大数据体系概览Spark、Spark核心原理、架构原理、Spark特点
小提示:这里,使用axure(原型制作工具),来画图十分方便,个人认为比viso或者是processon等流程图制作工具简单多了。
点击链接,看取axure画完以后生成的html网页。
spark的axure原型
效果图:
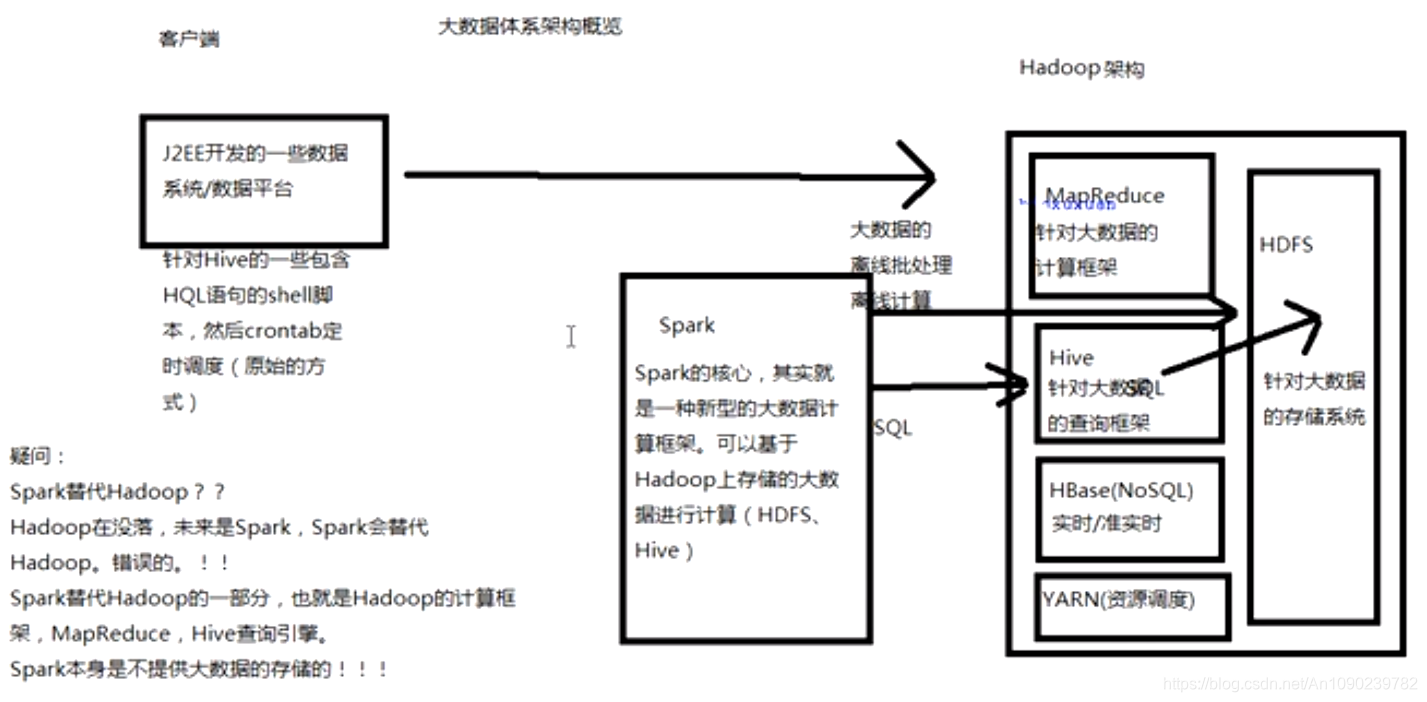
大数据体系概览(Spark的地位)
Hadoop生态圈重点组件:
-
HDFS:Hadoop的分布式文件存储系统。
-
