B+ 索引树回顾
上篇教程学院君给大家介绍了不同类型的数据库索引对应的 B+ 树是如何维护的,这其实是对数据库表记录进行更新时底层所做的(插入、修改、删除)事情,我们来简单回顾下 B+ 索引树:
- 每个索引都对应一棵 B+ 树,这棵 B+ 树最下面一层叶子节点存放的是存储用户记录的数据页,其他层存放的是存储数据页目录项(这里的数据页可能是叶子节点、也可能是非叶子节点)的数据页;
- 对于 InnoDB 存储引擎而言,主键索引也叫簇拥索引,叶子节点存储的用户记录包含了对应表记录的完整数据集,如果一张表没有指定主键,则系统会自动为其创建一个隐式主键;
- 对于二级索引(唯一索引、普通索引、联合索引),叶子节点存储的用户记录由索引列和主键值组成(如果对应数据表没有指定主键,则使用系统自动生成的隐式主键),因此想通过二级索引获取完整数据记录,需要经历两次查询:先通过二级索引获取对应记录主键值,再通过主键值到簇拥索引获取完整数据记录(这一步操作叫做回表);
- B+ 树的每一层节点以及节点内的记录都是按照索引值从小到大排列的,这样一来,当我们进行 SQL 查询时,就可以从 B+ 树的根节点开始,先通过二分查找在数据页目录中快速定位到记录所在的数据页,再在存储用户记录的数据页中通过二分查找找到对应的数据记录,由于二分查找效率非常高,所以命中索引的 SQL 查询效率也非常高。
注:上篇教程是在数据表有主键的基础上介绍 B+ 索引树的维护,如果一张数据表没有指定主键,则 MySQL 会自动为其创建隐式主键,这样一来,就依然会有完整的簇拥索引和二级索引,只是这个隐式索引字段是虚拟的,不可能通过显式的 SQL 查询条件命中,但是如果命中了二级索引,回表的时候依然不会出现全表扫描,而是通过隐式主键去簇拥索引中拿到完整数据记录。
SQL 查询语句分为多种类型,包括等值查询、范围查询、模糊匹配、连接查询,以及排序、分组、限定等更复杂的过滤条件,在各种不同的查询场景下,又是如何命中索引对指定 B+ 树进行搜索的呢?这将是我们今天所要探讨的问题。
初始化数据库
通过存储过程
对于一些非常简单的数据表示例数据填充,可以通过 MySQL 自带的存储过程来实现,比如我们创建一个名为 demo 的数据表:
CREATE TABLE `demo` (
`a` int(10) unsigned NOT NULL,
`b` int(10) unsigned NOT NULL,
`c` int(10) unsigned NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
为了方便对比测试,我们先不设置任何索引字段,然后我们通过存储过程对这张数据表进行填充:
delimiter ;;
create procedure insertdata()
begin
declare i int;
set i=1;
while(i<=1000000)do
insert into demo values(i, i, i);
set i=i+1;
end while;
end;;
delimiter ;
call insertdata();
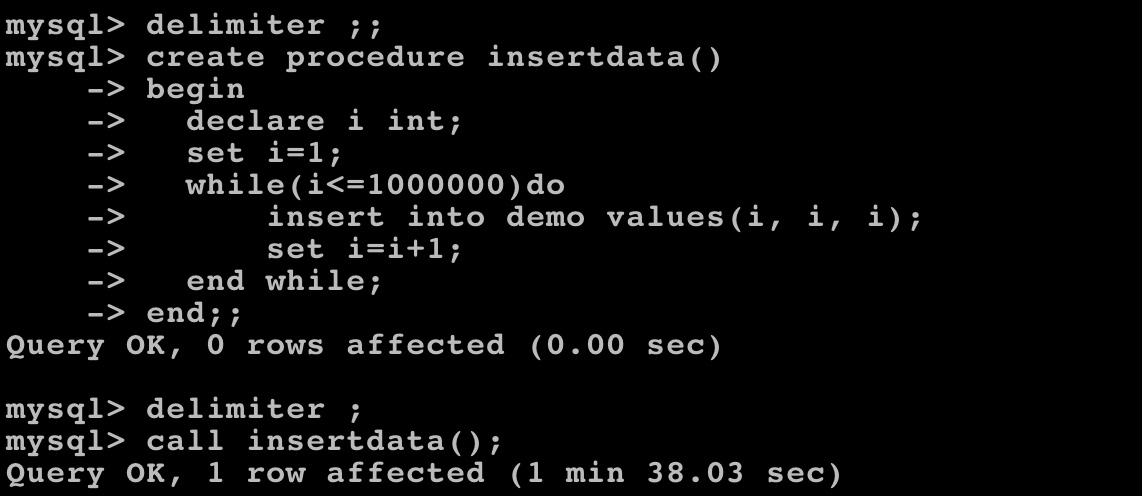
这里我们向 demo 表插入了 1000000 条记录,由于没有设置任何索引,所以查询耗时很长:

