论文:You Only Look Once: Unified, Real-Time Object Detection
原文链接:https://arxiv.org/abs/1506.02640
背景介绍
目前的目标检测系统是由原来的目标分类系统改造而来。为了检测目标这些系统在待检测图片的不同位置而使用分类系统。像DPM(deformable parts models)使用了滑动窗口方法。分类器在图片中的不同窗口上运行以便检测出目标。
更先进一点的研究,例如R-CNN使用了候选区域生成的方法。首先在图片中生成可能会用到的区域。在候选区域上使用分类算法后,后续经过位置精修,去除重复区域,重新对候选区域进行打分。因为每个单独的目标必须被单独训练,因此训练流程通常很慢,复杂而且难以优化。
我们重新定义目标检测,将其视为一个简单的回归问题。使用我们的系统,你只用看图片一次就能检测出有哪些目标以及这些目标的位置。YOLO(You Only Look Once)的结构十分简单如下图所示:
=EN-US>
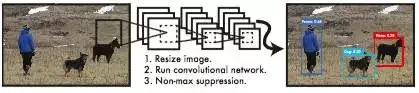
图1 YOLO 结构图
具体步骤如下:
- 将输入图片大小变换为448 × 448 。
- 在图片上运行单个卷积神经网络。
- 得出检测结果,并以confidence的形式给出。
YOLO中的单个卷积神经网络可以同时检测出多个目标区域以及目标所属种类的可能性。YOLO能够在整张图像上训练,直接优化检测性能。 这种统一的检测系统比传统的物体检测有系统有诸多好处。
- YOLO速度很快,在使用过程中,YOLO模型能够在GPU Titan X 上以150fps的速度运行。而且YOLO检测准确度是其他的实时检测模型的两倍。
- YOLO以整张图片作为输入,与R-CNN相比,YOLO的背景错误率降低了一半以上。
- YOLO拥有更好的泛化能力。当YOLO被使用在一个全新的领域,性能依然很好。
统一识别
本文提出的网络,使用整张图片作为输入,用来同时检测多个目标的区域。YOLO实现了实时高性能的端到端的训练。
我们的系统把输入图片分割成 S * S 个小格子,如果某个目标的中心落在这其中的某个小格子中,这个小格子将负责检测出这个目标。
每个格子将会预测出B个Bouding box 和 confidence。confidence代表这个格子包含这个目标的可能性,以及预测出某个目标的可能性。
每个Bounding box 包含5个预测值,(x,y,w,h,confidence)。 (x,y)代表box的中心的相对位置坐标,w 和 h 代表box的相对宽和高。confidence 代表预测出box 和真正的box的IOU值。
每个小格子还包含了C个类别可能性。我们把每个小格子的类别可能性和confidence相乘,就得到了针对于某个特定类的confidence 分值。这个分值既包含了box中出现的目标属于某个类的可能性,又包含了这个box和目标的重叠度。
在PASAL VOC 数据集上,YOLO使用的S 为7, B为2,PASAL VOC 总共有20类物体,因此C为20。因此我们的tensor大小为 7*7*(2 * 5 + 20)。
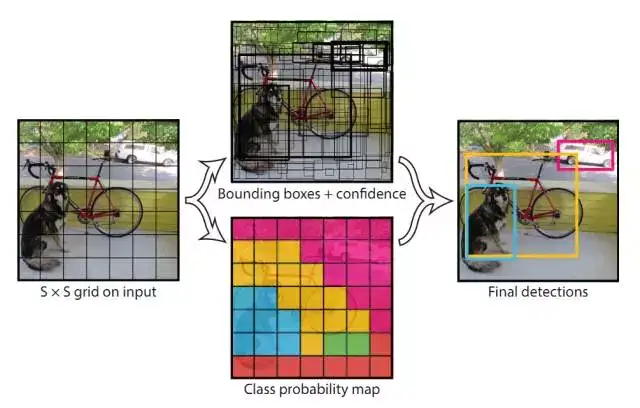
图2 YOLO 模型
2.1 网络设计
我们的网络架构收到GoogLeNet的启发,总共有24个卷积层,2个全联接层。与GoogLeNet不同的是,我们用1*1的reduction 层 和一个 3*3的卷积层取代了inception 模块。 网络的整体结构如下所示:

图3 YOLO 网络架构图
2.2 训练
在ImageNet 1000-class 的竞赛数据上,我们预训练网络的卷积层。预训练过程中,我们用到了上图网络结构中的前20个卷积层,以及后面接了一个average 池化层和全联接层。我们在训练以及推断过程中使用了Darknet框架。
然后,我们把得到的模型用来检测目标。Ren et al. 的研究结果显示,为预训练网络增加卷积层和全联接层能够提高系统性能。因此我们在之前的网络架构上,增加了四个卷积层和两个参数随机初始化的全联接层,检测通常需要细粒度的视觉信息,因此我们将网络的输入分辨率从224×224提高到448×448。
我们的最后一层预测出类别可能性以及bounding box的坐标。我们把bounding box的坐标归一化,我们将边界框x和y坐标参数化为特定网格单元格位置的偏移量,使它们也位于0到1之间。
在最后一层,我们使用了线性整流函数,其余层均适用渗透线性整流函数。在输出层,考虑到 sum-squared error 的缺点,在原有sum-squared error 的基础上,增加了边界框坐标预测的损失,并减少对不包含对象的框的confidence预测的损失。总的损失函数如下所示:
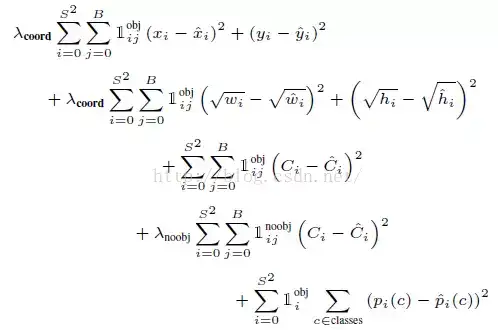
![]()
表示,目标是否出现在格子 i 中。
![]()
表示在格子i中的第j个 Bounding box 的预测值对哪个预测负责。
我们在PASCAL VOC 2007 和 2012 数据集上,训练了135 epochs,训练过程中 batch size 为64,momentum 为0.9, decay 为0.00005。
学习率的变化如下,第一个epoch 徐熙率从 10-3 缓慢增长到10-2, 然后我们继续以10-2的学习率知道第75个epoch,然后以10-3学习率持续了30个epoch,最后以10-4学习率持续了最后30个epoch。
为了避免过拟合,我们使用了dropout 和 extensive data augmentation技术。
2.3 推断过程
和训练过程类似,推断过程也只需要一个网络。在PASCAL VOC 数据集上,我们的网络能够在每张图上预测出98个bounding box, 并给出每个bounding box的属于某一类的可能性。而且跟其他基于分类的目标检测模型对比啊,YOLO的测试时间非常短。
实验测试
3.1 与其他的实时检测系统对别
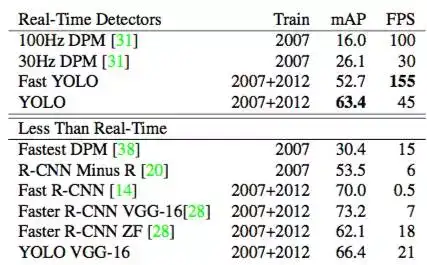
表1 PASCAL VOC 2007 数据集上,不同实时检测系统的性能对比
3.2 将YOLO和R-CNN组合
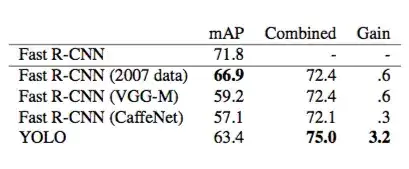
表2 PASCAL VOC 2007 数据集上,将R-CNN 和YOLO结合之后的性能对比
模型分析
4.1 优点
- 检测速度快
- 只使用单个的卷积神经网络
4.2 缺点
- 由于每个网格单元只预测两个Bounding Box并且只能有一个类别,这限制了我们的模型对相互靠近的物体的检测效果。
- 由于我们的模型学习从数据中预测边界框,因此很难将其推广到新的或不寻常的宽高比的其他对象。 我们的模型也使用相对粗糙的特征来预测边界框,因为我们的架构从输入图像有多个下采样层。
- 在一个小的Box中产生的小的误差通常比在一个大的Box中产生的小误差重要的多。然而我们的损失函数却以同样的方式处理这样的误差。我们的误差来源主要是定位误差。