一、入门
分布式协调服务
单机系统处理能力有上限,可用性、可靠性不能保证。将原来单机的系统拆分为多个应用、多个系统,分别部属到不同的计算节点上,对外来说还是完整的整体。
一个功能现在由多个节点共同完成,环节有先后顺序的要求,需要协调这些节点按一定顺序完成这些任务。原来单机中,多线程需要竞争资源,采用锁等。现在分布式系统中也会发生,需要协调多台计算机中线程的协调,用到分布式锁相关的东西
分布式协调就是分布式系统中,进行顺序的协调,竞争资源的协调。各个分布式系统可用研发自己的协调服务,也可以做成一个独立公共的服务,提供通用的分布式协调服务,各个系统共用。Zookeeper就是这样一种服务。
最早起源于雅虎,Apache Zookeeper是一种用于分布式应用程序的高性能协调服务,提供一种集中式信息存储服务。其设计目标是将复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以简单易用的接口提供给用户使用。具有树形结构的文件系统,zookeeper的功能主要有:发布/订阅,分布式协调/通知,配置管理,集群管理,主从协调,分布式锁等。
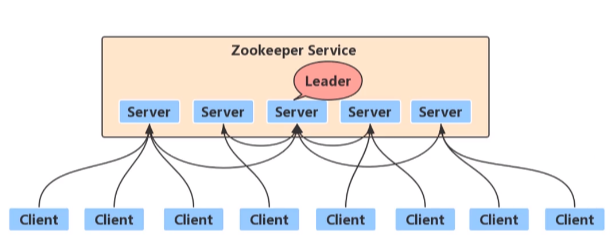
特性
- 最终一致性
- 顺序性,从同一客户端发起的事务请求,最终会严格地按照其发送顺序被应用到zookeeper
- 可靠性,一旦服务器成功的应用一个事务,并完成了客户端的响应,那么该事务所引起的服务端状态变更将会一直保留下去
- 原子性,一次数据更新要么成功要不失败
- 单一视图,无论客户端连接到哪个服务器,看到的数据模型都是一致的
zookeeper应用案例
- Hbase master选举,节点协调
- Solr 集群管理、leader选举、配置管理
- dubbo 服务注册和发现
- Mycat 集群管理,配置管理
- Sharding-sphere 集群管理,配置管理
zookeeper同类产品
consul etcd Doozer
架构
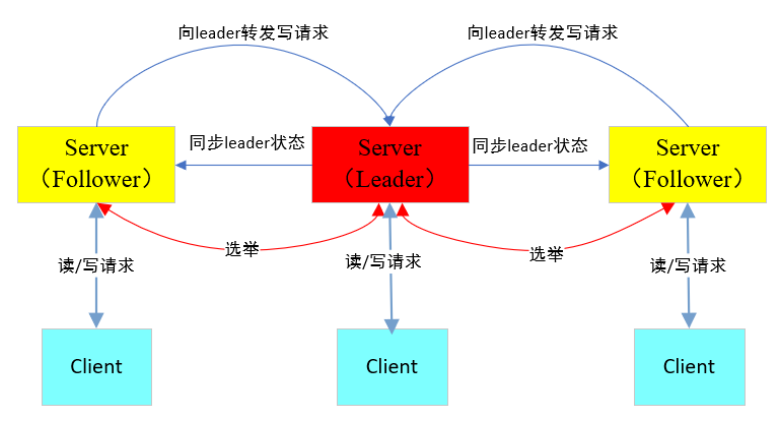
Server端分为Follower和Leader
Leader是事务请求的唯一调度者和处理者,保证集群事务处理的顺序性,是集群内部各服务器的调度者。
Follower将处理客户端非事务请求并向客户端返回结果,将写事务请求转发给Leader,同步Leader的状态,并在选主过程中参与投票。
live_nodes >= total_nodes/2 + 1
Session
一个客户端连接一个会话,由zk分配唯一会话id,客户端以特定的时间间隔发送心跳以保持会话有效,tickTime。超过会话超时时间未收到客户端的心跳,则判定客户端死了,默认两倍tickTime,会话中的请求按FIFO顺序执行。
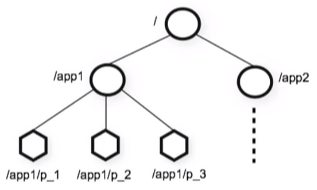
数据模型
- 层次名称空间
- znode
层次名称空间
类似Unix文件系统,以 / 为根,但是zookeeper的节点可以包含与之关联的数据以及子节点,也就是说既是文件也是文件夹。节点的路径总是表示为规范的、绝对的、斜杠分隔的路径。
znode
znode是zookeeper中数据最小单元,znode上可以保存数据,通过挂载子节点构成一个树状的层次化命名空间,znode树的根由“/”斜杠开始。
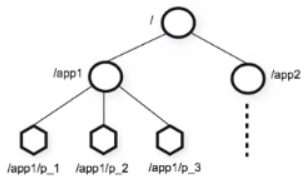
名称唯一,命名规范。
- 节点类型
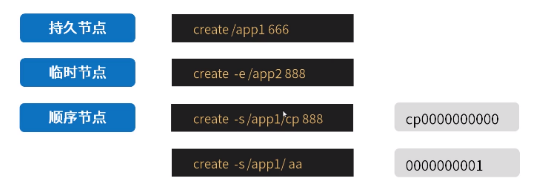
- 持久节点(PERSISTENT)
- 临时节点(EPHEMERAL)
- 顺序节点(SEQUENTAL)
组合节点类型
- 持久节点(PERSISTENT)
- 持久顺序节点(PERSISTENT SEQUENTAL)
- 临时节点(EPHEMERAL)
- 临时顺序节点(EPHEMERAL SEQUENTAL)
客户端与zookeeper连接失效,临时节点会被清理掉,不允许在临时节点下再创建子节点,临时节点只能做为叶子节点。
临时节点的一个应用是:在分布式场景里,分布式系统里经常会涉及主从结构,这个主从结构就会有一个leader,为了保证高可用,一个leader挂掉,还会立马启动新的leader顶替原来的leader,此时就可以用到临时节点
比如,在根目录下创建leader临时节点,还会有有另一个临时节点standby,leader挂掉后,会与zookeeper失去会话,leader这个临时节点会自动被清除掉,standby这个备用节点就可以切换为leader。