如果使用 explain 查看执行计划的话,通过 type 字段为 ALL 表明使用了全表扫描:

而如果我们为字段设置索引的话:
CREATE TABLE `demo` (
`a` int(10) unsigned NOT NULL,
`b` int(10) unsigned NOT NULL,
`c` int(10) unsigned NOT NULL,
PRIMARY KEY (`a`),
KEY `b_c` (`b`, `c`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
则查询效率会明显改善:
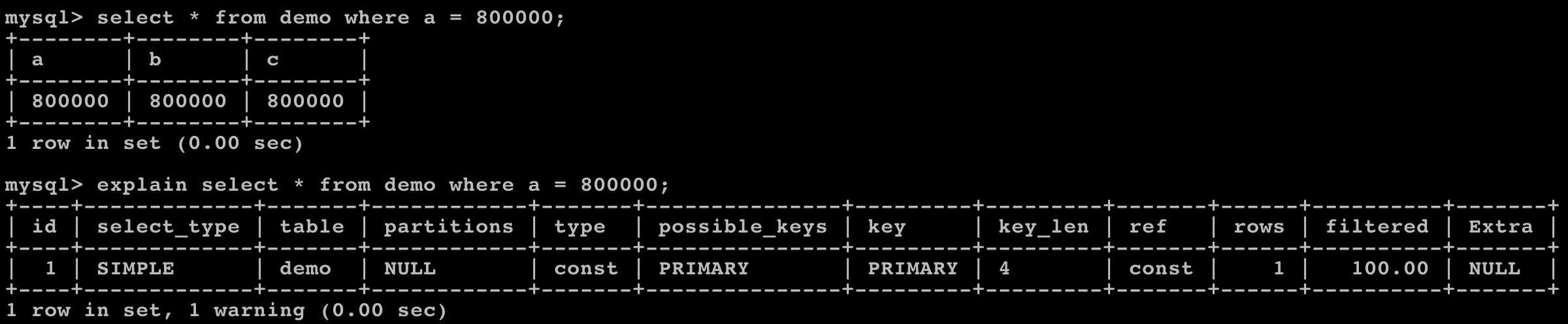
通过执行计划可以看到第二次查询命中了主键索引,使得查询效率提升了 30 倍。
通过编写代码
如果表结构比较复杂,要填充数据表,可以通过编码的方式实现,只不过使用这种方式性能远不及存储过程高效。
这里我们借助一个 PHP 命令行应用微框架 Laravel Zero 演示数据表结构的初始化和测试数据的填充。
数据库和项目初始化
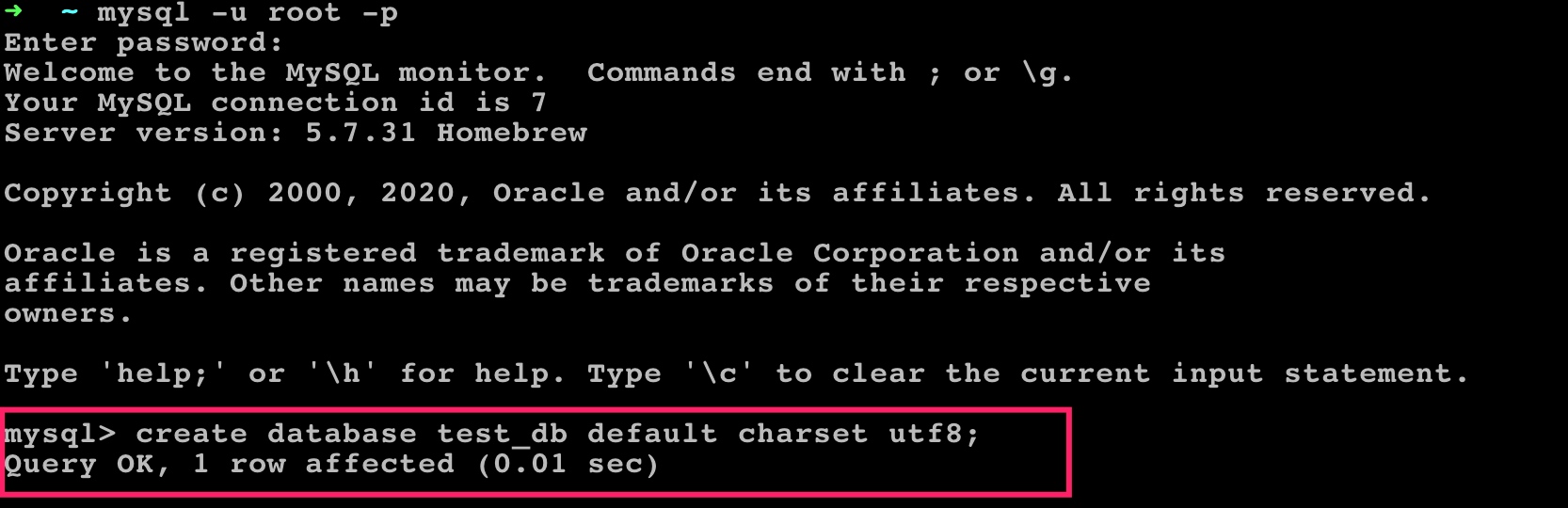
开始之前,我们先来创建一个测试数据库 test_db:
然后运行如下命令通过 Composer 初始化一个命令行应用 db-test:
composer create-project --prefer-dist laravel-zero/laravel-zero db-test -vvv
