本篇主要演示在Linux上安装单节点Hadoop模式,以及伪分布式Hadoop模式。
一 安装环境
- 操作系统:Oracle Linux Server release 6.5;
- Java版本:java-1.7.0-openjdk-1.7.0.45;
- Hadoop版本:hadoop-2.7.6;
二 安装前准备
1 创建hadoop用户
[root@strong ~]# useradd hadoop
[root@strong ~]# usermod -a -G root hadoop
[root@strong ~]# passwd hadoop
Changing password for user hadoop.
New password:
Retype new password:
passwd: all authentication tokens updated successfully.2 安装SSH,配置SSH免密码登录
1)检查是否安装SSH,若没,则安装;
[hadoop@strong ~]$ rpm -qa|grep ssh
openssh-server-5.3p1-94.el6.x86_64
openssh-5.3p1-94.el6.x86_64
libssh2-1.4.2-1.el6.x86_64
ksshaskpass-0.5.1-4.1.el6.x86_64
openssh-askpass-5.3p1-94.el6.x86_64
openssh-clients-5.3p1-94.el6.x86_642)配置SSH免密码登录
[hadoop@strong ~]$ cd .ssh/
[hadoop@strong .ssh]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
13:df:06:f2:ea:21:31:b2:c1:f8:13:24:c6:bf:45:05 hadoop@strong.hadoop.com
The key's randomart image is:
+--[ RSA 2048]----+
| E.. |
| . . |
| + . . o . |
| . * . = o |
| . * + S o o |
| . B o o . |
| = . o |
| . o . |
| . |
+-----------------+
[hadoop@strong .ssh]$ cat id_rsa.pub >> authorized_keys
[hadoop@strong .ssh]$ chmod 600 authorized_keys
[hadoop@strong .ssh]$ ssh localhost
Last login: Fri Jun 8 19:55:11 2018 from localhost3 安装JAVA
[root@strong ~]# yum install java-1.7.0-openjdk*
在.bash_profile中添加以下内容:
[hadoop@strong ~]$ vim .bash_profile
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.45.x86_64
[hadoop@strong ~]$ . .bash_profile
验证JDK配置是否正确:
[hadoop@strong ~]$ java -version
java version "1.7.0_45"
OpenJDK Runtime Environment (rhel-2.4.3.3.0.1.el6-x86_64 u45-b15)
OpenJDK 64-Bit Server VM (build 24.45-b08, mixed mode)
[hadoop@strong ~]$ /usr/lib/jvm/java-1.7.0-openjdk-1.7.0.45.x86_64/bin/java -version
java version "1.7.0_45"
OpenJDK Runtime Environment (rhel-2.4.3.3.0.1.el6-x86_64 u45-b15)
OpenJDK 64-Bit Server VM (build 24.45-b08, mixed mode)注:Oracle Linux 6.5默认安装的是Java JRE,而不是JDK,为开发方便,则需安装JDK。
三 安装配置Hadoop
1 下载Hadoop软件
[root@strong local]# ll hadoop-2.7.6.tar.gz
-rw-r--r--. 1 root root 216745683 Jun 8 20:20 hadoop-2.7.6.tar.gz2 解压缩
[root@strong local]# tar zxvf hadoop-2.7.6.tar.gz
[root@strong local]# chown -R hadoop:hadoop hadoop-2.7.63 检查Hadoop是否可用,成功则显示版本信息
[root@strong local]# su - hadoop
[hadoop@strong ~]$ cd /usr/local/hadoop-2.7.6
[hadoop@strong hadoop-2.7.6]$ ./bin/hadoop version
Hadoop 2.7.6
Subversion https://shv@git-wip-us.apache.org/repos/asf/hadoop.git -r 085099c66cf28be31604560c376fa282e69282b8
Compiled by kshvachk on 2018-04-18T01:33Z
Compiled with protoc 2.5.0
From source with checksum 71e2695531cb3360ab74598755d036
This command was run using /usr/local/hadoop-2.7.6/share/hadoop/common/hadoop-common-2.7.6.jar4 设置JAVA_HOME变量
在以下文件修改JAVA_HOME
[hadoop@strong hadoop-2.7.6]$ vim etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.45.x86_645 单机配置(非分布式)
Hadoop默认模式是非分布式模式,无须进行其他配置即可运行,非分布式即Java进程,方便进行调试。
1)运行wordcount示例
经过上面四步的设置,已经完成了单机配置,现在演示单机配置下的示例,来体验下Hadoop的功能:
[hadoop@strong hadoop-2.7.6]$ mkdir input
[hadoop@strong hadoop-2.7.6]$ vim ./input/test.txt
[hadoop@strong hadoop-2.7.6]$ cat ./input/test.txt
Hello this is my first time to learn hadoop
love hadoop
Hello hadoop
[hadoop@strong hadoop-2.7.6]$ ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount input output
18/06/08 20:38:44 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
18/06/08 20:38:44 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