10位十进制序号,每个父节点一个计数器,计数器是带符号int(4字节)到2147483647之后将溢出(导致名称“<path>-2147483648”)

znode数据构成
- 节点数据:存储的协调数据(状态信息,配置,位置信息等)
- 节点元数据(stat结构)
- 数据量上限:1M
znode元数据stat结构

zookeeper中的时间
多种方式跟踪时间
- Zxid zookeeper中的每次更改操作都对应一个唯一的事务id,称为Zxid,它是一个全局有序的戳记,如果zxid小于zxid2,则zxid1发生在zxid2之前。
- Version numbers 版本号,对节点的每次更改都会导致该节点的版本号之一增加
- Ticks 当使用多服务器zookeeper时,服务器使用“滴答”来定义事件的时间,如状态上传、会话超时、对等点之间的连接超时等。滴答时间仅通过最小会话超时(滴答时间的2倍)间接公开;如果客户端请求的会话超时小于最小会话超时,服务器将告诉客户端会话超时实际是最小会话超时。
- Real time zookeeper除了在znode创建和修改时将时间戳放入stat结构之外,根本不使用Real time或时钟时间
Watch监听机制
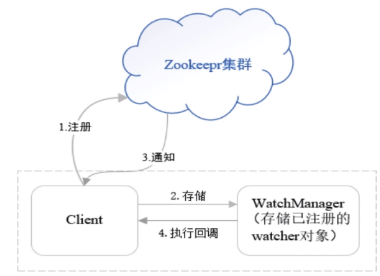
客户端可以在znodes上设置watch,监听znode的变化
客户端向zookeeper监听znode,在注册监听事件的同时,将监听对象(watcher对象)存储到WatchManager里,即当znode发生变化或有一些其他事件触发监听的时候,因为客户端在监听znode的变化,只要znode在触发监听事件之后就会向客户端发送通知,客户端线程就可以从WatchManager这个对象里获取到对应的Watcher对象,来执行一个对应的回调逻辑,即根据监听到的事件做一定的处理。
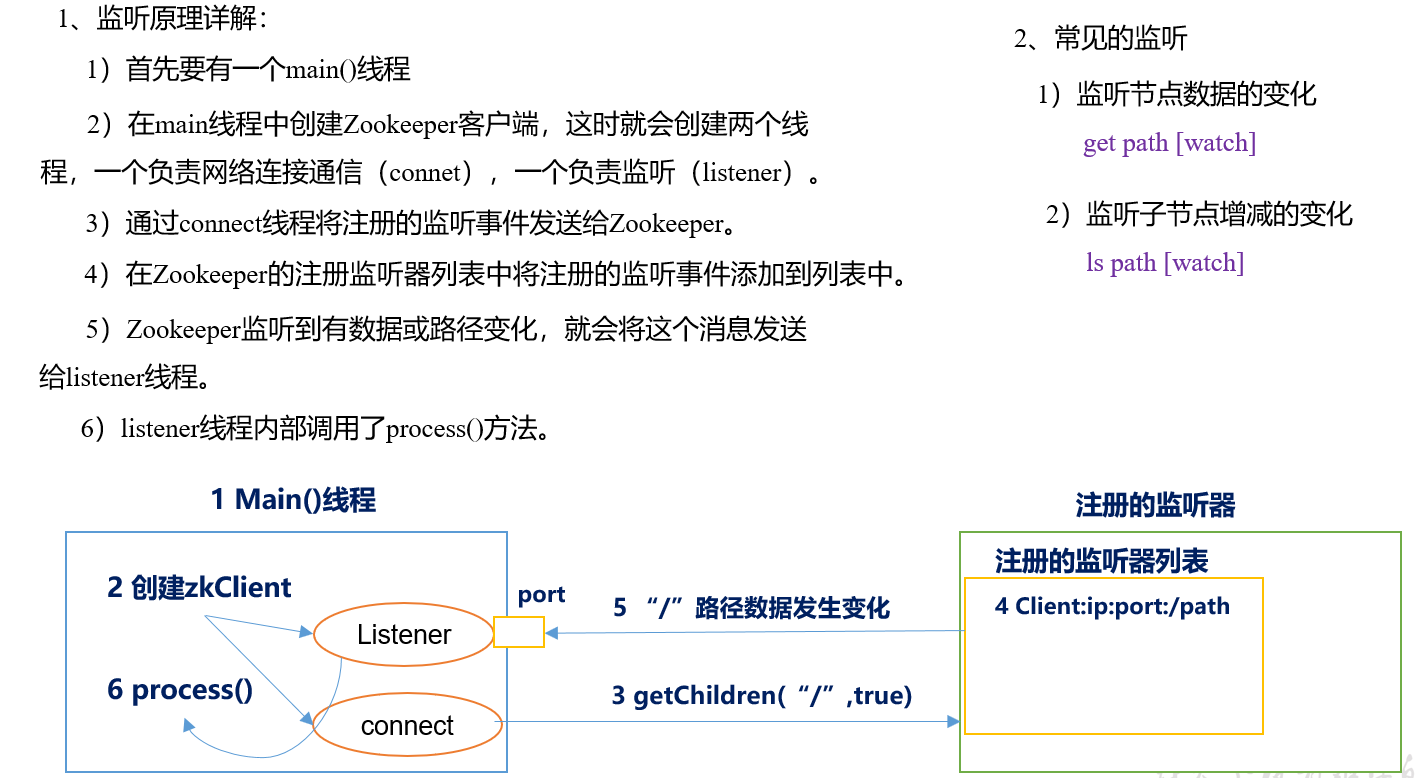

两类watch
- data watch 监听数据变更
- child watch 监听子节点变化
触发watch事件
- Created event Enabled with a call to exists
- Deleted event Enabled with a call exits,getData, and getChildren
- Changed event Enabled with a call to exisits and getData
- Child event Enabled with a call to getChildren
watch重要特性
- 一次性触发,watch触发后即被删除,要持续监控变化,则需要持续设置watch
- 有序性,客户端先得到watch通知,后才会看到变化结构
因为watch一次性,并且在获取事件和发送获取watch的新请求之间存在延迟,所以不能可靠地得到节点发生的每隔更改。
CLI操作指令
进入客户端
bin/zkCli.sh
CDH版本
[root@node01 bin]# pwd /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/bin [root@node01 bin]# zookeeper-client Connecting to localhost:2181 2020-03-09 13:52:13,297 [myid:] - INFO [main:Environment@100] - Client environment:zookeeper.version=3.4.5-cdh6.3.1--1, built on 09/26/2019 09:28 GMT 2020-03-09 13:52:13,300 [myid:] - INFO [main:Environment@100] - Client environment:host.name=node01 2020-03-09 13:52:13,300 [myid:] - INFO [main:Environment@100] - Client environment:java.version=1.8.0_241 2020-03-09 13:52:13,302 [myid:] - INFO [main:Environment@100] - Client environment:java.vendor=Oracle Corporation 2020-03-09 13:52:13,302 [myid:] - INFO [main:Environment@100] - Client environment:java.home=/usr/java/jdk1.8.0_241/jre ...