进入 db-test 项目目录,安装数据库依赖:
php application app:install database
以及支持通过 .env 配置环境变量:
php application app:install dotenv
在 .env 中完成数据库配置:
DB_CONNECTION=mysql
DB_HOST=localhost
DB_PORT=3306
DB_DATABASE=test_db
DB_USERNAME=root
DB_PASSWORD=root
创建演示数据表
创建一个数据库模型类和对应的迁移文件:

在数据表迁移文件 2020_09_07_094403_create_users_table.php 中,编写创建数据表的 up 方法如下:
public function up()
{
Schema::create('users', function (Blueprint $table) {
$table->id();
$table->string('name', 50);
$table->string('id_number', 60);
$table->boolean('gender');
$table->string('address', 100);
$table->date('birthday');
});
}
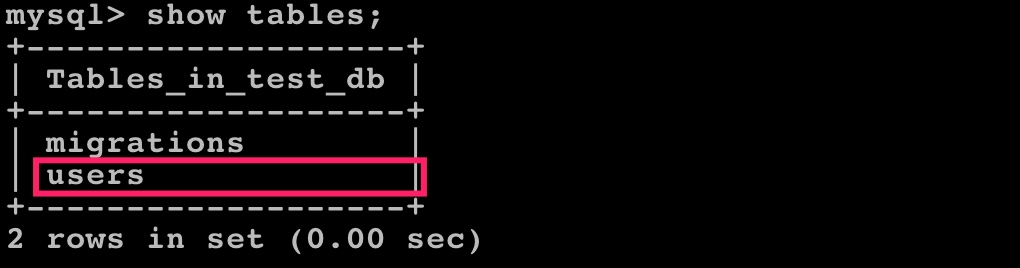
然后运行 php application migrate 创建 users 表:

这样就可以看到数据库 test_db 中已经存在这个数据表了:
或者你也可以执行如下 SQL 语句去创建:
CREATE TABLE `users` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL,
`id_number` varchar(60) NOT NULL,
`gender` tinyint(1) NOT NULL,
`address` varchar(100) NOT NULL,
`birthday` date NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
为了对比索引存在与否对查询性能的影响,除了主键 ID 之外,并没有添加其他的索引字段。
通过模型工厂模拟数据插入
接下来,我们通过模型工厂来编写填充示例数据的代码:

打开刚刚生成的模型工厂文件 UserFactory.php(位于 database/factories 目录下),编写模型工厂代码如下:
/** @var IlluminateDatabaseEloquentFactory $factory */
use AppUser;
use FakerGenerator as Faker;
$factory->define(User::class, function (Faker $faker) {
return [
'name' => $faker->name,
'id_number' => $faker->uuid,
'gender' => $faker->boolean,
'address' => $faker->address,
'birthday' => $faker->date(),
];
});
修改 User 模型类代码如下:
namespace App;
use IlluminateDatabaseEloquentModel;
class User extends Model
{
const FEMALE = 0;
const MALE = 1;
public $timestamps = false;
}
编写填充用户数据命令
最后我们编写一个命令调用模型工厂填充 users 数据表:
php application make:command SeedUsersTable
生成的命令类位于 app/Commands 目录下,编写命令类代码如下:
namespace AppCommands;
use AppUser;
use IlluminateConsoleSchedulingSchedule;
use LaravelZeroFrameworkCommandsCommand;
class SeedUsersTable extends Command
{
/**
* The signature of the command.
*
* @var string
*/
protected $signature = 'seed:users';
/**
* The description of the command.
*
* @var string
*/
protected $description = 'Seed Users Table';
/**
* Execute the console command.
*
* @return mixed
*/
public function handle()
{
$this->info('Start seeding users table...');
$startTime = time();
// 插入 100000 条记录
$amount = 100000;
// 通过进度条显式进度
$this->output->progressStart($amount);
// 调用模型工厂插入用户记录,每次插入 1000 条
for ($i = 0; $i < $amount; $i += 1000) {
factory(User::class, 1000)->create();
$this->output->progressAdvance(1000);
}
$this->output->progressFinish();
$endTime = time();
$execTime = $endTime - $startTime;
$this->info('Finished.(Time spent: ' . $execTime . 's)');
}
/**
* Define the command's schedule.
*
* @param IlluminateConsoleSchedulingSchedule $schedule
* @return void
*/
public function schedule(Schedule $schedule): void
{
// $schedule->command(static::class)->everyMinute();
}
}
重点关注 handle 方法,这是我们运行 seed:users 命令时底层所执行的代码:这里我们插入了 100000 条记录,每次调用模型工厂插入 1000 条记录,并且通过输出进度条显示插入进度,所有记录插入成功后输出提示文本和耗时。
在终端 db_test 项目根目录下执行 php application seed:users,由于插入记录多,所以会比较耗时(这个时候可以泡杯咖啡,慢慢等待☕️,或者去干点别的):

Tips:可以看到,使用这种方式插入 100000 条记录也远不及使用存储过程插入 1000000 条记录来的快。
如果你想要插入更多记录,可以打开新的终端窗口并行执行上述命令,比如你想要插入 1000000 条记录,则同时打开 10 个终端窗口执行上述命令即可。
你可以通过 select count(*) from users 查看总记录数是否是 100000:

下篇教程,我们将以 users 表为例演示对于不同类型的查询语句,如何合理设置索引字段可以有效提升查询性能,而又不用带来过多的索引代价。