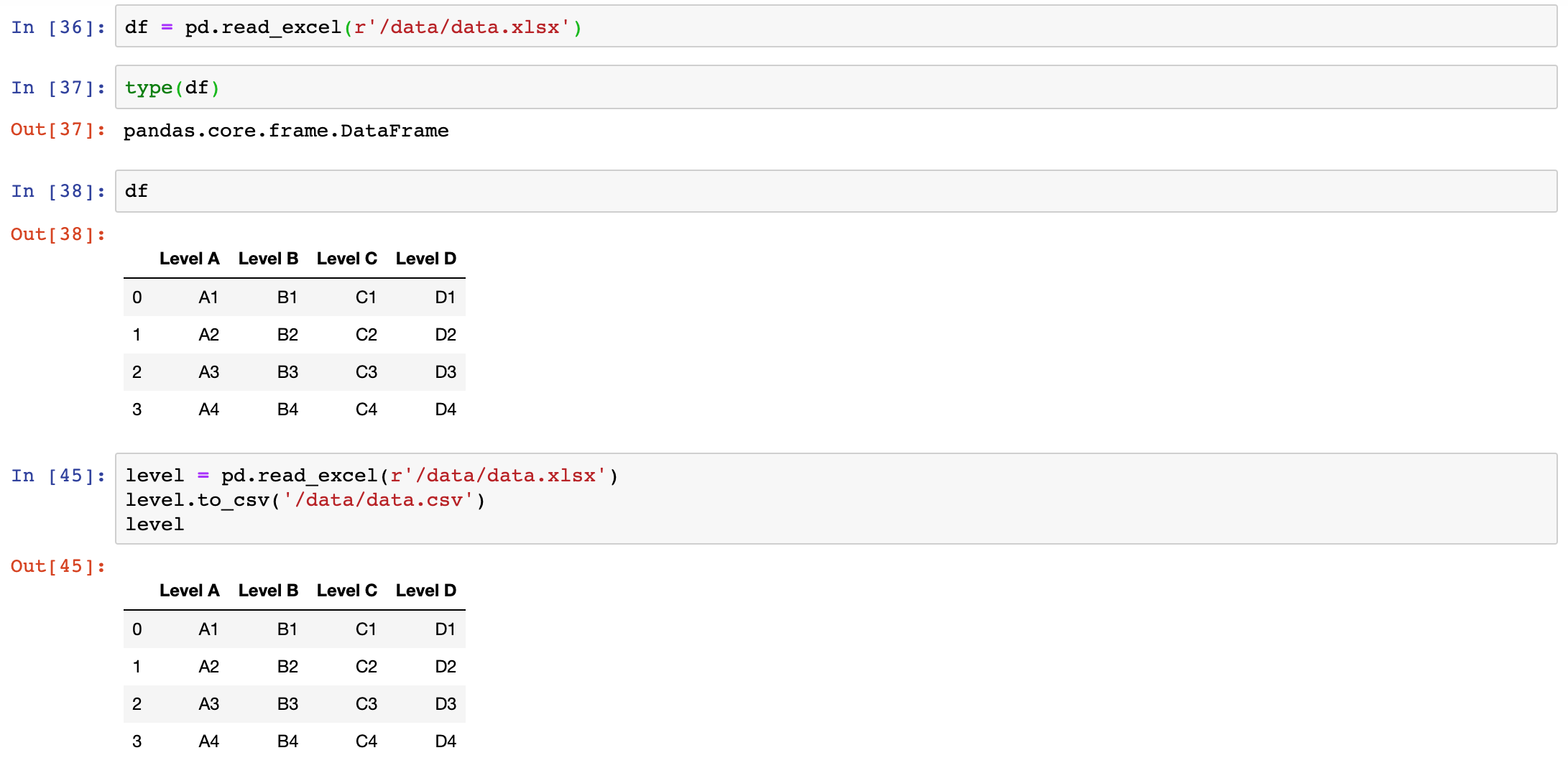
pandas 可以直接从 xlsx,csv 等文件中导入数据,也可以输出到 xlsx, csv 等文件
数据清洗
数据清洗是数据准备过程中必不可少的环节,pandas 也提供了数据清洗的工具,e.g
drop() - 删除 DataFrame 中的不必要的列或行