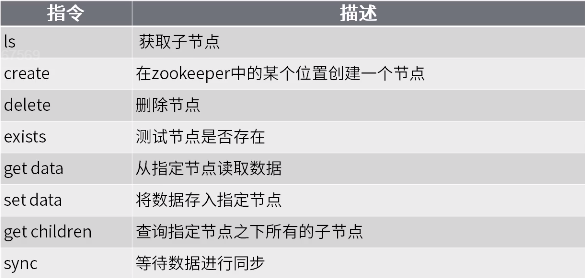
查看当前节点中所包含的内容:
ls /
查看当前节点内容和详细信息:
ls2 /
获取节点的值:
get /节点名
创建普通节点:
create /ys ysjh0014.cn
创建短暂节点:
create -e /ys ysjh0014.cn
使用quit退出客户端后该节点就会被删除
创建带序号的节点:
[zk: localhost:2181(CONNECTED) 10] create -s /zktest 1 Created /zktest0000000039 [zk: localhost:2181(CONNECTED) 12] ls / [cluster,zktest0000000039, controller_epoch, consumers, config, hbase] [zk: localhost:2181(CONNECTED) 13] create -s /zktest/ 1 Created /zktest/0000000002 [zk: localhost:2181(CONNECTED) 14] ls /zktest [0000000002, s1, s2]
修改节点数据:
set /csdn 666
删除节点:
delete /csdn
递归删除节点:(递归删除所有的节点,包括子节点)
rmr /csdn
查看节点状态:
stat /csdn
监听节点值的变化:
get /ys/jh watch
这里只要这个节点值变化,就会得到相应,但是只能有一次响应,即节点值改变一次之后就不会再监听
监听节点的子节点变化(路径变化)
ls /path watch
只要路径变化就会相应,同样的只会响应一次
查看节点状态:
stat /csdn
二、集群
ZAB协议
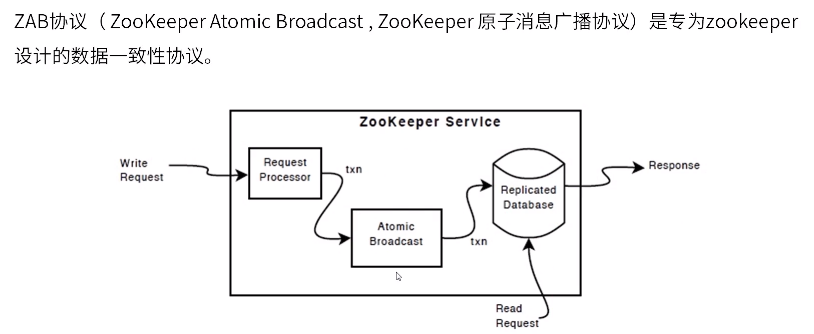

ZAB协议需要设计的选举算法应满足:确保提交已经被leader提交的事务Proposal,同时丢弃已经被跳过的事务Proposal
- 如果让leader选举算法能够保证新选举出来的leader服务器拥有集群中所有机器最高ZXID的事务Proposal,那么就可以保证这个选举出来的leader一定具有所有已经提交提案。
- 如果让具有最高编号事务Proposal的机器来成为leader,就可以省去leader服务器检查Proposal的提交和丢弃工作的这一步操作。
数据同步
leader选举出来后,需完成followers与leader的数据同步,当半数的followers完成同步,则可以开始提供服务,同步的过程如下:
- leader服务器会为每一个follower服务器都准备一个队列,并将那些没有被各follower服务器同步的事务以Proposal消息的形式逐个发送给follower服务器,并在每一个proposal消息后面紧接着再发送一个Commit消息,以表示该事务已经被提交。
- follower服务器将所有尚未同步的事务Proposal都从leader服务器上同步过来并成功应用到本地数据库中后,leader服务器就会将该follower服务器加入到真正的可用follower列表中,并开始之后的其他流程
丢弃事务Proposal处理
- 低32位是一个简单的单调递减的计数器,针对客户端的每一个事务请求,leader服务器在产生一个新的事务Proposal的时候,都会对该计数器进行加1操作
- 高32位代表了leader周期纪元的编号,每当选举产生一个新的leader服务器,就会从这个leader服务器上取出其本地日志中最大事务Proposal的ZXID,并从该ZXID中解析出对应的纪元值,然后对其进行加1操作,之后就会以此编号作为新的纪元,并将低32位置0来开始生成新的ZXID
基于这样的策略,当一个包含了上一个leader周期中尚未提交过的事务Proposal的服务器启动加入到集群中,发现此时集群中已经存在leader,将自身以follower角色连接上leader服务器之后,leader服务器会根据自己服务器上最后被提交的Proposal来和follower服务器的Proposal进行对比,发现follower中有上一个leader周期的事务Proposal时,leader会要求follower进行一个回退操作,回退到一个确实已经被集群中过半机器提交的最新的事务Proposal。
写数据流程
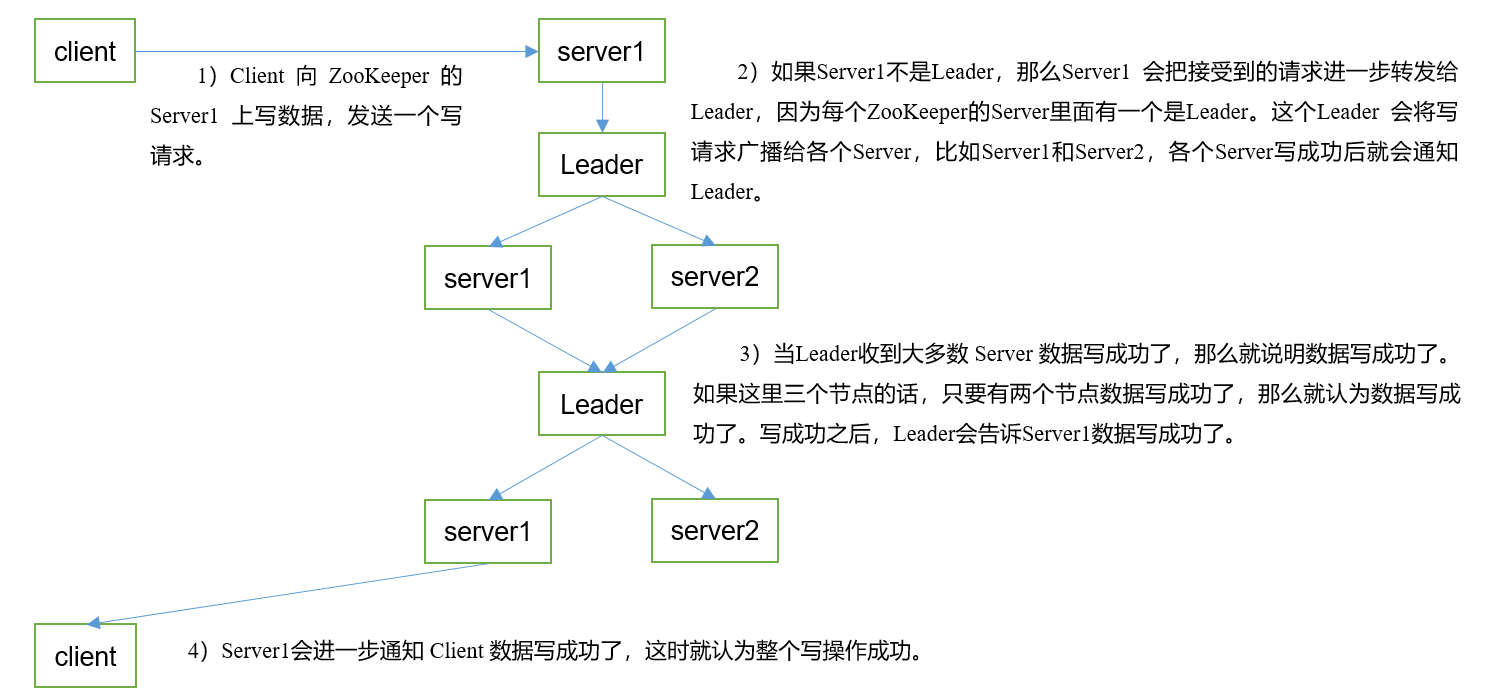
全新启动集群Leader的选举
对选举算法的要求
- 选出的leader节点上要持有最高的zxid
- 过半数节点同意
内置实现的选举算法:
- LeaderElection
- FastLeaderElection(默认)
- AuthFastLeaderElection

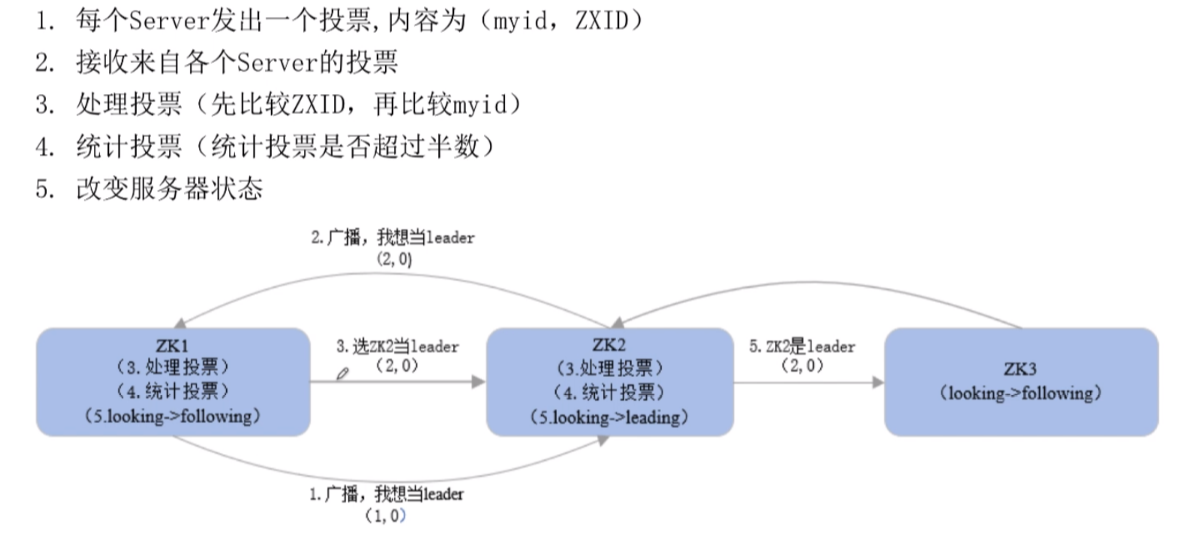
最少三台机器才能保证zookeeper的安全平稳运行
每个服务器需要在myid的配置文件里添加一个全局唯一的数字编号
每台服务器都要由myid这一配置文件,在配置文件里会输入一些数字编号,通常输入12345等阿拉伯数字
zk1启动时,只有一台机器没法进行选举,等待第二台机器启动
zk2启动时,整个集群进入选举状态
zk1和zk2都处于looking状态,开始投票
投票时,每台机器都 会向集群广播一条它投票的消息
投票的消息包含的内容,一个是myid,一个是事务id
因为是全新的集群,事务id设为0,myid在myid配置文件里
启动时,每个节点都选举自己
zk1发送(1,0)
zk2发送(2,0)
zk1接收到了zk2的投票,zk2接收到了zk1的投票,开始处理投票
处理投票原则:先比较事务id,再比较myid,大的为leader
zk1先比较事务id,相等,再比较myid,发现zk2比较大,更新自己的投票为(2,0)
同理,zk2发现自己myid比较大,忽略zk1的投票,坚持自己为leader,再次向集群发送投票信息为(2,0)
每次投票之后,服务器都会根据所有的投票判断是否有过半的机器接收到相同的投票信息,过半是指大于集群机器数量的一半
此时,zk1和zk2都选择zk2为leader,超过了集群机器数量的一半,zk2被成功选举为leader
一旦选举出leader,每个服务器都会更新自己的状态
zk1会从looking切换为following
zk2会从looking切换为leading
zk3再启动,发现已经有leader,zk3会从zk2这个leader更新数据,从looking切换为following
整个集群选举结束
5台服务器的例子

集群搭建
三节点
集群规划
在hadoop102、hadoop103和hadoop104三个节点上部署Zookeeper。
解压安装
(1)解压Zookeeper安装包到/opt/module/目录下
[root@hadoop102 software]$ tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/module/
(2)同步/opt/module/zookeeper-3.4.10目录内容到hadoop103、hadoop104
[root@hadoop102 module]$ xsync zookeeper-3.4.10/
配置服务器编号
