Hadoop伪分布式环境安装
环境
本教程使用 CentOS 6.9 64位 作为系统环境,基于原生 Hadoop 2,在 Hadoop 2.7.6 (stable) 版本下验证通过。
准备工作
目前安装所需要的文件都放在/home/hadoop/software
拷贝的虚拟机信息
操作系统用户名root密码123456
操作系统用户名hadoop密码123456
mysql数据库用户名root密码root
mysql数据库用户名hive密码hive
创建hadoop用户
如果你安装 CentOS 的时候不是用的 “hadoop” 用户,那么需要增加一个名为 hadoop 的用户。
首先点击左上角的 “应用程序” -> “系统工具” -> “终端”,首先在终端中输入 su ,按回车,输入 root 密码以 root 用户登录,接着执行命令创建新用户 hadoop:
- su # 上述提到的以 root 用户登录
- useradd -m -s /bin/bash hadoop # 创建新用户hadoop
如下图所示,这条命令创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为shell。

CentOS创建hadoop用户
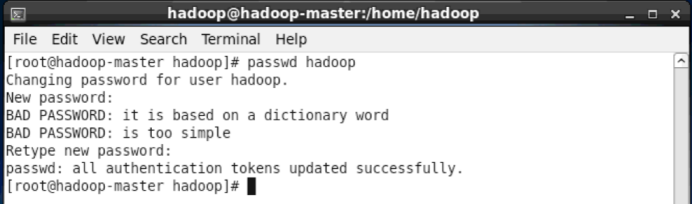
接着使用如下命令修改密码,按提示输入两次密码,可简单的设为 “hadoop”(密码随意指定,若提示“无效的密码,过于简单”则再次输入确认就行):
- passwd hadoop
如下图所示
可为 hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题,执行:
- visudo
如下图,找到 root ALL=(ALL) ALL 这行(应该在第91行,可以先按一下键盘上的 ESC 键,然后输入 :91 (按一下冒号,接着输入91,再按回车键),可以直接跳到第91行 ),然后在这行下面增加一行内容:hadoop ALL=(ALL) ALL(当中的间隔为tab),如下图所示:
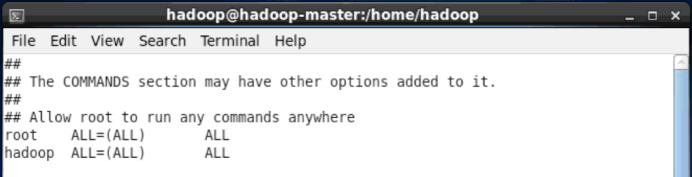
为hadoop增加sudo权限
添加上一行内容后,先按一下键盘上的 ESC 键,然后输入 :wq (输入冒号还有wq,这是vi/vim编辑器的保存方法),再按回车键保存退出就可以了。
最后注销当前用户(点击屏幕右上角的用户名,选择退出->注销),在登陆界面使用刚创建的 hadoop 用户进行登陆。(如果已经是 hadoop 用户,且在终端中使用 su 登录了 root 用户,那么需要执行 exit 退出 root 用户状态)
CentOS系统需要关闭防火墙和Selinux
CentOS系统默认开启了防火墙,在开启 Hadoop 集群之前,需要关闭集群中每个节点的防火墙。有防火墙会导致 ping 得通但 telnet 端口不通,从而导致 DataNode 启动了,但 Live datanodes 为 0 的情况。
在 CentOS 6.x 中,可以通过如下命令关闭防火墙:
sudo service iptables stop
sudo chkconfig iptables off
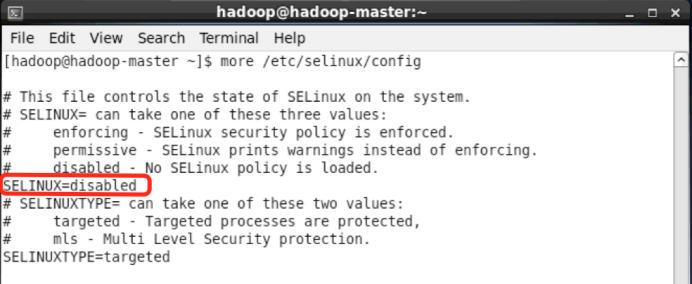
禁用SELinux,修改配置文件/etc/selinux/config,修改成:SELINUX=disabled,重启系统生效
安装SSH、配置SSH无密码登陆
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),一般情况下,CentOS 默认已安装了 SSH client、SSH server,打开终端执行如下命令进行检验:
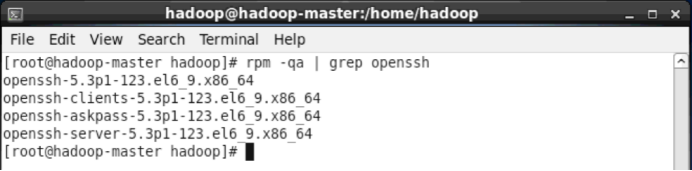
