目录
集群Linux环境搭建
组件版本
- centOS 7.6
- jdk 1.8
- zookeeper 3.4.9
- Hadoop 2.7.5
- mysql 驱动 mysql-connector-java-5.1.38.jar
- hive 2.1.1
- sqoop
- kafka2.11
- Hbase1.4.9
- Sqoop1.4.6
- Kylin2.4
注意事项
- windows系统确认所有的关于VmWare的服务都已经启动(五个)

- 确认好VmWare生成的网关地址:192.168.64.2

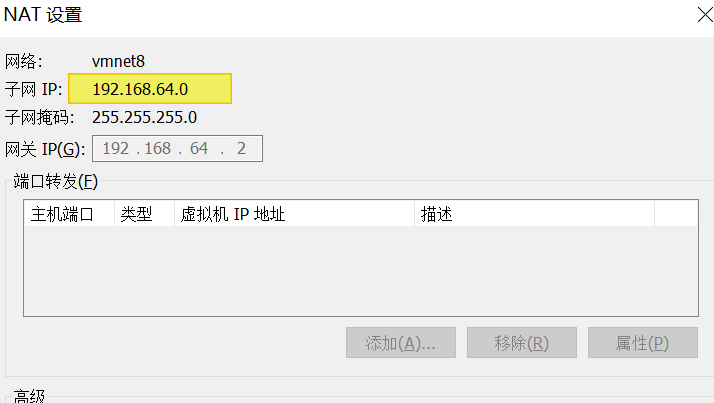
- 确认VmNet8网卡已经配置好了IP地址和DNS
复制虚拟机
- VMWare中新建虚拟机,按步骤操作即可
- 这里选择课程给的虚拟机
- 复制三份,并将文件夹分别重命名为node01,node02,node03
- 双击.vmx文件,则在VmWare中打开,并根据相应文件夹重命名
- 在虚拟机中进行配置三台虚拟机的内存(任务管理器-性能-本机内存为8G),因此每台虚拟机内存分配不能超过2G。设置1G
- 分配最大可占用的磁盘空间,这里40G
- 配置ISO映像文件正确路径(CentOS 64)
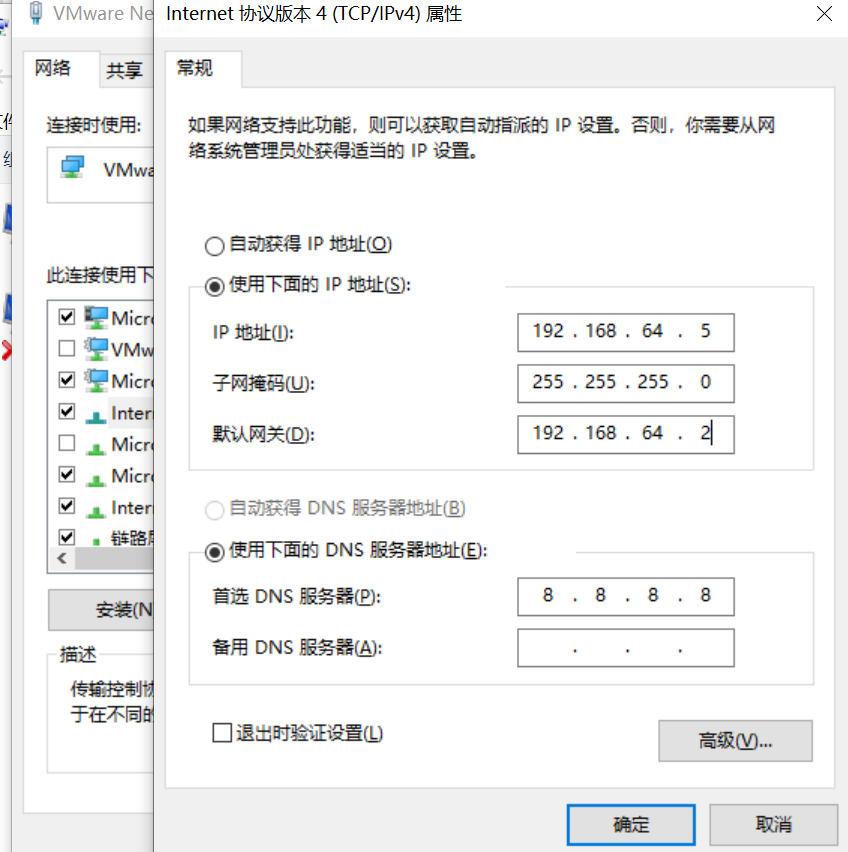
虚拟机修改Mac和IP
网络上解决步骤各异,其实就一句话。只要保证vm virtual machine的.vmx配置文件、ifconfig –a、/etc/sysconfig/network-scripts/ifcfg-eth0、/etc/udev/rules.d/70-persistent-net.rules,所使用的网卡设备和MAC地址一致即可。
- 配置参数列表
| IP | 主机名 | 环境配置 | 安装 |
|---|---|---|---|
| 192.168.64.100 | node01 | 关闭防火墙和SELinux,host映射,时钟同步 | JDK,NameNode,ResourceManager,Zookeeper |
| 192.168.64.110 | node02 | 关闭防火墙和SELinux,host映射,时钟同步 | JDK,NameNode,ResourceManager,Zookeeper |
| 192.168.64.120 | node03 | 关闭防火墙和SELinux,host映射,时钟同步 | JDK,NameNode,ResourceManager,Zookeeper,mysql |
- 打开虚拟机
点击三台虚拟机,选择(CTRL+ALT可在虚拟机和主机间进行切换):我已复制该虚拟机。输入 root 123456,打开 - 每台虚拟机更换MAC地址
打开三台虚拟机设置,查看NAT地址(若相同,则要生成新的)
00:0C:29:3A:F7:FA
00:0C:29:90:5D:AC
00:0C:29:2C:53:90
vim /etc/udev/rules.d/70-persistent-net.rules
三台机器设置成相应的MAC地址,并网卡均设置为eth0
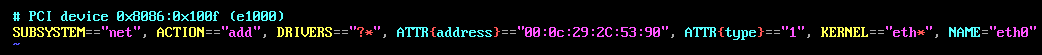
- 每台虚拟机更改IP地址
vim /etc/sysconfig/network-scripts/ifcfg-eth0
改为相应的MAC地址
ONBOOT改为yes:启动时会激活网卡
BOOTROTO设置为static,表示静态IP
配置具体IP参数

* 输入 **reboot 重启**三台主机
* 登录后,输入 ifconfig,查看ip是否正确
* 输入 ping www.baidu.com 查看能否正确联网,CTRL+C结束终止进程
- 每台虚拟机修改对应主机名
vim /etc/sysconfig/network
HOSTNAME=node01
- 每台虚拟机,设置ip和域名映射
打开后,增加图片上的语句
vim /etc/hosts

输入 reboot 重启三台主机
虚拟机关闭防火墙和SELinux
- 使用远程登录工具(secureCRT)
- 三台机器执行以下命令(root用户来执行),来关闭防火墙
service iptables stop #关闭防火墙
chkconfig iptables off #禁止开机启动
- SELinux 是Linux的一种安全子系统(三种工作模式)
- 强制模式:违反规则,则制止,并记录到日志文件
- 宽容模式:违反规则,不制止,记录到日志文件
- 关闭
# 修改selinux的配置文件
vi /etc/selinux/config
# 将其中的模式改为:
SELINUX=disabled
虚拟机免密码登录
- 为什么要免密登录
Hadoop 节点众多, 所以一般在主节点启动从节点, 这个时候就需要程序自动在主节点登录到从节点中, 如果不能免密就每次都要输入密码, 非常麻烦 - 第一步:在三台机器执行以下命令,生成公钥与私钥(按enter 3次)
ssh-keygen -t rsa
- 第二步:拷贝公钥到同一台机器
三台机器将拷贝公钥到第一台机器,三台机器执行命令:
ssh-copy-id node01
- 第三步: 复制第一台机器的认证到其他机器
在第一台机器上面执行以下命令
scp /root/.ssh/authorized_keys node02:/root/.ssh
scp /root/.ssh/authorized_keys node03:/root/.ssh
三台机器时钟同步
# 安装
yum install -y ntp
# 启动定时任务
crontab -e
# 随后在输入界面键入,使其和阿里云服务器保持时钟同步
*/1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com;