(1)在/opt/module/zookeeper-3.4.10/这个目录下创建zkData
[root@hadoop102 zookeeper-3.4.10]$ mkdir -p zkData
(2)在/opt/module/zookeeper-3.4.10/zkData目录下创建一个myid的文件
[root@hadoop102 zkData]$ touch myid
添加myid文件,注意一定要在linux里面创建,在notepad++里面很可能乱码
(3)编辑myid文件
[root@hadoop102 zkData]$ vi myid
在文件中添加与server对应的编号 2
(4)拷贝配置好的zookeeper到其他机器上
[root@hadoop102 zkData]$ xsync myid
并分别在hadoop102、hadoop103上修改myid文件中内容为3、4
配置zoo.cfg文件
(1)重命名/opt/module/zookeeper-3.4.10/conf这个目录下的zoo_sample.cfg为zoo.cfg
[root@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg
(2)打开zoo.cfg文件
[root@hadoop102 conf]$ vim zoo.cfg
修改数据存储路径配置
dataDir=/opt/module/zookeeper-3.4.10/zkData
增加如下配置
#######################cluster########################## server.2=hadoop102:2888:3888 server.3=hadoop103:2888:3888 server.4=hadoop104:2888:3888
(3)同步zoo.cfg配置文件
[root@hadoop102 conf]$ xsync zoo.cfg
(4)配置参数解读
server.A=B:C:D。
A是一个数字,表示这个是第几号服务器;
集群模式下配置一个文件myid,这个文件在dataDir目录下,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
B是这个服务器的ip地址;
C是这个服务器与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
集群操作
(1)分别启动Zookeeper
[root@hadoop102 zookeeper-3.4.10]$ bin/zkServer.sh start [root@hadoop103 zookeeper-3.4.10]$ bin/zkServer.sh start [root@hadoop104 zookeeper-3.4.10]$ bin/zkServer.sh start
(2)查看状态
[root@hadoop102 zookeeper-3.4.10]# bin/zkServer.sh status JMX enabled by default Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg Mode: follower [root@hadoop103 zookeeper-3.4.10]# bin/zkServer.sh status JMX enabled by default Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg Mode: leader [root@hadoop104 zookeeper-3.4.5]# bin/zkServer.sh status JMX enabled by default Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg Mode: follower

id在集群中必须是唯一的,其值应在1到255之间。
常用服务命令
1. 启动ZK服务: bin/zkServer.sh start
2. 查看ZK服务状态: bin/zkServer.sh status
3. 停止ZK服务: bin/zkServer.sh stop
4. 重启ZK服务: bin/zkServer.sh restart
5. 连接服务器: zkCli.sh -server 127.0.0.1:2181
集群监控

三、应用
API应用
在ZooKeeper中,接口类Watcher用于表示一个标准的事件处理器,其定义了事件通知相关的逻辑,包含KeeperState和EventType两个枚举类,分别代表了通知状态和事件类型,同时定义了事件的回调方法:process(WatchedEvent event)。
process方法是Watcher接口中的一个回调方法,当ZooKeeper向客户端发送一个Watcher事件通知时,客户端就会对相应的process方法进行回调,从而实现对事件的处理。process方法的定义如下:
abstract public void process(WatchedEvent event);
这个回调方法的定义非常简单,我们重点看下方法的参数定义:WatchedEvent。
WatchedEvent包含了每一个事件的三个基本属性:通知状态(keeperState),事件类型(EventType)和节点路径(path)。ZooKeeper使用WatchedEvent对象来封装服务端事件并传递给Watcher,从而方便回调方法process对服务端事件进行处理。
提到WatchedEvent,不得不讲下WatcherEvent实体。笼统地讲,两者表示的是同一个事物,都是对一个服务端事件的封装。不同的是,WatchedEvent是一个逻辑事件,用于服务端和客户端程序执行过程中所需的逻辑对象,而WatcherEvent因为实现了序列化接口,因此可以用于网络传输。
服务端在生成WatchedEvent事件之后,会调用getWrapper方法将自己包装成一个可序列化的WatcherEvent事件,以便通过网络传输到客户端。客户端在接收到服务端的这个事件对象后,首先会将WatcherEvent还原成一个WatchedEvent事件,并传递给process方法处理,回调方法process根据入参就能够解析出完整的服务端事件了。
需要注意的一点是,无论是WatchedEvent还是WatcherEvent,其对ZooKeeper服务端事件的封装都是机及其简单的。举个例子来说,当/zk-book这个节点的数据发生变更时,服务端会发送给客户端一个“ZNode数据内容变更”事件,客户端只能够接收到如下信息:
keeperState:SyncConnected
EventType:NodeDataChanged
Path:/zk-book
从上面展示的信息中我们可以看到,客户端无法直接从该事件中获取到对应数据节点的原始数据内容以及变更后的新数据内容,而是需要客户端在此主动去重新获取数据——这也是ZooKeeper Watcher机制的一个非常重要的特性。
getChildren()方法仅仅监控对应节点直接子目录的一次变化,但是只会监控直接子节点的增减情况,不会监控数据变化情况!若要每次对应节点发生增减变化都被监测到,那么每次都得先调用getChildren()方法获取一遍节点的子节点列表!
