学习笔记
基于深度学习的自然语言处理(中文版)-- 车万翔 等译
基本概念
- 在语言处理中,向量 x 来源于文本数据,能够反映文本数据所具有的多种语言学特征
- 从文本数据到具体向量的映射称为 “特征提取” 和 “特征表示”,通过 “特征方程” 所完成
- 对语言数据,其以一些列离散的符号形式存在,这个序列需要使用微妙的方法转换成为一个数值向量
NLP 分类问题中的拓扑结构
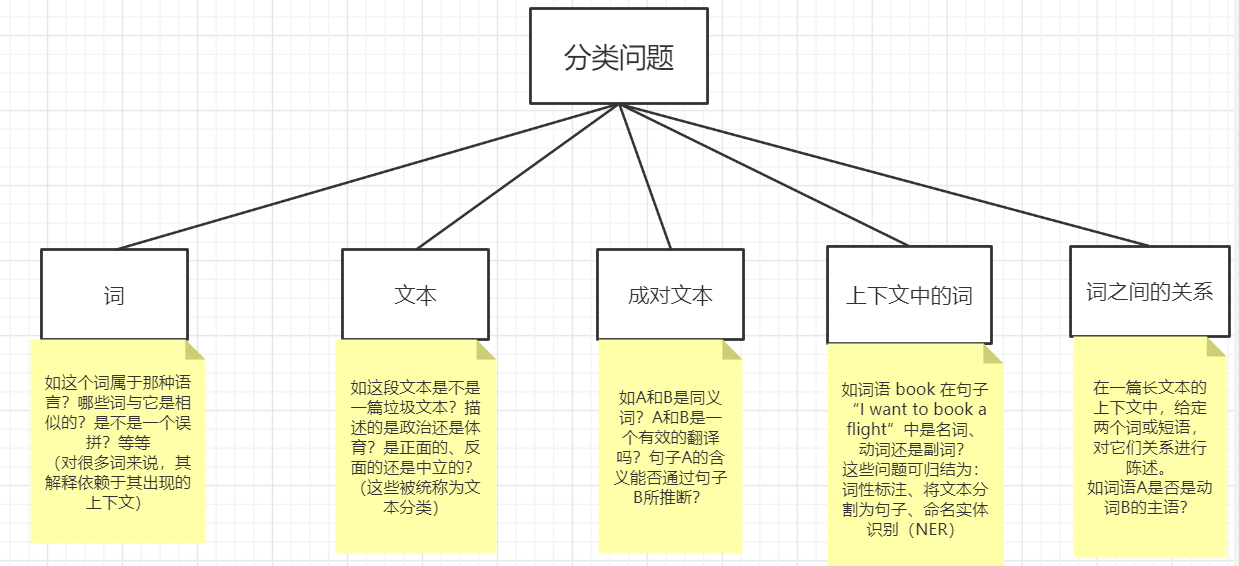
这些分类样例能够被扩展为 结构化问题,我们感兴趣的是执行相关的分类决策,以使得一个决策能够影响另一个决策
扩展 -- 关于 词(word) 的定义探讨
一个定义是:被空白符和标点符号分割的文本(基于英文,但没有考虑缩写(I.B.M)和称谓(Mr.)这些不需要分割的例子)
另一个定义是(从文本的写作方式上):将词看作 “语义的最小单元”。
以此,可看出通过空白符和标点符号分割的文本是有问题的,类似于 “don't”,事实上是 “do not” 两个词合并为一个符号,以及 “New York” 是一个词还是两个词? “ice cream"、”ice-cream“ 和 ”icecream“ 是一样的吗?