MapReduce:Hadoop的分布式程序运算框架,也可以叫做一种编程模型。
-
Hive:基于Hadoop的类SQL数据仓库工具
-
Hbase:基于Hadoop的列式分布式NoSQL数据库
-
ZooKeeper:分布式协调服务组件
-
Mahout:基于MapReduce/Flink/Spark等分布式运算框架的机器学习算法库
-
Oozie/Azkaban:工作流调度引擎
-
Sqoop:数据迁入迁出工具
-
Flume:日志采集工具
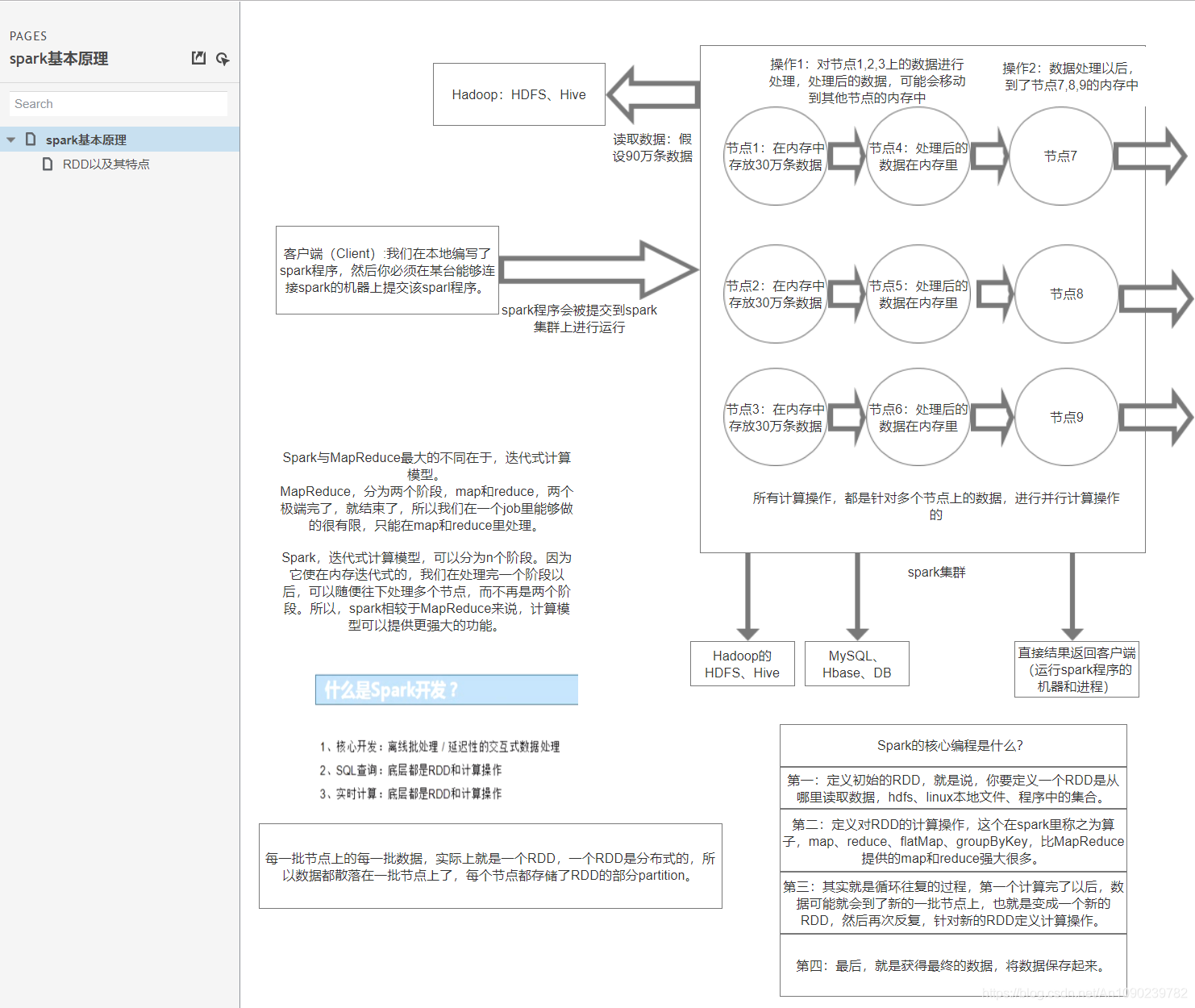
什么是Spark?