示例
新建maven项目,配置pom文件
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.zookeeper/zookeeper -->
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.10</version>
</dependency>
</dependencies>
拷贝log4j.properties文件到项目根目录
需要在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入。
log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
创建zookeeper客户端
private static String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181"; private static int sessionTimeout = 2000; private ZooKeeper zkClient = null; @Before public void init() throws Exception { zkClient = new ZooKeeper(connectString, sessionTimeout, new Watcher() { @Override public void process(WatchedEvent event) { // 收到事件通知后的回调函数(用户的业务逻辑) System.out.println(event.getType() + "--" + event.getPath()); // 再次启动监听 try { zkClient.getChildren("/", true); } catch (Exception e) { e.printStackTrace(); } } }); }
创建子节点
// 创建子节点 @Test public void create() throws Exception { // 参数1:要创建的节点的路径; 参数2:节点数据 ; 参数3:节点权限 ;参数4:节点的类型 String nodeCreated = zkClient.create("/atguigu", "jinlian".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); }
获取子节点并监听变化
// 获取子节点 @Test public void getChildren() throws Exception { List<String> children = zkClient.getChildren("/", true); for (String child : children) { System.out.println(child); } // 延时阻塞 Thread.sleep(Long.MAX_VALUE); }
判定znode是否存在
// 判断znode是否存在 @Test public void exist() throws Exception { Stat stat = zkClient.exists("/eclipse", false); System.out.println(stat == null ? "not exist" : "exist"); }
监听服务器节点动态上下线案例
1.需求
某分布式系统中,主节点可以有多台,可以动态上下线,任意一台客户端都能实时感知到主节点服务器的上下线。
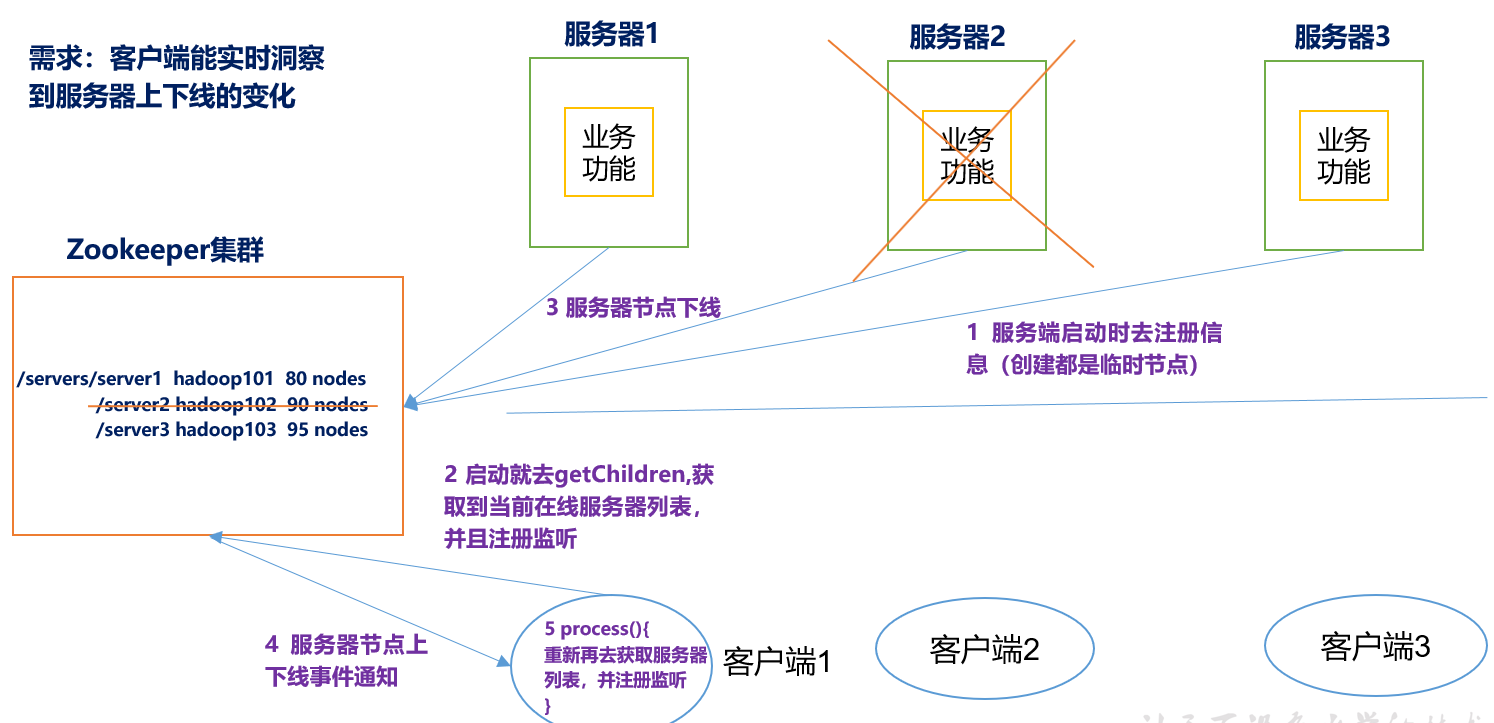
具体实现
在服务器端和客户端都创建zookeeper的client,其中服务端创建暂时的节点,如果服务端挂了,则其zookeeper client会退出,从而暂时节点会从zookeeper集群中消失,客户的zookeeper client会收到监听通知。
(0)先在集群上创建/servers节点
[zk: localhost:2181(CONNECTED) 10] create /servers "servers"
Created /servers
(1)服务器端向Zookeeper注册代码
package com.aidata.zkcase; import java.io.IOException; import org.apache.zookeeper.CreateMode; import org.apache.zookeeper.WatchedEvent; import org.apache.zookeeper.Watcher; import org.apache.zookeeper.ZooKeeper; import org.apache.zookeeper.ZooDefs.Ids; public class DistributeServer { private static String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181"; private static int sessionTimeout = 2000; private ZooKeeper zk = null; private String parentNode = "/servers"; // 创建到zk的客户端连接 public void getConnect() throws IOException{ zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() { @Override public void process(WatchedEvent event) { } }); } // 注册服务器 public void registServer(String hostname) throws Exception{ String create = zk.create(parentNode + "/server", hostname.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL); System.out.println(hostname +" is online "+ create); } // 业务功能 public void business(String hostname) throws Exception{ System.out.println(hostname+" is working ..."); Thread.sleep(Long.MAX_VALUE); } public static void main(String[] args) throws Exception { // 1获取zk连接 DistributeServer server = new DistributeServer(); server.getConnect(); // 2 利用zk连接注册服务器信息 server.registServer(args[0]); // 3 启动业务功能 server.business(args[0]); } }
(2)客户端代码
package com.aidata.zkcase; import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.apache.zookeeper.WatchedEvent; import org.apache.zookeeper.Watcher; import org.apache.zookeeper.ZooKeeper; public class DistributeClient { private static String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181"; private static int sessionTimeout = 2000; private ZooKeeper zk = null; private String parentNode = "/servers"; // 创建到zk的客户端连接 public void getConnect() throws IOException { zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() { @Override public void process(WatchedEvent event) { // 再次启动监听 try { getServerList(); } catch (Exception e) { e.printStackTrace(); } } }); } // 获取服务器列表信息 public void getServerList() throws Exception { // 1获取服务器子节点信息,并且对父节点进行监听 List<String> children = zk.getChildren(parentNode, true); // 2存储服务器信息列表 ArrayList<String> servers = new ArrayList<>(); // 3遍历所有节点,获取节点中的主机名称信息 for (String child : children) { byte[] data = zk.getData(parentNode + "/" + child, false, null); servers.add(new String(data)); } // 4打印服务器列表信息 System.out.println(servers); } // 业务功能 public void business() throws Exception{ System.out.println("client is working ..."); Thread.sleep(Long.MAX_VALUE); } public static void main(String[] args) throws Exception { // 1获取zk连接 DistributeClient client = new DistributeClient(); client.getConnect(); // 2获取servers的子节点信息,从中获取服务器信息列表 client.getServerList(); // 3业务进程启动 client.business(); } }