18/06/08 20:38:44 INFO input.FileInputFormat: Total input paths to process : 1
18/06/08 20:38:44 INFO mapreduce.JobSubmitter: number of splits:1
18/06/08 20:38:46 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local241325947_0001
18/06/08 20:38:47 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
18/06/08 20:38:47 INFO mapreduce.Job: Running job: job_local241325947_0001
18/06/08 20:38:47 INFO mapred.LocalJobRunner: OutputCommitter set in config null
18/06/08 20:38:47 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
18/06/08 20:38:47 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
18/06/08 20:38:48 INFO mapred.LocalJobRunner: Waiting for map tasks
18/06/08 20:38:48 INFO mapred.LocalJobRunner: Starting task: attempt_local241325947_0001_m_000000_0
18/06/08 20:38:48 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
----------------中间过程省略------------------
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=71
File Output Format Counters
Bytes Written=812)查看运行结果
[hadoop@strong hadoop-2.7.6]$ cat output/*
Hello 2
first 1
hadoop 3
is 1
learn 1
love 1
my 1
this 1
time 1
to 1注:Hadoop默认不会覆盖结果文件,再次运行会出错,提示文件存在,需先将output删除。
四 Hadoop伪分布式配置
Hadoop可以在单节点以伪分布式模式运行,Hadoop进程以分离的Java进程运行,节点即作为NameNode,也作为DataNode,同时,读取的是HDFS文件。
Hadoop的配置文件位于 /usr/local/hadoop-2.7.6/etc/hadoop/中,伪分布式需要修改两个配置文件,分别为core-site.xml和hdfs-site.xml,配置文件xml格式,每个配置以property的name和value设置。
1 修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>2 修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>3 执行NameNode格式化
[hadoop@strong hadoop-2.7.6]$ ./bin/hdfs namenode -format
18/06/08 20:57:45 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = strong.hadoop.com/192.168.56.102
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.7.6
--------------------中间过程省略------------------------
18/06/08 20:57:52 INFO util.GSet: Computing capacity for map NameNodeRetryCache
18/06/08 20:57:52 INFO util.GSet: VM type = 64-bit
18/06/08 20:57:52 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB
18/06/08 20:57:52 INFO util.GSet: capacity = 2^15 = 32768 entries
18/06/08 20:57:52 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1934541033-192.168.56.102-1528462672607
18/06/08 20:57:52 INFO common.Storage: Storage directory /tmp/hadoop-hadoop/dfs/name has been successfully formatted.------------表示格式化成功
18/06/08 20:57:53 INFO namenode.FSImageFormatProtobuf: Saving image file /tmp/hadoop-hadoop/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
18/06/08 20:57:53 INFO namenode.FSImageFormatProtobuf: Image file /tmp/hadoop-hadoop/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 323 bytes saved in 0 seconds.
18/06/08 20:57:53 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
18/06/08 20:57:53 INFO util.ExitUtil: Exiting with status 0 ------------表示格式化成功
18/06/08 20:57:53 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at strong.hadoop.com/192.168.56.102
************************************************************/4 启动NameNode和DataNode进程
[hadoop@strong hadoop-2.7.6]$ sbin/start-dfs.sh
Starting namenodes on [localhost]
localhost: starting namenode, logging to /usr/local/hadoop-2.7.6/logs/hadoop-hadoop-namenode-strong.hadoop.com.out
localhost: starting datanode, logging to /usr/local/hadoop-2.7.6/logs/hadoop-hadoop-datanode-strong.hadoop.com.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
RSA key fingerprint is 68:da:7d:9f:e5:46:14:fc:30:15:9e:24:3d:6e:a9:1d.