- rpm -qa | grep ssh
如果返回的结果如下图所示(openssh-server、openssh-client),包含了 SSH client 跟 SSH server,则不需要再安装。
检查是否安装了SSH
接着执行如下命令测试一下 SSH 是否可用:
- ssh localhost
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就通过ssh登陆到了本机了。
但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码可以登陆。
首先输入 exit 退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将节点密钥加入到节点授权文件中:
exit
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
验证节点是否可以无密码登陆:
ssh localhost

SSH无密码登录
~的含义
在 Linux 系统中,~ 代表的是用户的主文件夹,即 “/home/用户名” 这个目录,如你的用户名为 hadoop,则 ~ 就代表 “/home/hadoop/”。
安装Java环境
Java 环境可选择 Oracle 的 JDK,或是 OpenJDK,我们选择安装Oracle JDK 8,官方下载链接:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html,目前最新版8u172,下载jdk-8u172-linux-x64.tar.gz
这里安装所需要的软件下载好放在/home/hadoop/software
安装Oracle JDK 8,
cd /home/hadoop/software
sudo mkdir /usr/local/java
sudo tar -xzvf jdk-8u172-linux-x64.tar.gz -C /usr/local/java
sudo mv /usr/local/java/jdk1.8.0_172 /usr/local/java/latest
sudo chown hadoop:hadoop -R /usr/local/java
接着需要配置一下 JAVA_HOME 环境变量,为方便,我们在 ~/.bashrc 中进行设置:
- vim ~/.bashrc
在文件最后面添加如下单独一行(指向 JDK 的安装位置),并保存:
export JAVA_HOME=/usr/local/java/latest
export JRE_HOME=/usr/local/java/latest/jre
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin:$PATH
如下图所示:
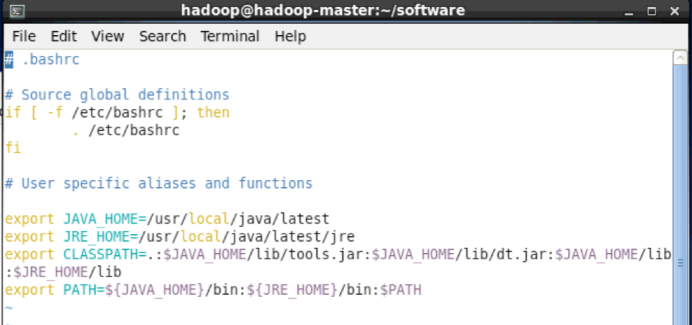
设置JAVA_HOME环境变量
接着还需要让该环境变量生效,执行如下代码:
- source ~/.bashrc # 使变量设置生效
设置好后我们来检验一下是否设置正确:
- echo $JAVA_HOME # 检验变量值
- java -version
- $JAVA_HOME/bin/java -version # 与直接执行 java -version 一样
如果设置正确的话,$JAVA_HOME/bin/java -version 会输出 java 的版本信息,且和 java -version 的输出结果一样,如下图所示:
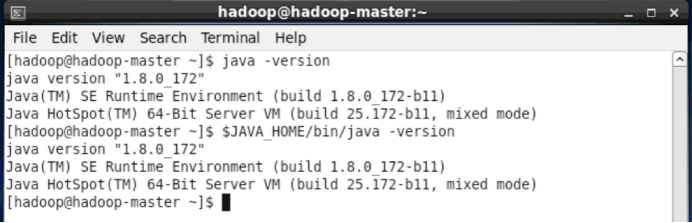
成功设置JAVA_HOME环境变量
这样,Hadoop 所需的 Java 运行环境就安装好了。
安装 Hadoop 2