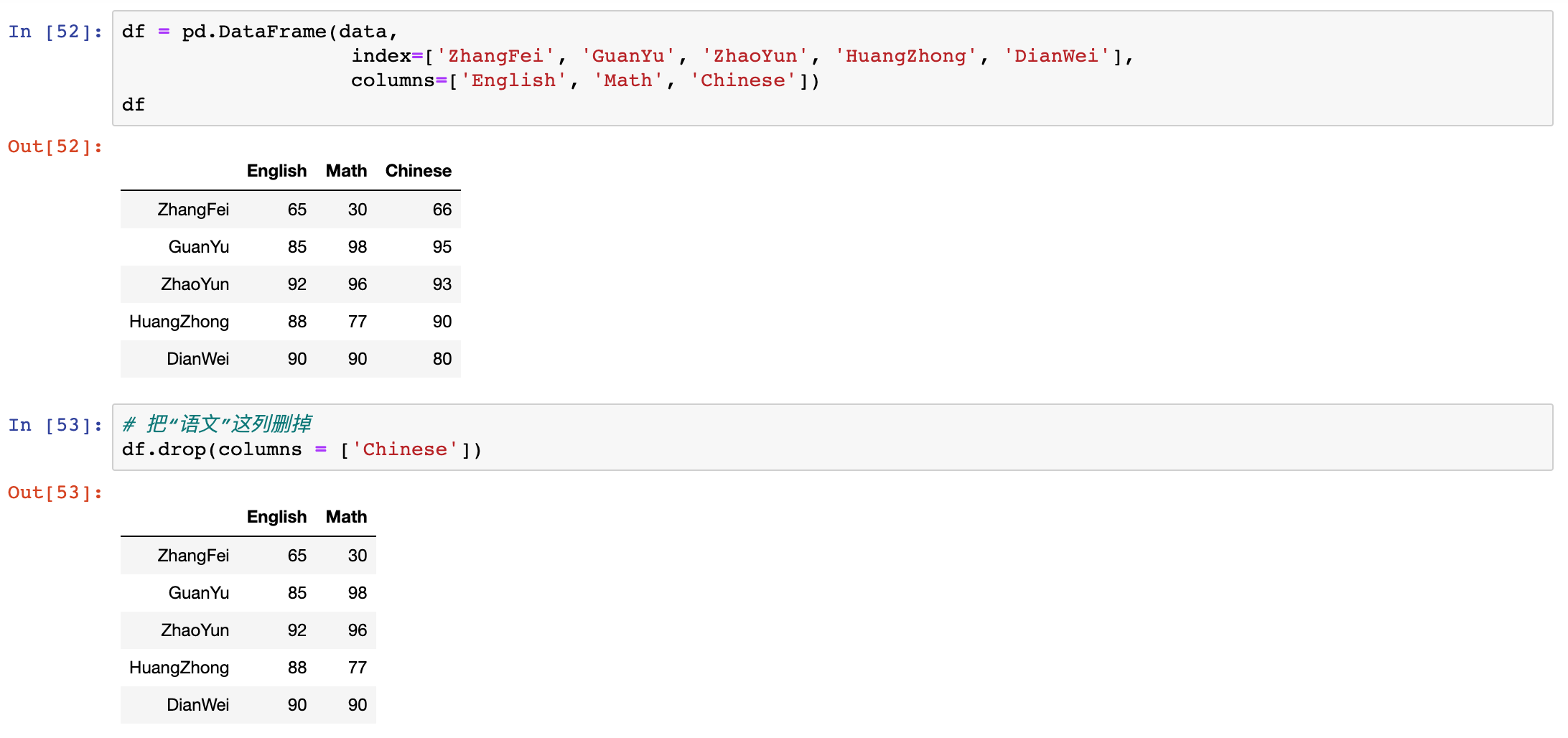

rename(columns=new_names, inplace=True) - 重命名列名 columns

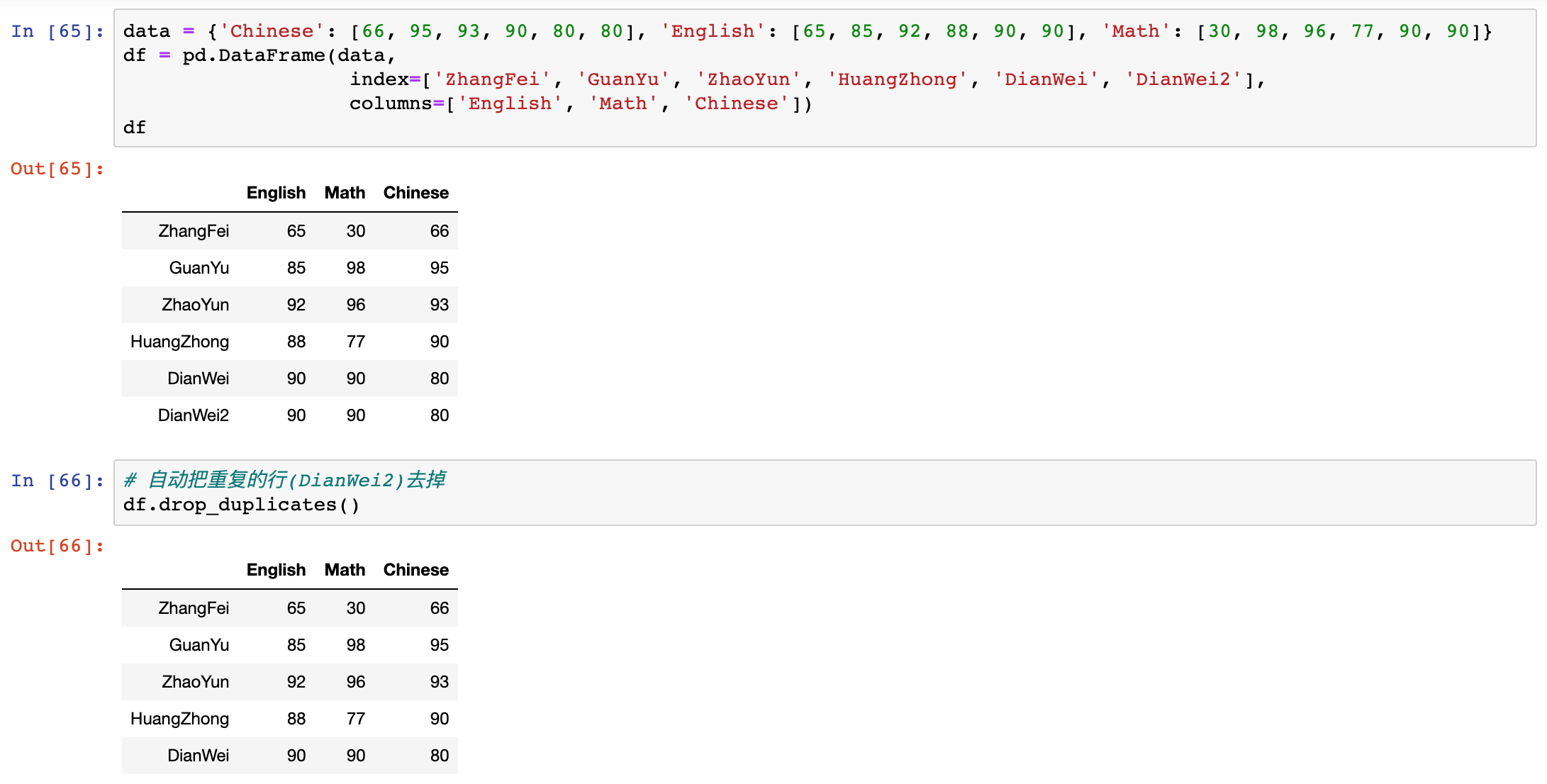
drop_duplicates() - 去重复的行