另一个较完整的例子
| KeeperState | EventType | 触发条件 | 说明 |
| None (-1) |
客户端与服务端成功建立连接 | ||
| SyncConnected (0) |
NodeCreated (1) |
Watcher监听的对应数据节点被创建 | |
| NodeDeleted (2) |
Watcher监听的对应数据节点被删除 | 此时客户端和服务器处于连接状态 | |
| NodeDataChanged (3) |
Watcher监听的对应数据节点的数据内容发生变更 | ||
| NodeChildChanged (4) |
Wather监听的对应数据节点的子节点列表发生变更 | ||
| Disconnected (0) |
None (-1) |
客户端与ZooKeeper服务器断开连接 | 此时客户端和服务器处于断开连接状态 |
| Expired (-112) |
Node (-1) |
会话超时 | 此时客户端会话失效,通常同时也会受到SessionExpiredException异常 |
| AuthFailed (4) |
None (-1) |
通常有两种情况,1:使用错误的schema进行权限检查 2:SASL权限检查失败 | 通常同时也会收到AuthFailedException异常 |
下面的watcher中使用了上面的事件类型
package bigdata.zookeeper; import org.apache.zookeeper.*; import org.apache.zookeeper.data.Stat; import java.io.IOException; import java.util.List; import java.util.concurrent.CountDownLatch; public class ZookeeperClient { private static String connectString = "node01:2181,node02:2181,node03:2181"; private static int sessionTimeout = 5000; private static ZooKeeper zk = null; private static CountDownLatch countDownLatch = new CountDownLatch(1); private static Stat stat = new Stat(); public static void getConn() throws IOException { //String connectString, int sessionTimeout, Watcher watcher zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() { @Override public void process(WatchedEvent event) { //作用:客户端接收服务端发送的监听通知事件 System.out.println("收到监听通知!"); System.out.println("type:" + event.getType() + ",path:" + event.getPath()); if(event.getState() == Event.KeeperState.SyncConnected){ //注意:客户端向服务端注册的Watcher是一次性的,一旦服务端向客户端发送一次通知后,这个Watcher失效, // 客户端需要反复注册Watcher //服务端向客户端发送成功建立连接的通知 try { if(event.getType() == Event.EventType.None && event.getPath() == null){ System.out.println("Zookeeper客户端与服务端成功建立连接!"); countDownLatch.countDown(); }else if(event.getType() == Event.EventType.NodeChildrenChanged){ System.out.println("通知:" + event.getPath() + "节点的子节点发生变化!"); ZookeeperClient.getChildrenNodes(event.getPath(),true); }else if(event.getType() == Event.EventType.NodeDataChanged){ System.out.println("通知:" + event.getPath() + "节点数据发生变化!"); ZookeeperClient.getZnodeData(event.getPath(),true);//重新注册监听事件 }else if(event.getType() == Event.EventType.NodeCreated){ System.out.println("通知:" + event.getPath() + "节点被创建"); ZookeeperClient.existsZnode(event.getPath(),true);//重新注册监听事件 }else if(event.getType() == Event.EventType.NodeDeleted){ System.out.println("通知:" + event.getPath() + "节点被删除"); ZookeeperClient.existsZnode(event.getPath(),true);//重新注册监听事件 } } catch (KeeperException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } } } }); } //创建节点 public static void createZnode(String path, byte[] data, CreateMode createMode) throws KeeperException, InterruptedException { if(zk != null){ //String path:znode路径 //byte[] data:znode值 //List<ACL> acl:znode访问权限 //CreateMode createMode:znode类型 zk.create(path,data, ZooDefs.Ids.OPEN_ACL_UNSAFE,createMode); } } //获取节点下所有子节点 public static void getChildrenNodes(String path,boolean watch) throws KeeperException, InterruptedException { if(zk != null){ List<String> children = zk.getChildren(path,watch); System.out.println(path + "节点的所有子节点:" + children); } } //获取节点数据 public static void getZnodeData(String path,boolean watch) throws KeeperException, InterruptedException { if(zk != null){ //String path:节点路径 //boolean watch:是否注册监听事件 //Stat stat:节点状态信息对象 byte[] data = zk.getData(path,watch,stat); System.out.println("获取到的" + path + "节点数据:" + new String(data)); System.out.println("czxid:" + stat.getCzxid() + ",mzxid:" + stat.getMzxid()); } } //更新节点数据 public static Stat setZnodeData(String path,byte[] data,int version) throws KeeperException, InterruptedException { Stat stat1 = null; if(zk != null){ //String path:节点路径 //byte[] data:待更新数据 //int version:更新的数据版本号(dataVersion),version=-1表示基于znode最新的版本号进行更新 // version从0开始,更新操作传入的版本号要与节点最新的数据版本号一致,否则更新失败 stat1 = zk.setData(path,data,version); System.out.println(path + "节点信息:czxid=" + stat1.getCzxid() + ",mzxid=" + stat1.getMzxid() + ",dataVersion=" + stat1.getVersion()); } return stat1; } //删除节点 public static void deleteZnode(String path,int version) throws KeeperException, InterruptedException { if(zk != null){ //String path:删除的节点路径 //int version:要删除的节点的版本号 //只允许删除叶子节点,不能删除带有子节点的嵌套节点 zk.delete(path,version); //delete命令 System.out.println("已删除" + path + "节点!"); } } //检查节点是否存在 public static void existsZnode(String path,boolean watch) throws KeeperException, InterruptedException { if(zk != null){ //String path:待检查节点路径 //boolean watch:是否注册监听事件 Stat statrs = zk.exists(path,watch); if(statrs == null){ System.out.println(path + "节点不存在!"); } } } public static void main(String[] args){ try { ZookeeperClient.getConn(); System.out.println("当前连接状态:" + zk.getState()); countDownLatch.await(); //等待服务端向客户端发送成功建立连接的通知 //1)创建znode节点 //注意:创建同名节点会抛出异常NodeExistsException: KeeperErrorCode = NodeExists for /zk-test1 //String path = "/zk-test1"; //ZookeeperClient.createZnode(path,"hello zktest1".getBytes(),CreateMode.PERSISTENT); //注意:不能够创建包含子节点的嵌套节点NoNodeException: KeeperErrorCode = NoNode for /zk-test2/temp1 // String path = "/zk-test2/temp1"; // ZookeeperClient.createZnode(path,"000".getBytes(),CreateMode.PERSISTENT); //2)获取节点下的所有子节点 //ZookeeperClient.getChildrenNodes("/zk-test1",true); //ZookeeperClient.createZnode("/zk-test1/tmp1","hello tmp1".getBytes(),CreateMode.PERSISTENT); //3)获取节点数据 //ZookeeperClient.getZnodeData("/zk-test1",true); //4)跟新节点数据 //Stat stat1 = ZookeeperClient.setZnodeData("/zk-test1","111".getBytes(),-1); //Stat stat2 = ZookeeperClient.setZnodeData("/zk-test1","222".getBytes(),stat1.getVersion()); //注意:更新操作使用的版本号与节点最新版本号不一致,抛出异常BadVersionException: KeeperErrorCode = BadVersion for /zk-test1 //Stat stat3 = ZookeeperClient.setZnodeData("/zk-test1","333".getBytes(),stat1.getVersion()); //5)删除节点 //zk-test1下有子节点,删除失败,抛出异常NotEmptyException: KeeperErrorCode = Directory not empty for /zk-test1 //ZookeeperClient.deleteZnode("/zk-test1",4); //传入删除的版本号与实际版本号不一致,删除失败,抛出异常BadVersionException: KeeperErrorCode = BadVersion for /zk-test1/tmp1 //ZookeeperClient.deleteZnode("/zk-test1/tmp1",1); // ZookeeperClient.deleteZnode("/zk-test1/tmp1",0); //ZookeeperClient.deleteZnode("/zk-test1",4); //6)检查节点是否存在 ZookeeperClient.existsZnode("/zk-test2",true); Thread.sleep(Integer.MAX_VALUE); System.out.println("客户端运行结束!"); } catch (IOException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } catch (KeeperException e) { e.printStackTrace(); } } }
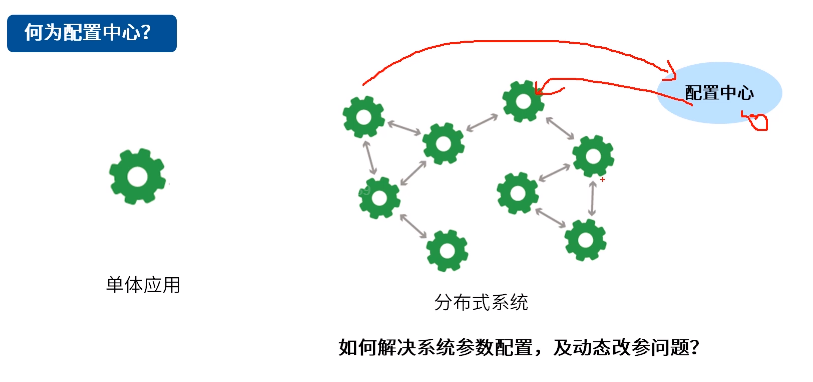
常见应用场景

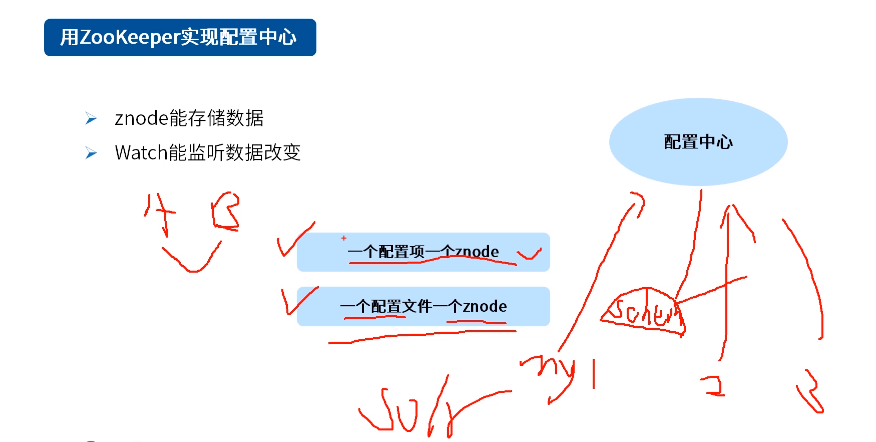
public class ConfigCenterDemo { // 1 将单个配置放到zookeeper上 public void put2Zk() { ZkClient client = new ZkClient("localhost:2181"); client.setZkSerializer(new MyZkSerializer()); String configPath = "/config1"; String value = "1111111"; if (client.exists(configPath)) { client.writeData(configPath, value); } else { client.createPersistent(configPath, value); } client.close(); } // 将配置文件的内容存放到zk节点上 public void putConfigFile2ZK() throws IOException { File f = new File(this.getClass().getResource("/config.xml").getFile()); FileInputStream fin = new FileInputStream(f); byte[] datas = new byte[(int) f.length()]; fin.read(datas); fin.close(); ZkClient client = new ZkClient("localhost:2181"); client.setZkSerializer(new BytesPushThroughSerializer()); String configPath = "/config2"; if (client.exists(configPath)) { client.writeData(configPath, datas); } else { client.createPersistent(configPath, datas); } client.close(); } // 需要配置的服务都从zk上取,并注册watch来实时获得配置更新 public void getConfigFromZk() { ZkClient client = new ZkClient("localhost:2181"); client.setZkSerializer(new MyZkSerializer()); String configPath = "/config1"; String value = client.readData(configPath); System.out.println("从zk读到配置config1的值为:" + value); // 监控配置的更新 client.subscribeDataChanges(configPath, new IZkDataListener() { @Override public void handleDataDeleted(String dataPath) throws Exception { // TODO Auto-generated method stub } @Override public void handleDataChange(String dataPath, Object data) throws Exception { System.out.println("获得更新的配置值:" + data); } }); // 这里只是为演示实时获取到配置值更新而加的等待。实际项目应用中根据具体场景写(可用阻塞方式) try { Thread.sleep(5 * 60 * 1000); } catch (InterruptedException e) { e.printStackTrace(); } } public static void main(String[] args) throws IOException { ConfigCenterDemo demo = new ConfigCenterDemo(); demo.put2Zk(); demo.putConfigFile2ZK(); demo.getConfigFromZk(); } }