Hadoop 2 可以通过 http://mirror.bit.edu.cn/apache/hadoop/common/ 或者 http://mirrors.cnnic.cn/apache/hadoop/common/ 下载,本教程选择的是 2.7.6 版本,下载时请下载 hadoop-2.7.6.tar.gz 这个格式的文件,这是编译好的,另一个包含 src 的则是 Hadoop 源代码,需要进行编译才可使用。
我们选择将 Hadoop 安装至 /usr/local/ 中:
cd /home/hadoop/software
sudo tar -xzvf hadoop-2.7.6.tar.gz -C /usr/local
sudo mv /usr/local/hadoop-2.7.6/ /usr/local/hadoop
sudo chown -R hadoop:hadoop /usr/local/hadoop
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
/usr/local/hadoop/bin/hadoop version
配置Hadoop PATH变量
将 Hadoop 安装目录加入 PATH 变量中,这样就可以在任意目录中直接使用 hadoo、hdfs 等命令了,如果还没有配置的,需要在 Master 节点上进行配置。首先执行 vim ~/.bashrc,加入:
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native" export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
保存后执行 source ~/.bashrc 使配置生效。
配置伪分布式环境
集群/分布式模式需要修改 /usr/local/hadoop/etc/hadoop 中的5个配置文件,更多设置项可点击查看官方说明,这里仅设置了正常启动所必须的设置项: hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
1、文件hadoop-env.sh,修改JAVA_HOME环境变量值
export JAVA_HOME=/usr/local/java/latest
1, 文件 core-site.xml 改为下面的配置:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
3, 文件 hdfs-site.xml改为下面的配置:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
4, 文件 mapred-site.xml (可能先重命名,默认文件名为 mapred-site.xml.template),
重命名
cd /usr/local/hadoop/etc/hadoop
mv mapred-site.xml.template mapred-site.xml
然后配置修改如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>localhost:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>localhost:19888</value>
</property>
</configuration>
5, 文件 yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
首次启动需要先在 Master 节点执行 NameNode 的格式化:
hdfs namenode -format # 首次运行需要执行初始化,之后不需要
接着可以启动 hadoop 了:
- start-dfs.sh
- start-yarn.sh
- mr-jobhistory-daemon.sh start historyserver