astype - 更改数据格式
这是个比较常用的操作,因为很多时候数据格式不规范,可以使用 astype 函数来规范数据格式

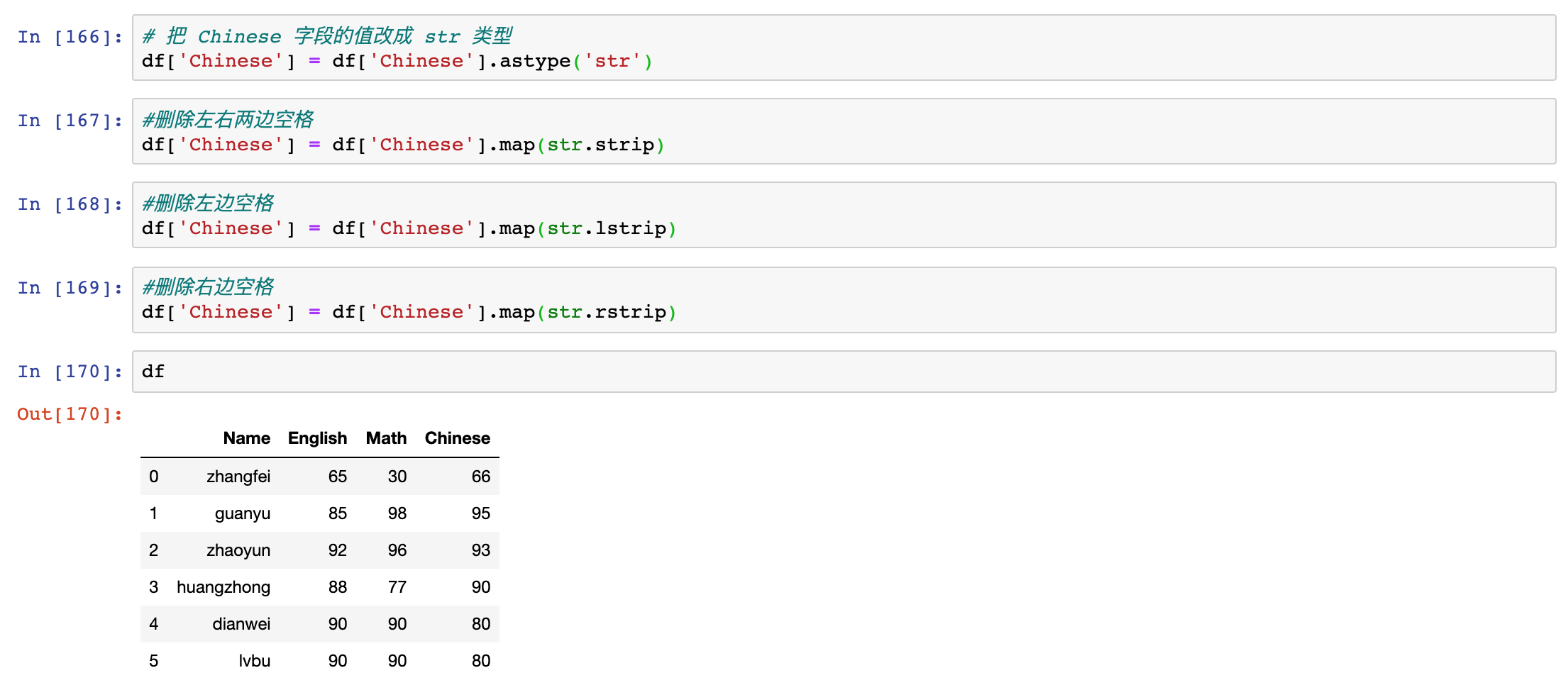
strip - 删除数据间的空格
先把格式转成了 str 类型,是为了方便对数据进行操作,这时想要删除数据间的空格,就可以使用 strip 函数