Spark,是一种通用的大数据计算框架,如Hadoop的MapReduce、Hive引擎,以及Storm流式实时计算引擎等。
Spark包含了大数据领域常见的各种计算框架:比如Spark Core用于离线计算,Spark SQL用于交互式查询,Spark Streaming用于实时流式计算,Spark MLlib用于机器学习,Spark Graphx用于图计算。
Spark主要用于大数据的计算,而Hadoop主要用于大数据的存储(比如HDFS、Hive、HBase),以及资源调度(Yarn)。
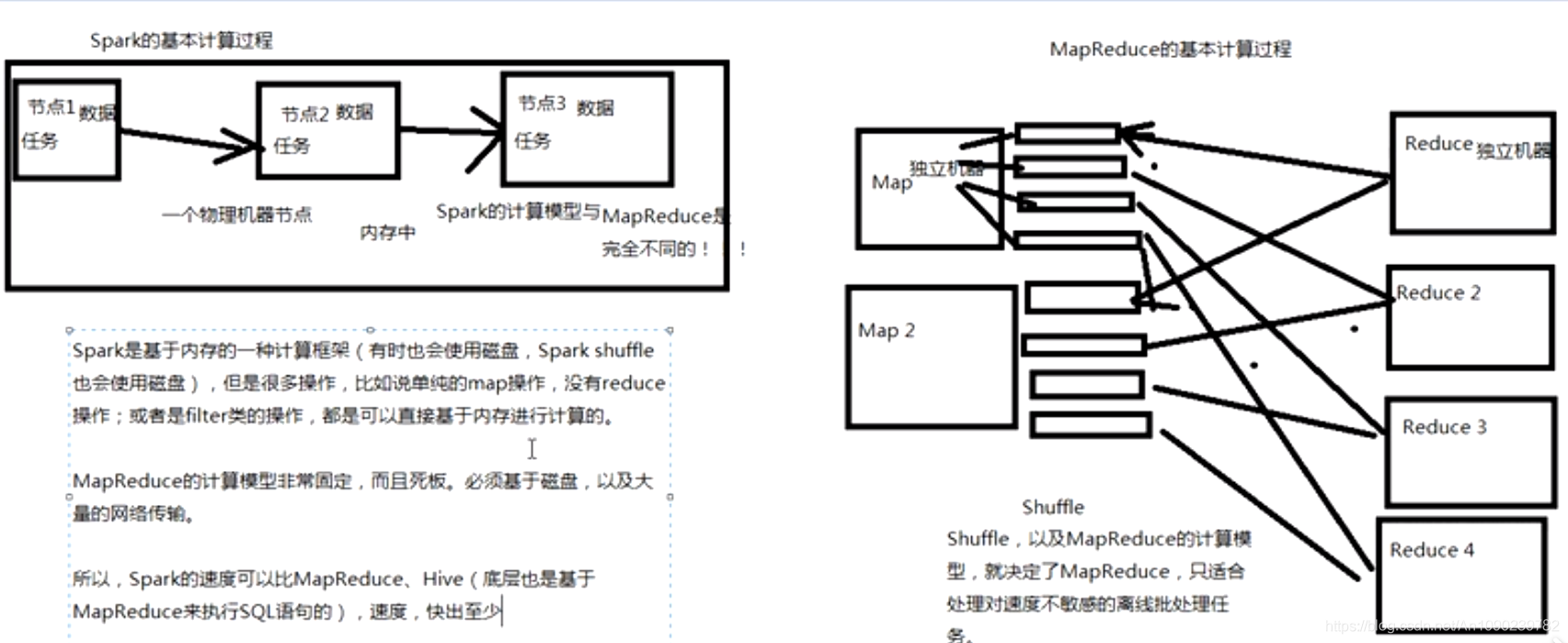
Spark除了一站式的特点之外,就是基于内存进行计算,从而让它的速度可以达到MapReduce、Hive的数倍甚至十倍!
Spark整体架构
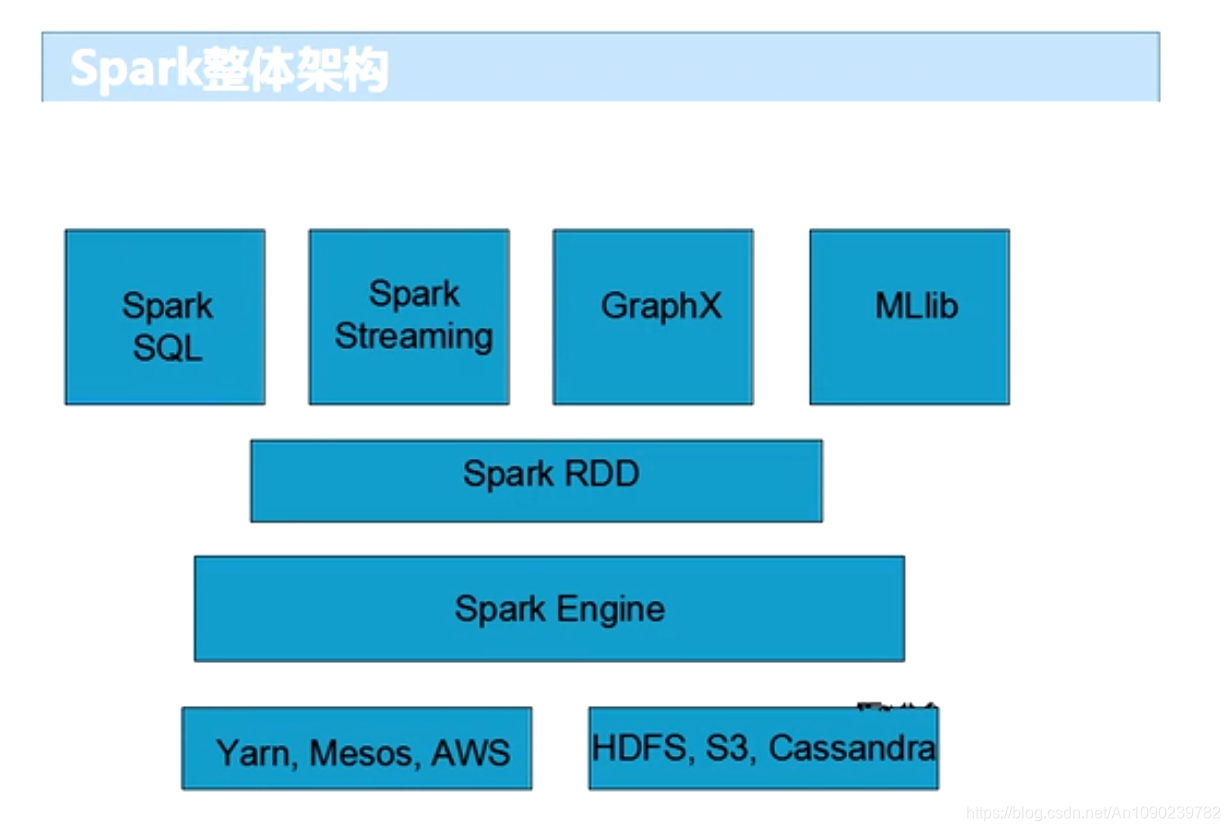
Spark的特点
- 速度快:Spark基于内存计算(部分基于磁盘,如shuffle)
- 超强的通用性:Spark提供了Spark RDD、Spark SQL、Spark