Are you sure you want to continue connecting (yes/no)? yes
0.0.0.0: Warning: Permanently added '0.0.0.0' (RSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop-2.7.6/logs/hadoop-hadoop-secondarynamenode-strong.hadoop.com.out启动成功后,查看:
[hadoop@strong hadoop-2.7.6]$ jps
4034 DataNode
4346 Jps
3939 NameNode
4230 SecondaryNameNode5 NameNode节点通过Web访问
默认URL:http://localhost:50070/
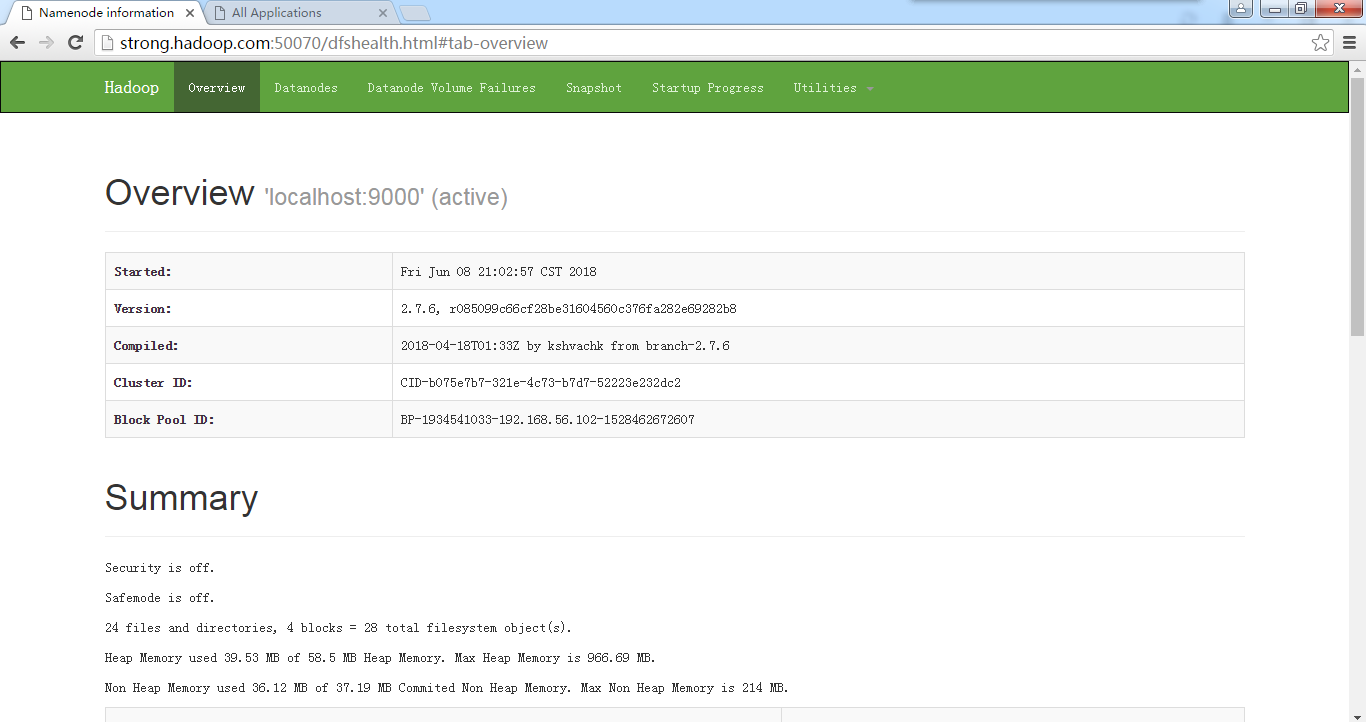
6 运行伪分布式实例
在上面的本地模式,wordcount读取的是本地实例,伪分布式读取的这是HDFS上的数据,要使用HDFS,首先需要在HDFS中创建用户目录。
1)创建用户目录
[hadoop@strong hadoop-2.7.6]$ ./bin/hdfs dfs -mkdir -p /user/hadoop2)拷贝input文件至分布式文件系统
将上面创建的文件etc/test.txt复制到分布式文件系统的/user/hadoop/input中,我们使用的是Hadoop用户,并且已创建相应的用户目录/user/hadoop,因此在命令中可以使用相对路径,其对应的绝对路径为/user/hadoop/input。
[hadoop@strong hadoop-2.7.6]$ ./bin/hdfs dfs -put input/test.txt input
[hadoop@strong hadoop-2.7.6]$ ./bin/hdfs dfs -ls
Found 1 items
-rw-r--r-- 1 hadoop supergroup 71 2018-06-08 21:21 input3) 运行wordcount示例
[hadoop@strong hadoop-2.7.6]$ ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount input output4)查看运行结果