辅助软件安装
三台机器安装jdk
SecureCRT View-Command Window,后右击,选择 send command to all sessions
- 查看自带的openjdk并卸载
rpm -qa | grep java
rpm -e java-1.6.0-openjdk-1.6.0.41-1.13.13.1.el6_8.x86_64 tzdata-java-2016j-1.el6.noarch java-1.7.0-openjdk-1.7.0.131-2.6.9.0.el6_8.x86_64 --nodeps
- 创建安装目录
mkdir -p /export/softwares #软件包存放目录
mkdir -p /export/servers #安装目录
- 上传并 解压
# 安装传输工具
yum -y install lrzsz
** 出现 rpm库校验失败或者损坏 错误
** 解决如下
yum clean all
yum makecache
#上传jdk到/export/softwares路径下去,并解压
tar -zxvf jdk-8u261-linux-x64.tar.gz -C ../servers/
- 配置环境变量
vim /etc/profile
# 添加如下内容
export JAVA_HOME=/export/servers/jdk1.8.0_261
export PATH=:$JAVA_HOME/bin:$PATH
# 修改完成之后记得
source /etc/profile
# 使用命令查看是否安装成功
java -version
# 可每台进行相同配置,也可直接拷贝发送,再进行环境变量配置
scp -r jdk1.8.0_261/ node02:$PWD
scp -r jdk1.8.0_261/ node03:$PWD
mysql的安装
- 第一步:在线安装mysql相关的软件包
yum install mysql mysql-server mysql-devel
- 第二步:启动mysql的服务
/etc/init.d/mysqld start
- 第三步:通过mysql安装自带脚本进行设置
/usr/bin/mysql_secure_installation
远程登录及权限表选择 n
- 第四步:进入mysql的客户端然后进行授权
# 在linux上进入客户端
mysql -u root -p
# 授权语句
grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option;
# 刷新MySQL的系统权限相关表
flush privileges;
# 退出
exit;
zookeeper安装
# 安装包下载
# 上传 zookeeper-3.4.9.tar.gz 至 /export/softwares
# 解压至 /export/servers
tar -zxvf zookeeper-3.4.9.tar.gz -C ../servers/
# 修改配置文件
cd /export/servers/zookeeper-3.4.9/conf/
cp zoo_sample.cfg zoo.cfg
mkdir -p /export/servers/zookeeper-3.4.9/zkdatas/
# 修改相应参数
vim zoo.cfg
dataDir=/export/servers/zookeeper-3.4.9/zkdatas
# 保留多少个快照
autopurge.snapRetainCount=3
# 日志多少小时清理一次
autopurge.purgeInterval=1
# 集群中服务器地址
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
# 添加myid配置
# 进入目录,打开myid,输入 1,保存退出
cd /export/servers/zookeeper-3.4.9/zkdatas
vim myid
# 安装包分发并修改 myid 值为 2 3
scp -r /export/servers/zookeeper-3.4.9/ node02:/export/servers/
或者
scp -r /export/servers/zookeeper-3.4.9/ node02:$PWD
scp -r /export/servers/zookeeper-3.4.9/ node03:/export/servers/
# 启动ZK服务
/export/servers/zookeeper-3.4.9/bin/zkServer.sh start
# 查看启动状态
cd /export/servers/zookeeper-3.4.9/bin
zkServer.sh status
Hadoop 安装
| 服务器IP | 192.168.64.100 | 192.168.64.110 | 192.168.64.120 |
|---|---|---|---|
| NameNode | √ | ||
| SecondaryNameNode | √ | ||
| dataNode | √ | √ | √ |
| ResourceManager | √ | ||
| NodeManager | √ | √ | √ |
- NameNode:HDFS 主节点
- SecondaryNameNode 对NameNode 做辅助管理
- dataNode :HDFS从节点,三台都进行安装
- ResourceManager: 分布式计算主节点
- NodeManager : 分布式计算从节点
# 对Hadoop安装包进行编译,使其支持snappy压缩等
[编译后安装包](https://pan.baidu.com/s/1BFQq-qWJOGkB75StVbV_Tw)