Streaming、Spark MLlib、Spark Graphx等组件,可以一站式完成大数据领域的离线批处理、交互式查询、流式计算、机器学习、图形计算等常见的任务。
- 集成Hadoop:与Hadoop进行了高度的集成,Hadoop的HDFS、Hive、HBase负责存储,Yarn负责资源调度,Spark负责大数据计算。
Spark核心原理
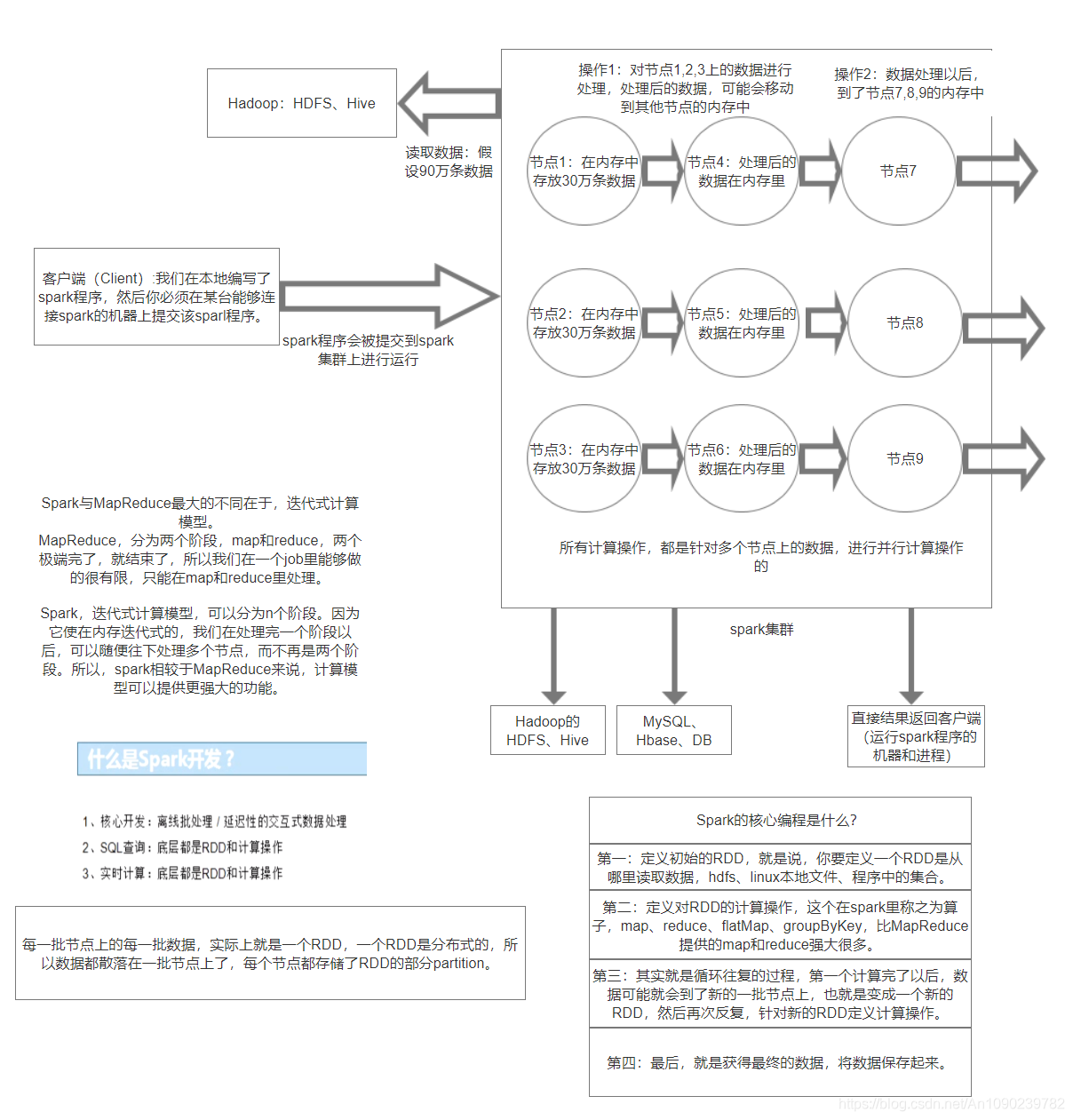
Spark架构原理
