MapReduce和区块链有什么相同的地方?
我的天哪,他俩还有相同的地方呢。我书读的少,你别骗我。
他俩还真有相同点,绝不忽悠。 他俩都有一个高大上的名字。 区块链就是一个分布式数据库,并不是什么神秘的东西。
MR也一样,只不过是一种分而治之的编程思想。官方的定义是:MapReduce是一个实现了处理和生成大数据集的编程模型。
先说一下我从论文里学到的东西吧:
- MR的执行过程,知道了MR慢在哪里
- 怎么容错的,有什么限制
- MR与GFS的联系
- 分片函数怎么玩
- 怎么样撸代码能让MR跑的更快
- MR自己做了什么优化工作
MR的执行过程
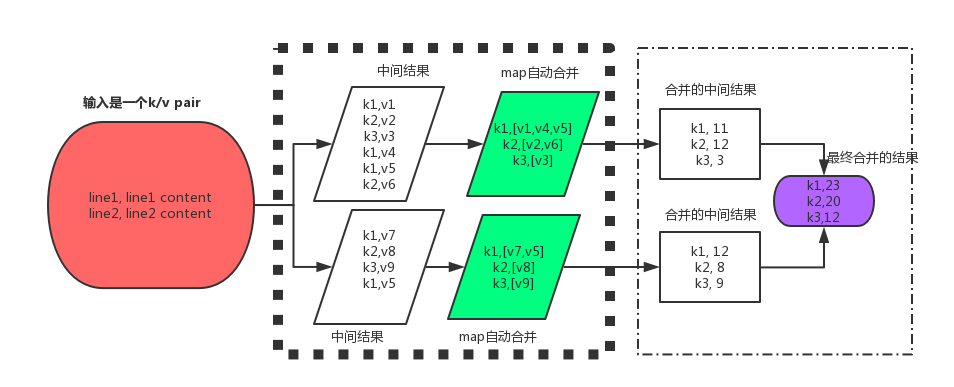
一个键值对分解成多个键值对,多个键值对就是传说中的中间结果。 map会把当前机器的中间结果合并后再传给reduce。reduce再做最后的合并。
问题来了,都是合并,两个合并的动作是一样的吗?
第一次合并是map自动合并的,第二个合并是在reduce里完成的。第二次合并是根据用户的代码来合并的。就是说第二次的合并是用户主动合并的。所以reduce里的合并用户可以按照自己的主观意愿合并,比如合并的时候放弃某些不感兴趣的键值对。当然也可以选择在map阶段就过滤掉这些不感兴趣的键值对。
执行过程拢共分7步(论文直接翻译过来的,注意面试可能会问):
1.MR自动的将输入文件分成M个分片,每个分片16-64MB大小。当然这个大小是可调的。 然后启动每台机器上的用户程序。
2.其中一台机器的程序比较特殊,它是master。master将其它机器指定为worker。需要分配M个map任务和R个reduce任务(一般M是R的几十倍,比如40倍?)
master给闲置的worker分配map任务或者reduce任务。就是说每台worker要么干map的活儿,要么干reduce的活儿。
3.收到map任务的worker读相应的输入分片。从输入文件中读出一个个键值对并将键值对传给用户定义的map函数。map函数将一个键值对变成了很多个键值对,将这些中间结果缓存在内存中。
4.缓存的键值对会定时的写入到本地磁盘。键值对会被partition函数分成R个region。这些缓存在本地磁盘的键值对会传回到master。master负责将这些键值对的位置传给reduce worker。
5.master将位置通知给reduce worker。reduce worker通过RPC去读map worker本地磁盘缓存的数据。读完所有的中间数据后,reduce 会将中间数据的Key进行排序以便于相同的key可以分到同一组里。排序是有必要的,因为许多不同的key会映射到同一个reduce任务里。如果中间数据太多了以至于reduce worker没有足够的内存存放时,就需要外部排序了(数据倒换到磁盘来排序,速度非常慢)。
6.reduce worker遍历每一个排序后的中间数据,将key和相应的values传递给用户写的reduce函数。reduce函数将结果添加到这个reduce分片的输出文件里。
7.当所有的map和reduce任务都完成了,master唤醒用户程序。至此MapReduce的调用结束,程序回到用户代码。
从4,5两步可以看出hadoop的MapReduce慢就慢在:将中间结果放在了本地磁盘里,然后把位置信息发给master,最后reduce worker收到位置信息后直接去读map worker的本地磁盘。写磁盘和读磁盘是很慢的,所以spark出来了。
怎么容错的,有什么限制
这得先了解一下master的数据结构。亲,数据结构了解下。
master保存了几种数据结构。master保存了每一个map和reduce任务的状态(闲置,在运行,已完成)还有非闲置worker机器的标识(identity)。map任务将中间文件区域的位置通过master发送给reduce任务。所以,对于每一个已完成的map任务,master保存了由map任务产生的R个中间文件区域(intermediate file regions)的位置和大小信息。map任务一结束master就会立刻更新这些位置和大小信息。这些信息会递增地推送给正在执行reduce任务的worker。
①worker失败了
master定期地ping每台worker。如果在一段时间内没有收到worker的回应,master将这个worker标记为失败。这台worker上所有已完成的map任务都会
重置到初始状态。类似的,正在处理的map或者reduce任务失败了也会重置到闲置状态以便于master重新调度。
已完成的map任务会在失败之后需要重新执行是因为它们的输出保存在失败的机器的本地磁盘里因此不能被访问到。
已完成的reduce任务不需要重新执行是因为它们的输出保存在全局的文件系统里了(GFS/HDFS)。
一个map任务一开始由worker A执行,失败之后由worker B来执行时,所有正在执行reduce任务的worker被通知重新执行。
此时所有还没有从A读到数据的reduce任务会从B那里读数据。