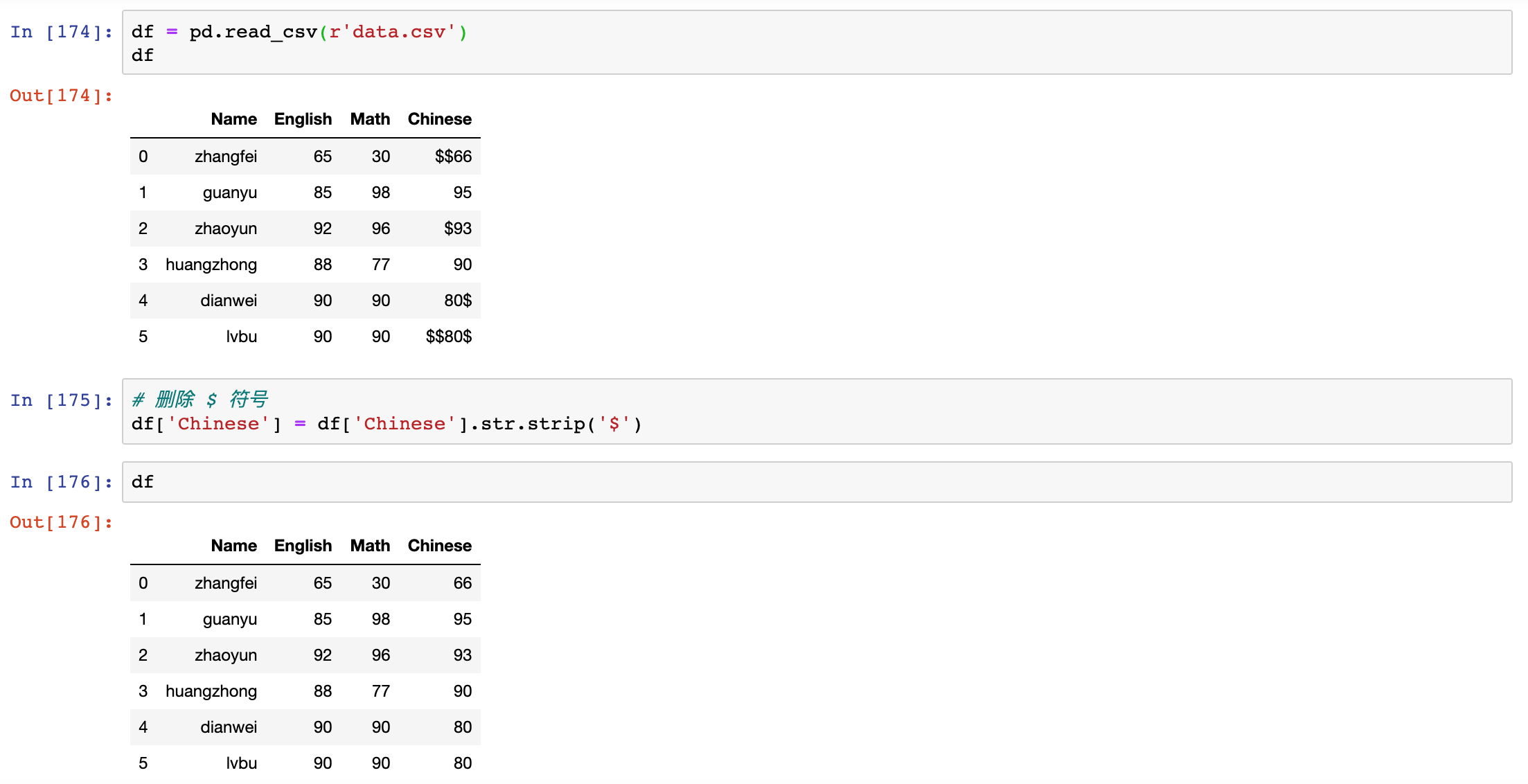
如果数据里有某个特殊的符号,同样可以使用 strip 函数,比如 Chinese 字段里有美元符号
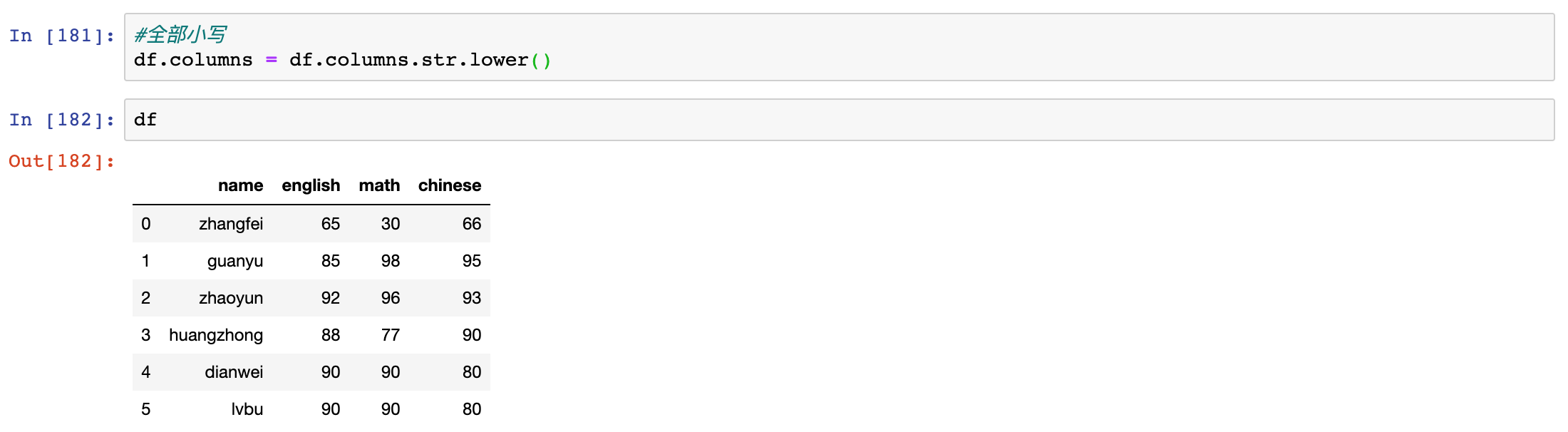