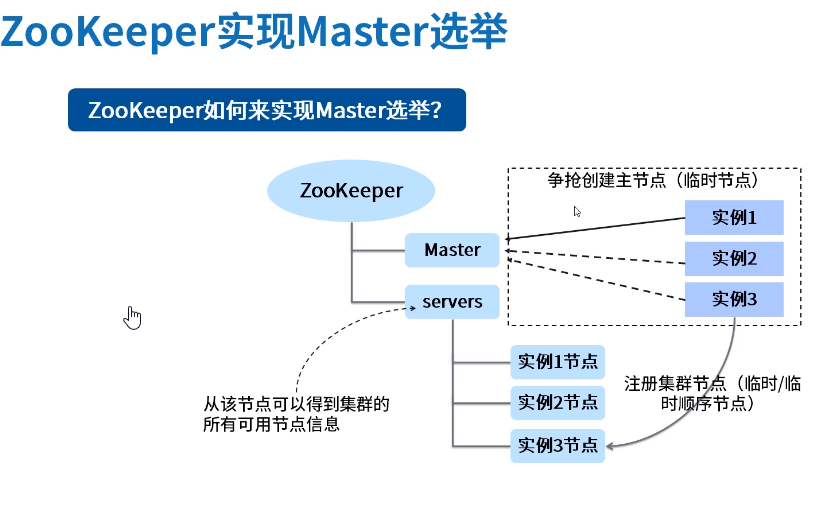

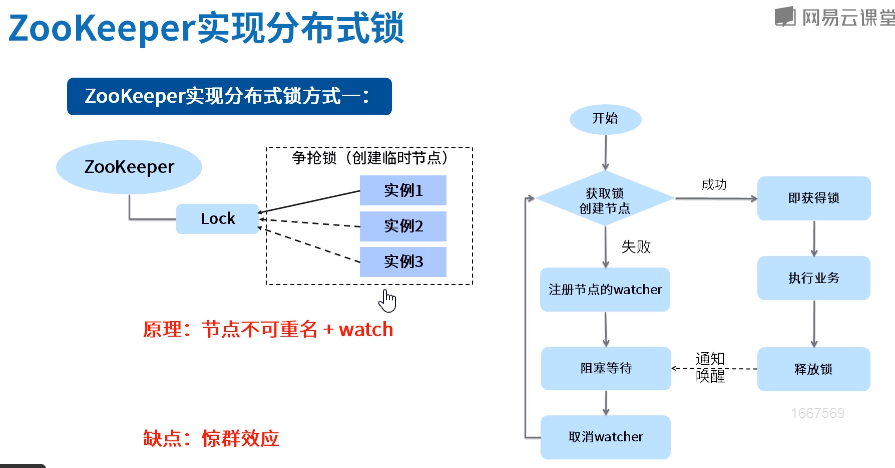
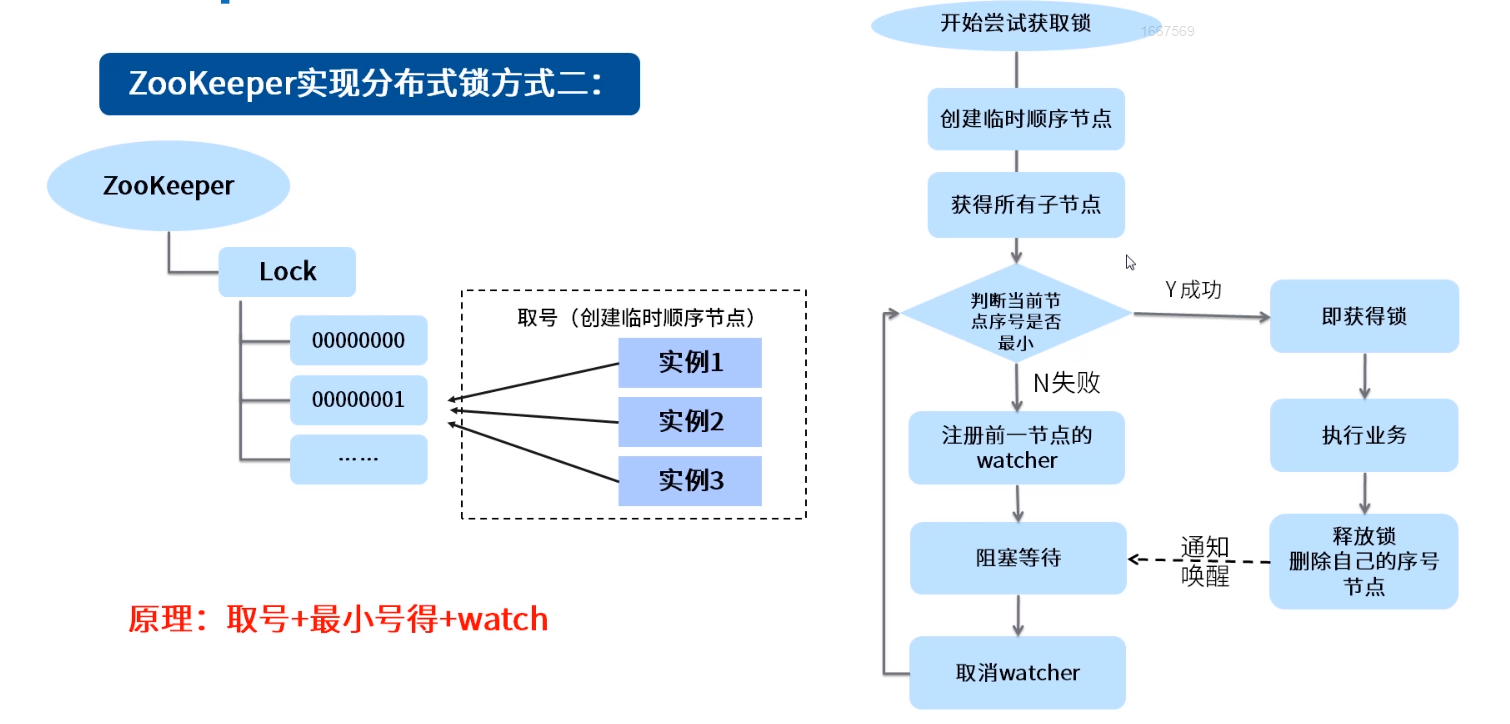
public class ZKDistributeImproveLock implements Lock { /* * 利用临时顺序节点来实现分布式锁 * 获取锁:取排队号(创建自己的临时顺序节点),然后判断自己是否是最小号,如是,则获得锁;不是,则注册前一节点的watcher,阻塞等待 * 释放锁:删除自己创建的临时顺序节点 */ private String lockPath; private ZkClient client; private ThreadLocal<String> currentPath = new ThreadLocal<>(); private ThreadLocal<String> beforePath = new ThreadLocal<>(); // 锁重入计数 private ThreadLocal<Integer> reentrantCount = new ThreadLocal<>(); public ZKDistributeImproveLock(String lockPath) { super(); this.lockPath = lockPath; client = new ZkClient("localhost:2181"); client.setZkSerializer(new MyZkSerializer()); if (!this.client.exists(lockPath)) { try { this.client.createPersistent(lockPath); } catch (ZkNodeExistsException e) { } } } @Override public boolean tryLock() { if (this.reentrantCount.get() != null) { int count = this.reentrantCount.get(); if (count > 0) { this.reentrantCount.set(++count); return true; } } if (this.currentPath.get() == null) { currentPath.set(this.client.createEphemeralSequential(lockPath + "/", "aaa")); } // 获得所有的子 List<String> children = this.client.getChildren(lockPath); // 排序list Collections.sort(children); // 判断当前节点是否是最小的 if (currentPath.get().equals(lockPath + "/" + children.get(0))) { this.reentrantCount.set(1); return true; } else { // 取到前一个 // 得到字节的索引号 int curIndex = children.indexOf(currentPath.get().substring(lockPath.length() + 1)); beforePath.set(lockPath + "/" + children.get(curIndex - 1)); } return false; } @Override public void lock() { if (!tryLock()) { // 阻塞等待 waitForLock(); // 再次尝试加锁 lock(); } } private void waitForLock() { CountDownLatch cdl = new CountDownLatch(1); // 注册watcher IZkDataListener listener = new IZkDataListener() { @Override public void handleDataDeleted(String dataPath) throws Exception { System.out.println("-----监听到节点被删除"); cdl.countDown(); } @Override public void handleDataChange(String dataPath, Object data) throws Exception { } }; client.subscribeDataChanges(this.beforePath.get(), listener); // 怎么让自己阻塞 if (this.client.exists(this.beforePath.get())) { try { cdl.await(); } catch (InterruptedException e) { e.printStackTrace(); } } // 醒来后,取消watcher client.unsubscribeDataChanges(this.beforePath.get(), listener); } @Override public void unlock() { // 重入的释放锁处理 if (this.reentrantCount.get() != null) { int count = this.reentrantCount.get(); if (count > 1) { this.reentrantCount.set(--count); return; } else { this.reentrantCount.set(null); } } // 删除节点 this.client.delete(this.currentPath.get()); } @Override public void lockInterruptibly() throws InterruptedException { // TODO Auto-generated method stub } @Override public boolean tryLock(long time, TimeUnit unit) throws InterruptedException { // TODO Auto-generated method stub return false; } @Override public Condition newCondition() { // TODO Auto-generated method stub return null; } public static void main(String[] args) { // 并发数 int currency = 50; // 循环屏障 CyclicBarrier cb = new CyclicBarrier(currency); // 多线程模拟高并发 for (int i = 0; i < currency; i++) { new Thread(new Runnable() { public void run() { System.out.println(Thread.currentThread().getName() + "---------我准备好---------------"); // 等待一起出发 try { cb.await(); } catch (InterruptedException | BrokenBarrierException e) { e.printStackTrace(); } ZKDistributeImproveLock lock = new ZKDistributeImproveLock("/distLock"); try { lock.lock(); System.out.println(Thread.currentThread().getName() + " 获得锁!"); } finally { lock.unlock(); } } }).start(); } } }