[hadoop@strong hadoop-2.7.6]$ ./bin/hdfs dfs -ls output
Found 2 items
-rw-r--r-- 1 hadoop supergroup 0 2018-06-08 21:24 output/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 69 2018-06-08 21:24 output/part-r-00000
[hadoop@strong hadoop-2.7.6]$ ./bin/hdfs dfs -cat output/*
Hello 2
first 1
hadoop 3
is 1
learn 1
love 1
my 1
this 1
time 1
to 15)Hadoop运行时,输出目录不能存在,否则会出错,删除output
[hadoop@strong hadoop-2.7.6]$ ./bin/hdfs dfs -ls output
Found 2 items
-rw-r--r-- 1 hadoop supergroup 0 2018-06-08 21:24 output/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 69 2018-06-08 21:24 output/part-r-00000
[hadoop@strong hadoop-2.7.6]$ ./bin/hdfs dfs -rm -r output
18/06/08 21:43:01 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted output五 启动YARN
YARN是从MapReduce分离出来的,负责资源管理与任务调度,YARN运行位于MapReduce之上,提供了高可用性、高扩展性。
1配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>2 配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>3 启动ResourceManager进程和NodeManager进程
1)启动YARN
[hadoop@strong hadoop-2.7.6]$ sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop-2.7.6/logs/yarn-hadoop-resourcemanager-strong.hadoop.com.out
localhost: starting nodemanager, logging to /usr/local/hadoop-2.7.6/logs/yarn-hadoop-nodemanager-strong.hadoop.com.out2)开启历史服务器,才能在web中查看任务运行情况
[hadoop@strong hadoop-2.7.6]$ sbin/mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /usr/local/hadoop-2.7.6/logs/mapred-hadoop-historyserver-strong.hadoop.com.out3)查看YARN启动
[hadoop@strong hadoop-2.7.6]$ jps
4034 DataNode
5007 ResourceManager
5422 JobHistoryServer
5494 Jps
3939 NameNode
5108 NodeManager
4230 SecondaryNameNode4)再次运行wordcount示例
[hadoop@strong hadoop-2.7.6]$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount input output
[hadoop@strong hadoop-2.7.6]$ ./bin/hdfs dfs -cat output/*
Hello 2
first 1
hadoop 3
is 1
learn 1
love 1
my 1
this 1
time 1
to 15)在浏览器查看YARN
ResourceManager 默认URL:http://localhost:8088
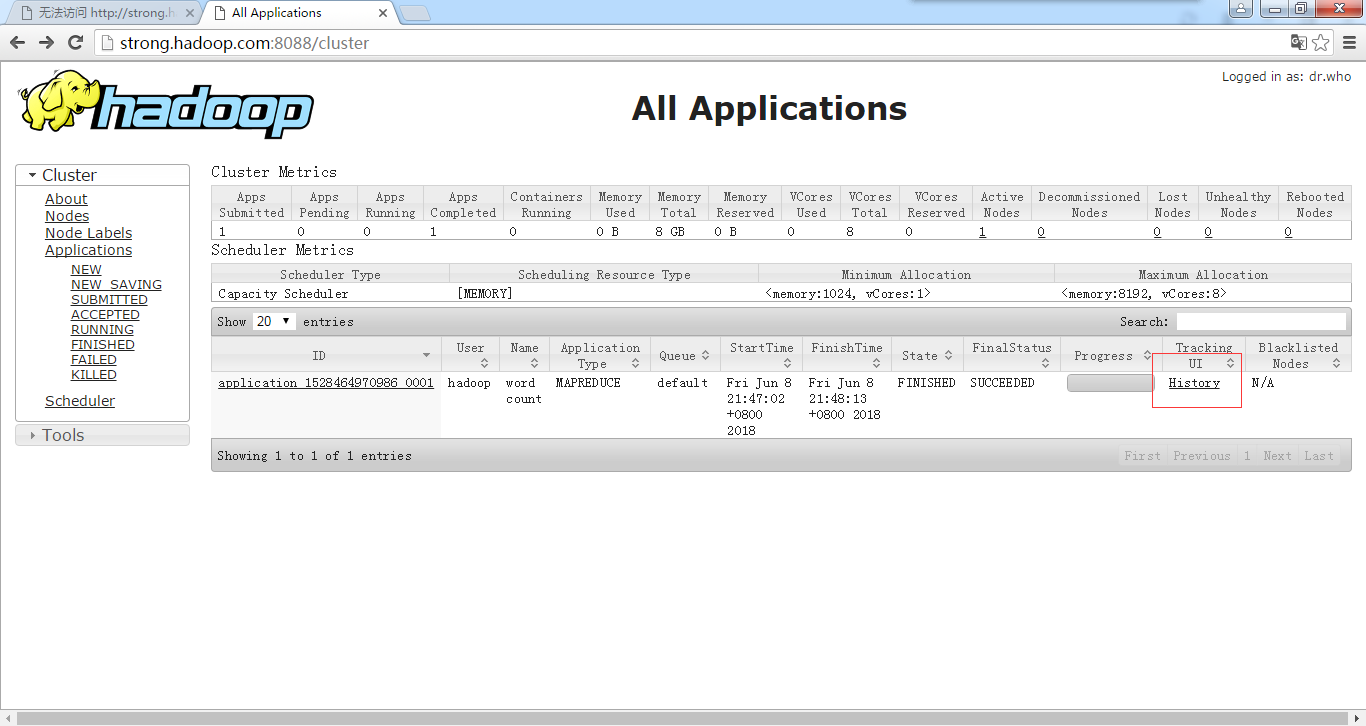
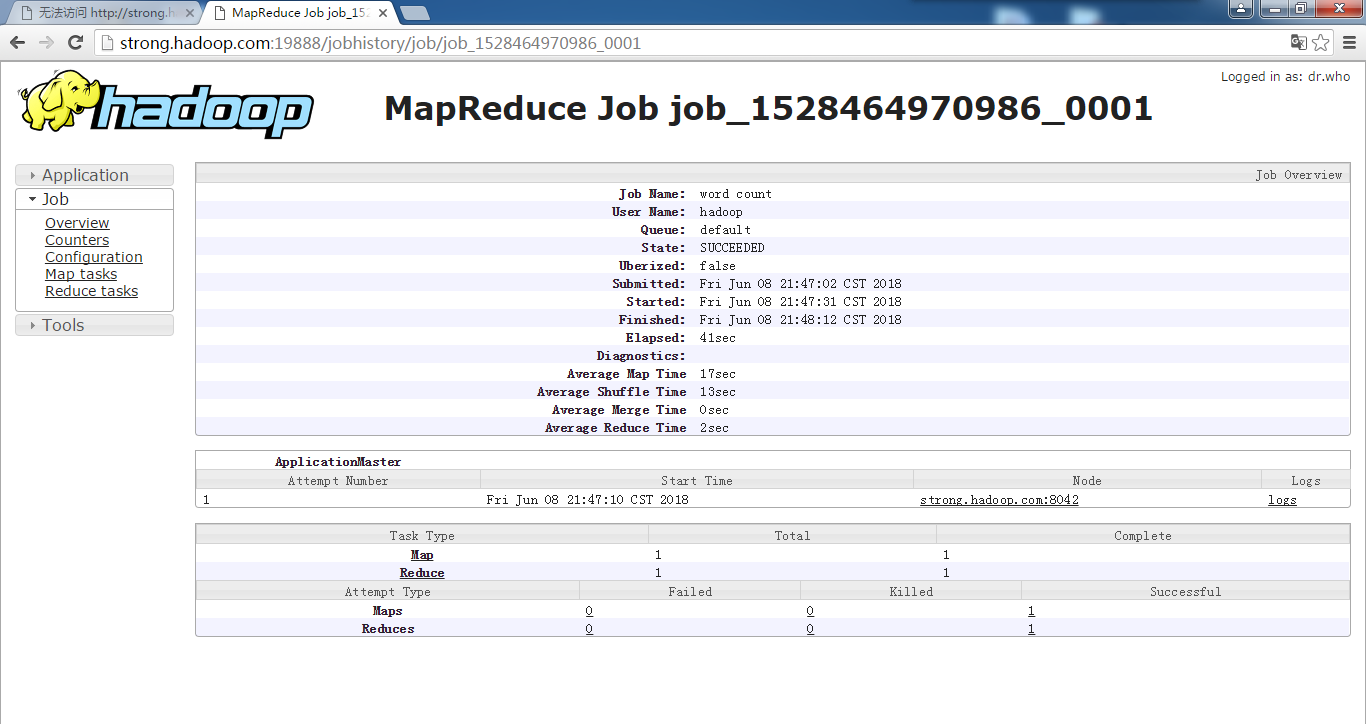
点击上图History,出现如下界面:
至此,Hadoop伪分布式集群安装及配置完成,这个安装只有HDFS、YARN,MapReduce等基本组件。