1. 客户环境
-
节点数量:4个存储节点
-
OSD数量:每个节点10块8GB磁盘,总共 40 块OSD
-
Ceph 版本: Storage 6
-
使用类型: CephFS 文件
-
CephFS 数据池: EC, 2+1
-
元数据池: 3 replication
-
客户端:sles12sp3
2. 问题描述
客户询问为什么突然少了那么多存储容量?
1) 客户在存储数据前挂载cephfs,磁盘容量显示185T
# df -Th 10.109.205.61,10.109.205.62,10.109.205.63:/ 185T 50G 184T 1% /SES
2) 但在客户存储数据后,发现挂载的存储容量少了8T,只有177T
# df -Th 10.109.205.61,10.109.205.62,10.109.205.63:/ 177T 50G 184T 1% /SES
3. 问题分析
从客户获取 “ceph df ”信息进行比较
(1)未存储数据前信息
# ceph df RAW STORAGE: CLASS SIZE AVAIL USED RAW USED %RAW USED hdd 297 TiB 291 TiB 5.9 TiB 5.9 TiB 1.99 TOTAL 297 TiB 291 TiB 5.9 TiB 5.9 TiB 1.99 POOLS: POOL ID STORED OBJECTS USED %USED MAX AVAIL cephfs_data 1 0 B 0 0 B 0 184 TiB cephfs_metadata 2 6.7 KiB 60 3.8 MiB 0 92 TiB
(2)客户存储数据后信息输出
# ceph df RAW STORAGE: CLASS SIZE AVAIL USED RAW USED %RAW USED hdd 297 TiB 239 TiB 57 TiB 58 TiB 19.37 TOTAL 297 TiB 239 TiB 57 TiB 58 TiB 19.37 POOLS: POOL ID STORED OBJECTS USED %USED MAX AVAIL cephfs_data 1 34 TiB 9.75M 51 TiB 19.40 142 TiB cephfs_metadata 2 1.0 GiB 9.23K 2.9 GiB 0 71 TiB
我们发现客户端挂载显示的存储容量 MAX AVAIL + STORED
(1)存储数据前:185TB = 184 + 0
(2)存储数据后:177TB = 142 + 34 = 176
(3)从中可以发现少掉 7TB 数据量是由 ‘MAX AVAIL’引起的变化
(4)SUSE 知识库中对 MAX AVAIL 计算公式如下:
[min(osd.avail for osd in OSD_up) - ( min(osd.avail for osd in OSD_up).total_size * (1 - mon_osd_full_ratio)) ]* len(osd.avail for osd in OSD_up) /pool.size()
(5)命令 ceph osd df 输出信息
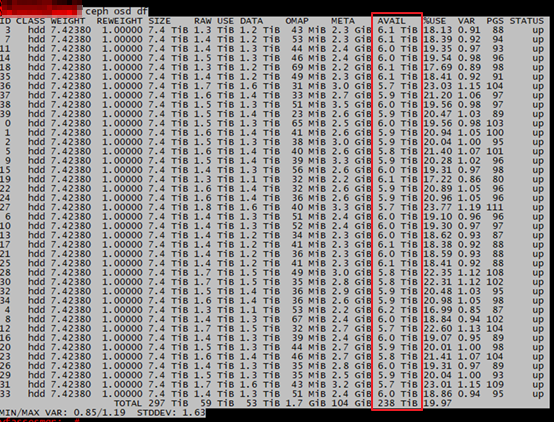
图1
因此可以推算出:
(1)未存储数据之前容量计算:
185 TB (Max avail) = min(osd.avail for osd in OSD_up) * num of OSD * 66.66% * mon_osd_full_ratio = 7.4 * 40 * 66.66% * 0.95= 195 TB * 0.95 =185
(2)存储数据后容量计算
142 TB (MAX avail)= min(osd.avail for osd in OSD_up) * num of OSD * 66.66% * mon_osd_full_ratio = 5.7 * 40 *66.66% * 0.95 = 151 TB * 0.95 = 143
公式解释
1) min(osd.avail for osd in OSD_up):从ceph osd df 中AVAIL一列选择最小值。
- 未存储数据时最小值是7.4TB
- 而存储数据后最小值是5.7TB
2) num of OSD :表示集群中UP状态的OSD数量,那客户新集群OSD数量就40
3) 66.66% : 因为纠删码原因,2+1 的比例
4) mon_osd_full_ratio = 95%
When a Ceph Storage cluster gets close to its maximum capacity (specifies by the mon_osd_full_ratio parameter), Ceph prevents you from writing to or reading from Ceph OSDs as a safety measure to prevent data loss. Therefore, letting a production Ceph Storage cluster approach its full ratio is not a good practice, because it sacrifices high availability. The default full ratio is .95, or 95% of capacity. This a very aggressive setting for a test cluster with a small number of OSDs.
ceph daemon osd.2 config get mon_osd_full_ratio { "mon_osd_full_ratio": "0.950000" }
4. 解决方案
从上面公式分析,我们可以清楚的看到主要是 MAX AVAIL 的计算公式原因导致存储容量的变化,这是浅层次的分析问题所在,其实在图1中我们可以仔细的发现主要是OSD数据不均匀导致。
- 客户询问我如何才能让数据平衡,我的回答是PG数量计算 和 Storage6 自动平衡功能。
(1)开启ceph 数据平衡
# ceph balancer on
# ceph balancer mode crush-compat
# ceph balancer status { "active": true, "plans": [], "mode": "crush-compat" }
(2)数据自动开始迁移
cluster: id: 8038197f-81a2-47ae-97d1-fb3c6b31ea94 health: HEALTH_OK services: mon: 3 daemons, quorum yfasses1,yfasses2,yfasses3 (age 5d) mgr: yfasses1(active, since 5d), standbys: yfasses2, yfasses3 mds: cephfs:2 {0=yfasses4=up:active,1=yfasses2=up:active} 1 up:standby osd: 40 osds: 40 up (since 5d), 40 in (since 5d); 145 remapped pgs data: pools: 2 pools, 1280 pgs objects: 10.40M objects, 36 TiB usage: 61 TiB used, 236 TiB / 297 TiB avail pgs: 1323622/31197615 objects misplaced (4.243%) 1135 active+clean 124 active+remapped+backfill_wait 21 active+remapped+backfilling io: client: 91 MiB/s rd, 125 MiB/s wr, 882 op/s rd, 676 op/s wr recovery: 1.0 GiB/s, 279 objects/s
(3)等迁移后基本所有的OSD数据保持差不多数据量
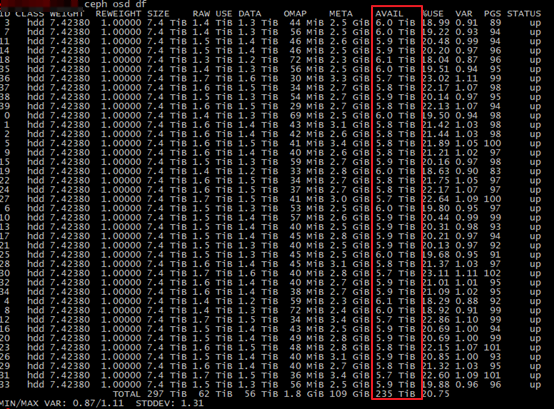
图2
注意:图2截屏时,数据还在迁移中,但可以发现 OSD 之间的数据差距逐渐变小
(4) 客户端挂载显示182TB
等数据迁移完成后,客户端挂载显示182TB
10.109.205.61,10.109.205.62,10.109.205.63:/ 182T 39T 143T 21% /SES