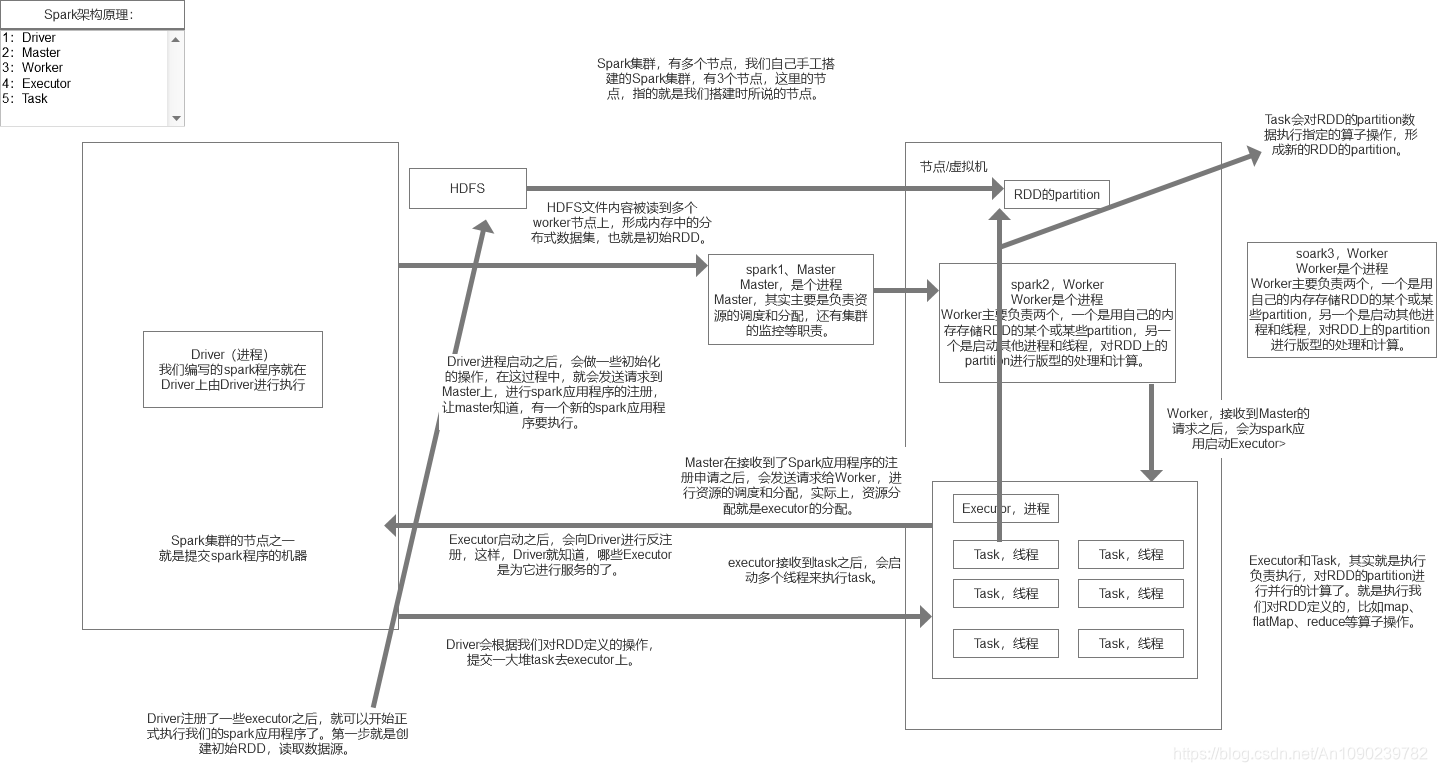
spark内核架构
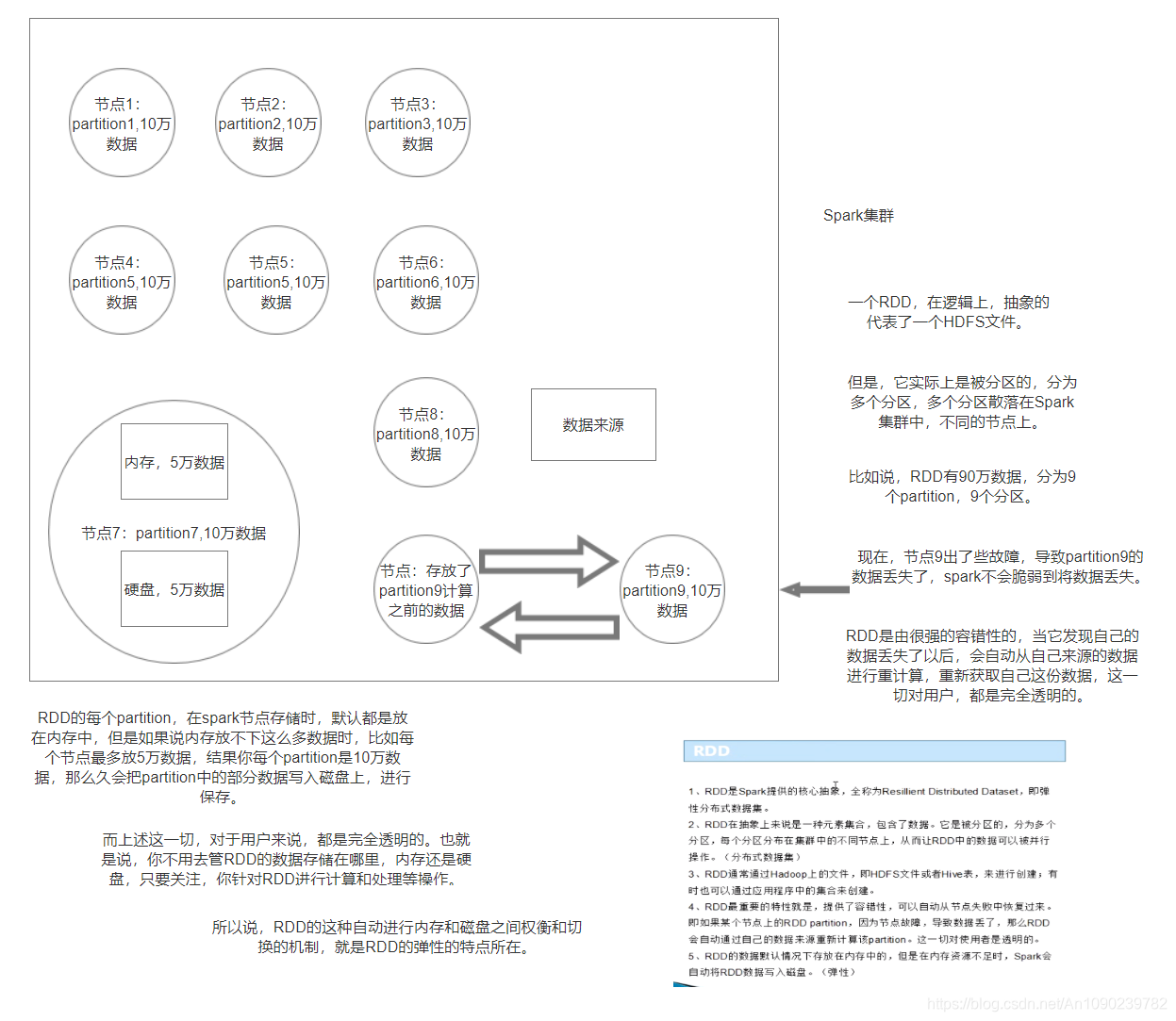
RDD及其特点
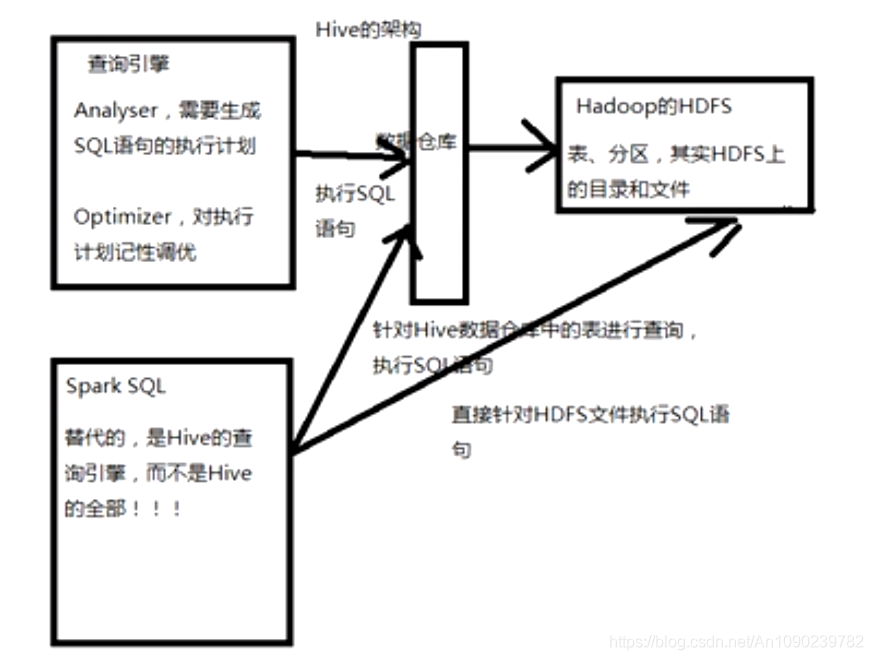
Spark SQL VS Hive
Hive基于HDFS的数据仓库,并提供了SQL模型的,针对存储了大数据的数据仓库,进行分布式交互查询的查询引擎。
Spark SQL是针对Hive数据仓库中的数据进行查询,Spark本身自己不提供存储。