可以看到map任务失败时代价是很大的,所以尽量不要在map的时候掉(tong)链(lou)子。
MR与GFS的关系也很明显了,就是map的中间结果存放在本地文件系统里,而reduce的结果存放在GFS里。
②master失败了
前面已经描述过master的数据结构,让master周期性的记录这些数据结构的检查点是很容易的。
如果mas任务失败了,可以从最后一个检查点(checkpoint)状态启动一个新的副本。然鹅,考虑到只有一个master,所以不太可能会失败。(一台机器比多台机器简单多了,确实不太容易出问题)。
所以现在的实现方案是:一旦master失败了,直接终止MapReduce计算。客户端可以catch到这种情况,而且如果你需要的话可以重试MapReduce操作。
想想spark的程序,driver部分的代码一旦抛出异常了,整个任务是起不来的。
注意这里有一个问题:
A失败了,由B来顶上。听起来是理所当然的。这有一个前提条件,就是B顶上来的时候,A还是之前的那个A。
什么意思? 这里就引出了算子(operator)的确定性问题。就是论文里“Semantics in the Presence of Failures”这一节内容(这一节很啰嗦,很混人)。
对于同一个输入,每次运算的结果都是一样的,那么称这个算子是确定的。否则就是不确定的。
A失败了,由B来顶上。如果A的算子(map函数)是确定的,那么在B机器上重新执行map操作肯定会产生同样的结果,然后把这个中间结果传递给后续的reduce操作。真可谓移花接木,天衣无缝。 但是如果A的算子不是确定的,在B机器上重新执行map操作的时候可能会产生不同的结果。 这就坏了呀,上一次map输出的是5, 这一次输出的是6, 那么到了reduce那儿,算出的结果就不一样了呀。 当然,如果第二次输出6就是你要的效果,那我没话说了。 或者 6 到了reduce那儿,你的reduce函数仍然能保证算出正确的结果那我也没话可说。
一般情况下,我们肯定希望第二次依然输出5对不对? 怎么避免这个问题呢?
- 要么把map函数定义成确定的函数
- 要么保证A机器绝对不会出问题
所以,我认为容错性是有限制的,取决于你的算子是不是确定的。当然,如果你真的不care第二次输出6(而不是之前的5), 那这也不算是一个限制。
分片函数怎么玩
我们写一个map函数,写一个reduce函数,程序就自动地并行跑起来了,而且还均衡地跑在每台机器上。怎么做到的?
MR默认特供的分片函数是Hash(比如 hash(key) % R)。这个分片策略其实挺均衡的。但是我们也可以自己写分片函数。
比如我们的key是URL。我们想让同一个主机的url输出到同一个文件里。
比如www.baidu开头的url输出到baidu.txt。
www.cnblogs开头的输出到cnblogs.txt里。
我们可以自己写一个分片函数:hash(Hostname(urlkey)) % R。 R是reduce worker的个数。
www.baidu开头的url主机都是baidu, hash之后得到的还是同一个hash值,再跟R进行模运算后得到的还是同一个值。
这样它们就都分配到同一个reduce worker上了。 如果www.baidu开头的url比较多,而这台机器的性能也很强,那么恭喜你,程序会跑的更快。
对了Hostname(urlkey),这里的urlkey是map函数的输入参数,还是map函数的输出参数? 是输出参数,因为partition函数针对的是intermediate key。
怎么样撸代码能让MR跑的更快
这就要引出论文里说都combiner函数了。
map函数产生一大堆中间结果(key, value),然后将这一波数据传给reduce进行合并操作。 这么多数据传递起来很耗时也很占带宽。
能不能在传给reduce之前先合并一部分呢?
可以的。利用Combiner函数就可以做到。 一般combiner函数和reduce函数就是同一个函数。因为干的活都是一样的嘛。那二者有什么区别呢?
区别就是combiner产生的结果是中间数据,跟map的结果一样,存放在worker的本地磁盘里,随后传递给reduce函数。
reduce产生的结果就是最终结果,是存放在GFS里的(前面也提到过,有印象不?)。
MR自己做了什么优化工作
现实中MapReduce执行快要结束时,总是不能干脆利落的一下子结束。
这很好理解。想想我们平时拷贝文件的时候,是不是快要结束的时候总是要卡在那儿一会儿?这是因为繁重的IO操作让磁盘打嗝了。尤其是机械硬盘,频繁读写一段时候后系统就卡的要死。所以MapReduce做了这样一个优化:
在任务快要结束的时候,备份正在执行的任务,主执行或者备份执行一结束就立刻标记为完成。
额,正确性怎么保证的?论文好像没说。
其他的优化比如“本地就近原则”。尽量从当前worker读文件,而不是用RPC从其他worker上读文件。
以上差不多就是论文的全部内容了,还有一些example,示例代码和折线图。这些东西看一遍就可以了。