提取码:hz4s
# 上传并解压 Hadoop2.7.5至 servers目录下,检测本地库
cd hadoop-2.7.5
bin/hadoop checknative
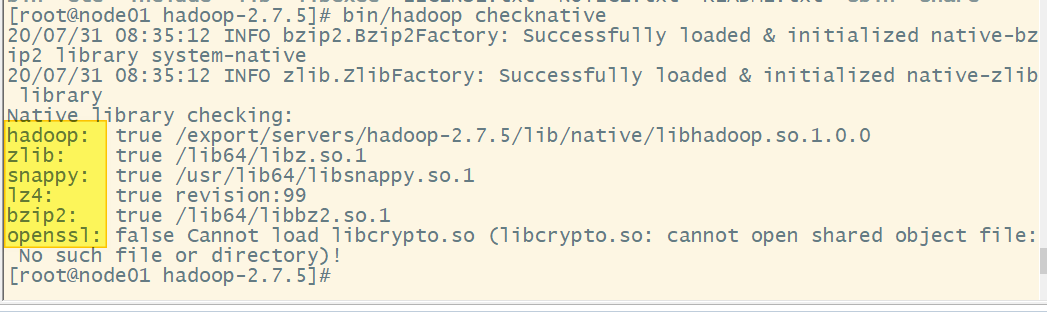
- 修改配置文件(NotePad++ 打开NppFTP窗口,连接服务器,进行操作
# 修改 core-site.xml
<configuration>
<!-- 指定集群的文件系统类型:分布式文件系统 -->
<property>
<name>fs.default.name</name>
<value>hdfs://node01:8020</value>
</property>
<!-- 指定临时文件存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-2.7.5/hadoopDatas/tempDatas</value>
</property>
<!-- 缓冲区大小,实际工作中根据服务器性能动态调整 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>
# 修改 hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
<!-- 指定namenode的访问地址和端口 -->
<property>
<name>dfs.namenode.http-address</name>
<value>node01:50070</value>
</property>
<!-- 指定namenode元数据的存放位置 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas,file:///export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas2</value>
</property>
<!-- 定义dataNode数据存储的节点位置,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas,file:///export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas2</value>
</property>
<!-- 指定namenode日志文件的存放目录 -->
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/nn/edits</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/snn/name</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/dfs/snn/edits</value>
</property>
<!-- 文件切片的副本个数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 设置HDFS的文件权限-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<!-- 设置一个文件切片的大小:128M-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>
# 修改 hadoop-env.sh (仅修改下面这一句)
export JAVA_HOME=/export/servers/jdk1.8.0_261
# 修改 mapred-site.xml
mapred-site.xml.template 重命名为 mapred-site.xml
<configuration>
<!-- 指定分布式计算使用的框架是yarn -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 开启MapReduce小任务模式 -->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<!-- 设置历史任务的主机和端口 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node01:10020</value>
</property>
<!-- 设置网页访问历史任务的主机和端口 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node01:19888</value>
</property>
</configuration>
# 修改 yarn-site.xml
<configuration>
<!-- 配置yarn主节点的位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 开启日志聚合功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置聚合日志在hdfs上的保存时间 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 设置yarn集群的内存分配方案 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
</configuration>
# 修改 mapred-env.sh
增加一句:export JAVA_HOME=/export/servers/jdk1.8.0_261
# 修改slaves
node01
node02
node03