Spark SQL支持大量不同的数据源,包括hive、json、parquet、jdbc等。
Spark Streaming VS Storm
Spark Streaming与Storm都可以进行实时流计算,但是二者区别很大。
Spark Streaming和Storm计算模型完全不一样,Spark Streaming是基于RDD的,因此需要将一小段时间内的,比如1s的数据,收集起来,作为一个RDD,然后再针对这个batch得数据进行处理。
而Storm却可以做到每来一条数据,都可以立即进行处理和计算。
Storm支持在分布式流式计算程序运行过程中,可以动态地调整并行度,从而动态提供并发处理能力,而Spark Streaming是无法动态调整并行度的。
Spark Streaming由于是基于batch进行处理的,因此相较于Storm基于单条数据进行处理,具有数倍甚至数十倍的吞吐量。

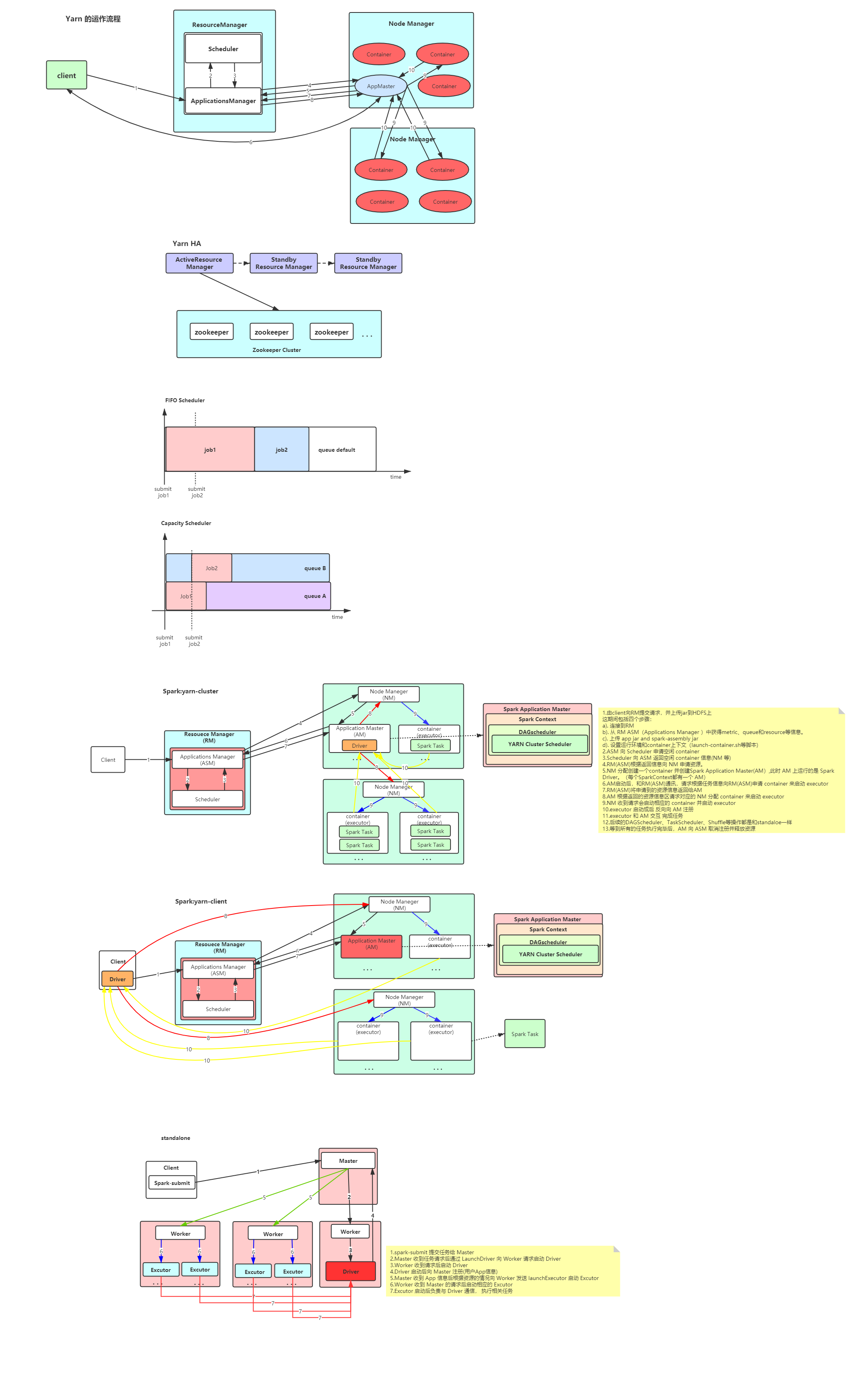
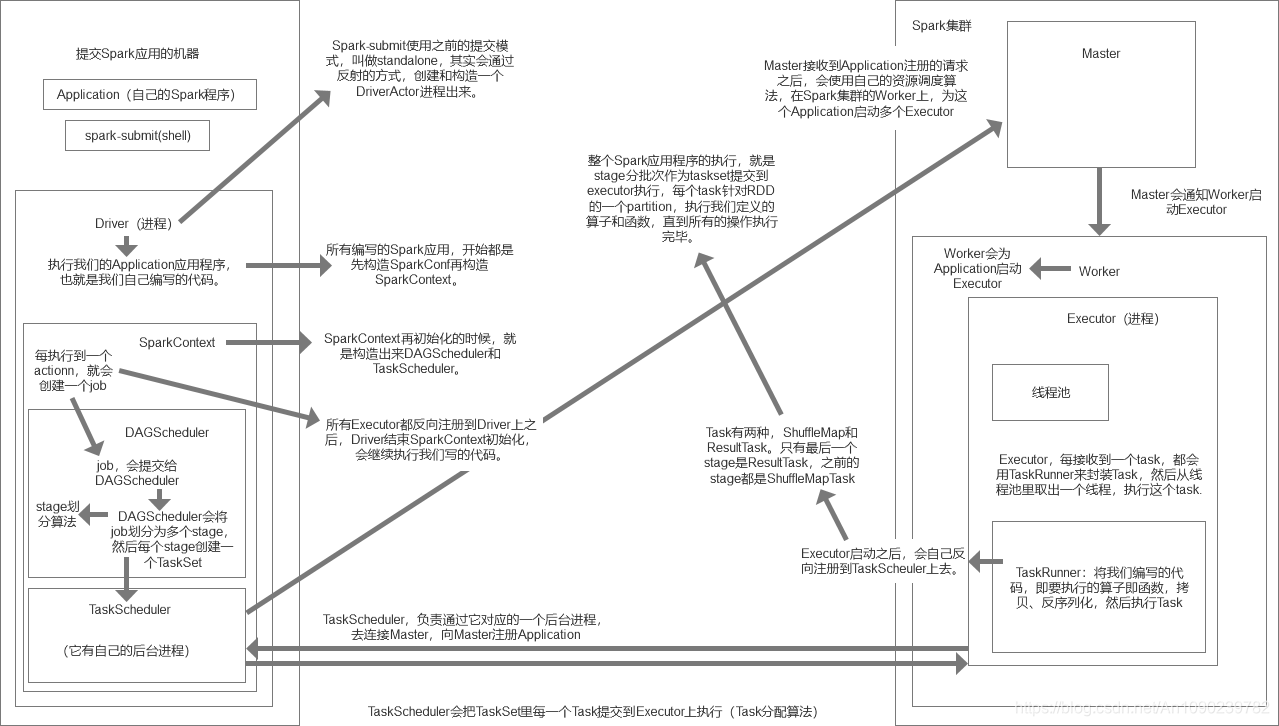
spark 任务提交流程