因此,引出 词(word)和 符号串(token)的概念区别:
- 分词器的输出称为 token
- 带有语义的单元称为 word
- 一个符号串可能会有多个词组成,多个符号串也可能是一个词
- 一些不同的符号串可能是同一个潜在的词
NLP 问题中的特征
特征通常表现为 标量(indicator)和 可数(count)的形式
标量特征经常取 0 和 1 值,其取决于某种条件是否出现(如 ”dog" 这个词至少出现1次于文本中,特征取 1,否则取 0)
可数特征的取值取决于给定一个事件出现的频率(如 “dog” 在文本中出现的次数)
直接可观测特征
-
单独词特征:独立于上下文,主要信息来源于组成词的字符和它们的次序,以及从中导出的属性(单词的长度、单词的字形(大小写)、词的前缀和后缀)
-
词元和词干
词元(字典条目),将词语的不同形式(如 booking,booked,books)映射到它们通用词元 book。这种映射可由词元集或形态分析器完成,但对于不出现于词元集中的词或是拼写错误的词并不能很好地进行处理
词干提取,更一般化的过程,能够在任何字符串序列上起作用,,它以特定语言的启发式规则将词序映射为更短的序列,以至于将不同的影响映射为相同的序列,并且词干提取的结果不需要是一个有效的词(如 “picture”、“pictured”、“pictures” 都会被词干化为 “pictur”)
-
词典资源
它包含典型的词信息,并将它们和其他词语连接起来或者提供额外的信息
常用的一些英文词典资源(它们各自的侧重点有所不同):WordNet、FrameNet、VerbNet、Paraphrase(PPDB)等
有效的使用符号信息是任务相关的,经常需要繁琐的工程和技巧去处理,目前它们不经常应用于神经网络模型中
-
分布信息
哪些词的行为和当前词的行为是类似的
-
-
文本特征:字符和词在文本中的数量和次序
-
词袋(bag-of-word,BOW)
观察词在文档中出现的柱状图,即考虑每个词作为特征的数量,并将词抽象为基本的元素(element)
-
权重
结合基于外部信息的统计结果,集中考虑那些在给定的文本中经常出现的词,并且它们在外部文本中出现的次数相对较少(这可将那些在文本中经常出现的词(如 a 和 for),与和文本主题相关的词区分开)
经常使用 TF-IDF 算法计算权重
-
-
上下文词特征:考虑词在句子和文本中时,一个能够直接观测到的词的特征就是其在句子中的位置,围绕它的词和字符也可作为特征,与目标词越近,该词具有的信息量相对于远处的词越丰富(当然也存在着词间的长距离约束)
-
窗口
围绕词的窗口聚焦于词的直接上下文(即目标词每侧的 k 个词,k可设为 2、5、10),之后使用特征来代表出现在窗口内的词
如 考虑句子 (PHP is the best programming language in the world.)k=2,目标词为 programming
那么一个特征集合为 {word=the,word=best,word=language,word=in}
固定大小的窗口放松了 BOW 假设,它不考虑词的次序,而是考虑词出现的窗口在文本中的相对位置,从而产生了位置相关特征。如词 X 出现在目标词左侧的两个词语内,那么在上面的例子中,窗口位置方法将抽取特征集合 {word-2=the,word-1=best,word+1=language,word+2=in}
-
位置
这里指的是 绝对位置。如 目标词是句子中的第5个词的特征,或者一个二进制版本,能够表示粗粒度的类别信息:是否出现在前10个词中或是否在第10个词和第20个词之间等
-
-
词关系特征
当考虑上下文中的两个词时,除了每个词的位置和围绕它们的词外,还能够观察词之间的距离和它们之间的代表词
可推断的语言学特征
句子除了是词语的线性排序外还是有结构的,这种结构遵循复杂的不易于直接观察到的规律,可被归结为语法
主要可分为:词类(词性标签)、形态学、语法以及部分语义信息
常用的一些语言标注形式:成分树(短语结构树)、句法依存树
从句子级别更近一步的话,考虑篇章之间的关系,而篇章关系可用于揭示句间的关系,如 解释(Elaborations)、相对(Contradiction)、因果(CauseEffect)等。这些关系经常被句间的连接词所揭示,如 “并且(moreover)”、“然而(however)”以及 “和(and)”,同时也会被不直接的线索所揭示。
在深度学习发展的今天,语言学的属性特征是否还有必要?
在充足的数据和引导方向正确的情况下,很多语言学的概念是可以被网络学到的,但我们往往不能够得到足够的训练数据,此时,为网络提供更加明确的、清晰的概念将会非常有用,同时也可以以它们作为补充的监督去指导网络应用于多任务学习中
核心特征与组合特征
仅考虑神经网络(非线性模型),模型设计者能够仅指定核心特征集合,然后依赖网络训练过程去选择重要的组合。但在很多实际案例中,结合有效的人工构造特征的线性分类器性能是很好的
n 元组特征
即 n-gram 模型,常用的是 n = 2、3
在一般情况下,MLP 这样的神经网络结构不能依靠自身从文本中推断除 n 元组特征,如从文本中得到 bag-of-words 特征向量作为输入,学习到如 词语 X 出现在文本中和词语 Y 出现在文本中 这种组合,而不是 二元组 XY 出现在文本中,因此,n 元组特征对非线性分类器是有用的
当 n 元组应用于带有位置信息的固定大小的窗口时,多层感知机能够推断出 n 元组特征,如 CNN,被设计用来基于一个改变长度的词序列寻找针对特定任务的更加有信息量的 n 元组特征
分布特征
词是离散的和不相关的符号
对词类型的泛化,可以将它们映射到粗粒度的类别,像是词性或语义角色(“the, a, an, some”都是限定词);将易改变的词语映射到词元(“book”、“booking”、“booked”都含有词元 “book”);但这些策略是非常有限的,很难再进行细粒度的划分(如 “pizza” 与 “burger” 的相似度要高于其与 “icecream” 的相似度)
语言的分布假设指的是 词 的含义能够从它的上下文推断出来(如 burger 出现的上下文和 pizza 出现的上下文是相似的,而其和 icecream 出现的上下文的相似度很小,和 chair 出现的上下文完全不相同),通过词出现的上下文去学习词的归一化,这些方法可以被归结为基于聚类的方法,其将相似的词归类到一个类别中,然后以其类别成员属性代表每个词
另一种相似的方法是 词嵌入,它将每个词表示为一个向量,这样相似的词(拥有相似分布的词)会有相似的向量