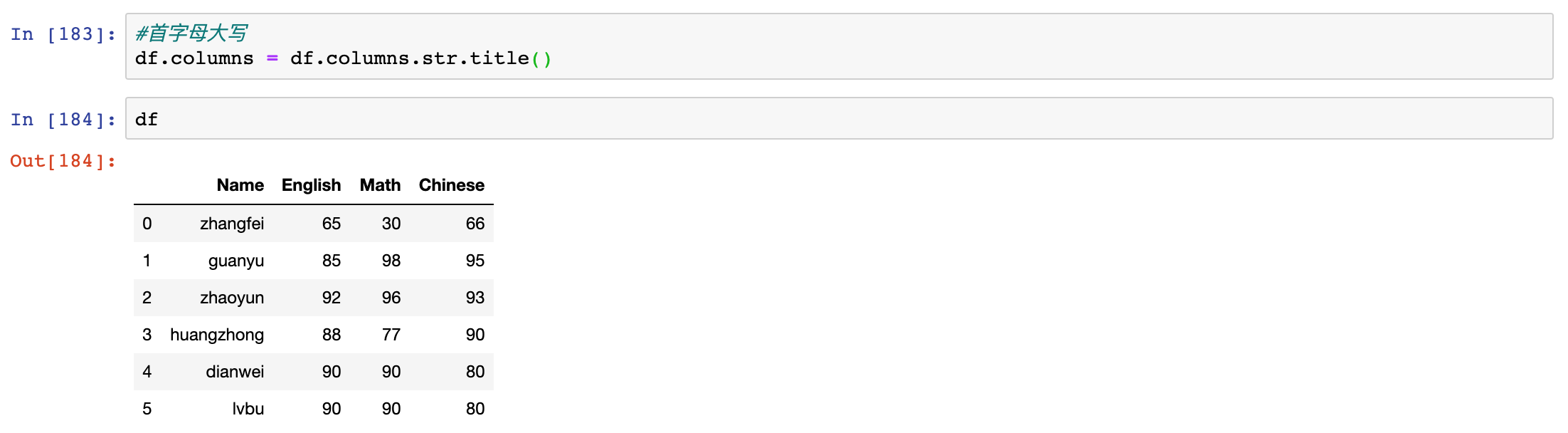
upper(), lower(), title() - 大小写转换

isnull() - 查找空值
如果想查看哪个地方存在空值 NaN,可以针对数据表 df 进行 df.isnull()

如果想查看哪列存在空值,可以使用 df.isnull().any()

Reference
Python for Data Analysis Second Edition
https://pandas.pydata.org/pandas-docs/stable/reference/frame.html
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html