# 执行创建服务数据保存目录
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/tempDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas2
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas2
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/nn/edits
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/snn/name
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/dfs/snn/edits
# Hadoop安装包分发
cd /export/servers/
scp -r hadoop-2.7.5 node02:$PWD
scp -r hadoop-2.7.5 node03:$PWD
# 配置Hadoop环境变量(三台)
vim /etc/profile
# 添加
export HADOOP_HOME=/export/servers/hadoop-2.7.5
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
# 配置生效
source /etc/profile
# 集群启动
cd /export/servers/hadoop-2.7.5/
bin/hdfs namenode -format
sbin/start-dfs.sh
sbin/start-yarn.sh
sbin/mr-jobhistory-daemon.sh start historyserver
# 三个端口查看界面
http://node01:50070/explorer.html#/ 查看hdfs
http://node01:8088/cluster 查看yarn集群
http://node01:19888/jobhistory 查看历史完成的任务

hive安装(node03)
# 上传
cd /export/softwares
# 解压至 /export/servers
tar -zxvf apache-hive-2.1.1-bin.tar.gz -C ../servers/
修改hive的配置文件
# 修改 hive-env.sh
cd /export/servers/apache-hive-2.1.1-bin/conf
cp hive-env.sh.template hive-env.sh
vim hive-env.sh
# 去掉下面两句的注释,并添加相应路径
HADOOP_HOME=/export/servers/hadoop-2.7.5
export HIVE_CONF_DIR=/export/servers/apache-hive-2.1.1-bin/conf
# 新建 hive-site.xml
vim hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node03:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node03</value>
</property>
</configuration>
# 添加mysql的连接驱动包 到hive 的lib目录
cd /export/servers/apache-hive-2.1.1-bin/lib
# 配置 hive 的环境变量
sudo vim /etc/profile
export HIVE_HOME=/export/servers/apache-hive-2.1.1-bin
export PATH=:$HIVE_HOME/bin:$PATH
source /etc/profile
hive 进入方式
1. bin/hive
2.bin/hive -e "create database if not exists mytest;"
- 或者将hql语句写到文本中,再执行
- vim hive.sql
- 写入sql语句
- 执行
bin/hive -f /export/servers/hive.sql
使用 beeline 工具连接hive
# 修改 hadoop(第三台) 的 hdf-site.xml文件
cd /export/servers/hadoop-2.7.5/etc/hadoop
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
# 修改 core-site.xml
vim core-site.xml
# 添加
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
# 将第三台机子上修改的两个配置文件分发给其他两台主机
scp hdfs-site.xml node02:$PWD
scp hdfs-site.xml node03:$PWD
scp core-site.xml node02:$PWD
scp core-site.xml node01:$PWD
# 重启集群
sbin/start-dfs.sh
sbin/start-yarn.sh
# 启动beeline
nohup bin/hive --service hiveserver2 > /dev/null 2>&1 &
# beeline 连接 hiveserver2
bin/beeline
!connect to jdbc:hive2://node03:10000
sqoop 安装(在第三台机器上)
kafka 安装(三台机器)
[kafka 操作与安装](https://www.cnblogs.com/alidata/p/13424939.html)