通过命令 jps 可以查看各个节点所启动的进程。正确的话,在 Master 节点上可以看到 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer 进程,如下图所示:
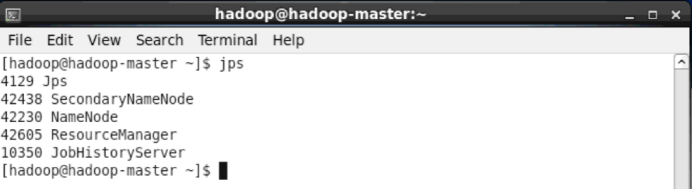
通过jps查看Master的Hadoop进程
在 Slave 节点可以看到 DataNode 和 NodeManager 进程,如下图所示:
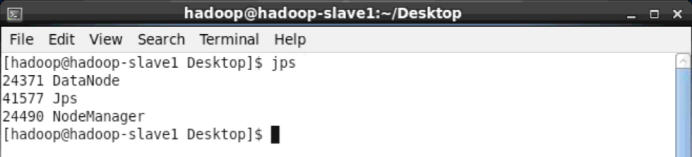
通过jps查看Slave的Hadoop进程
缺少任一进程都表示出错。另外还需要在 master 节点上通过命令 hdfs dfsadmin -report 查看 DataNode 是否正常启动,如果 Live datanodes 不为 0 ,则说明集群启动成功。例如我这边一共有 1 个 Datanodes:
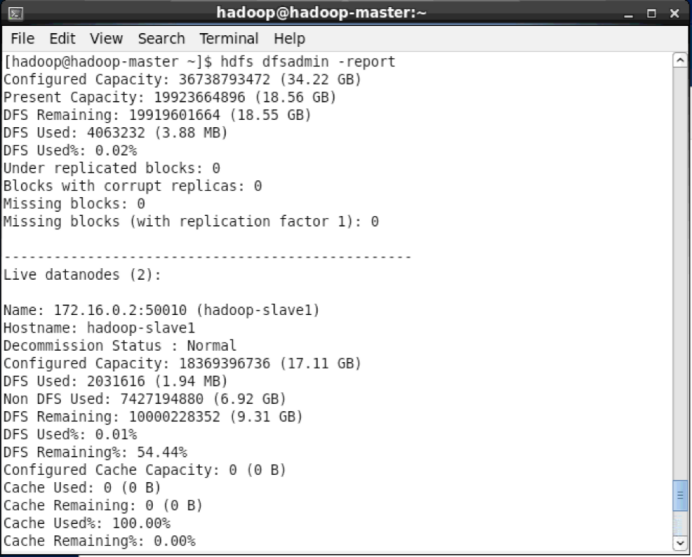
通过dfsadmin查看DataNode的状态
也可以通过 Web 页面看到查看 DataNode 和 NameNode 的状http://127.0.0.1:50070/。如果不成功,可以通过启动日志排查原因。
伪分布式、分布式配置切换时的注意事项
1, 从分布式切换到伪分布式时,不要忘记修改 slaves 配置文件;
2, 在两者之间切换时,若遇到无法正常启动的情况,可以删除所涉及节点的临时文件夹,这样虽然之前的数据会被删掉,但能保证集群正确启动。所以如果集群以前能启动,但后来启动不了,特别是 DataNode 无法启动,不妨试着删除所有节点(包括 Slave 节点)上的 /usr/local/hadoop/tmp 文件夹,再重新执行一次 hdfs namenode -format,再次启动试试。
执行分布式实例
执行分布式实例过程与伪分布式模式一样,首先创建 HDFS 上的用户目录:
- hdfs dfs -mkdir -p /user/hadoop
将 /usr/local/hadoop/etc/hadoop 中的配置文件作为输入文件复制到分布式文件系统中:
- hdfs dfs -mkdir input
- hdfs dfs -put /usr/local/hadoop/etc/hadoop/*.xml input
通过查看 DataNode 的状态(占用大小有改变),输入文件确实复制到了 DataNode 中,如下图所示:
通过Web页面查看DataNode的状态
接着就可以运行 MapReduce 作业了:
- hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
运行时的输出信息与伪分布式类似,会显示 Job 的进度。
可能会有点慢,但如果迟迟没有进度,比如 5 分钟都没看到进度,那不妨重启 Hadoop 再试试。若重启还不行,则很有可能是内存不足引起,建议增大虚拟机的内存,或者通过更改 YARN 的内存配置解决。
显示MapReduce Job的进度
同样可以通过 Web 界面查看任务进度 http://localhost:8088/cluster,在 Web 界面点击 “Tracking UI” 这一列的 History 连接,可以看到任务的运行信息,如下图所示:
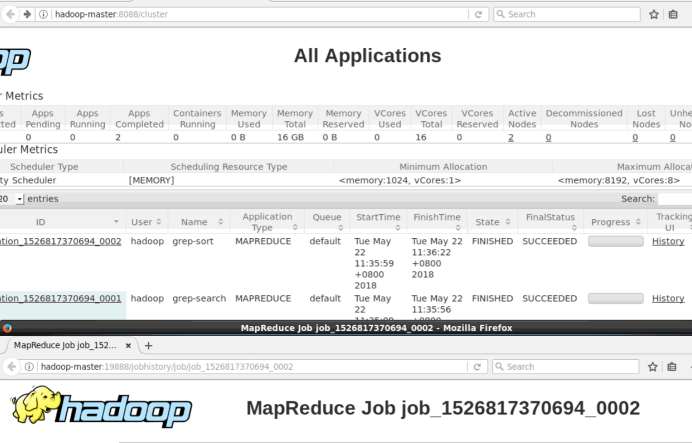
通过Web页面查看集群和MapReduce作业的信息
执行完毕后的输出结果:

MapReduce作业的输出结果
关闭 Hadoop 集群也是在 master 节点上执行的:
- stop-yarn.sh
- stop-dfs.sh
- mr-jobhistory-daemon.sh stop historyserver
自此,你就hadoop的基本组件安装就完成了。