Spark是一个分布式内存计算框架,可部署在YARN或者MESOS管理的分布式系统中(Fully Distributed),也可以以Pseudo Distributed方式部署在单个机器上面,还可以以Standalone方式部署在单个机器上面。运行Spark的方式有interactive和submit方式。本文中所有的操作都是以interactive方式操作以Standalone方式部署的Spark。具体的部署方式,请参考Hadoop Ecosystem。
HDFS是一个分布式的文件管理系统,其随着Hadoop的安装而进行默认安装。部署方式有本地模式和集群模式,本文中使用的时本地模式。具体的部署方式,请参考Hadoop Ecosystem。
目标:
能够通过HDFS文件系统在Spark-shell中进行WordCount的操作。
前提:
存在一个文件,可通过下面的命令进行查看。
hadoop fs -ls /

如果不存在,添加一个(LICENSE文件需要在本地目录中存在)。更多hadoop命令,请参考hadoop命令。
hadoop fs -put LICENSE /license.txt
通过Web Browser查看Hadoop是否已经运行。
http://localhost:50070

步骤:
Step 1:进入Spark-shell交互式命令行。
spark-shell
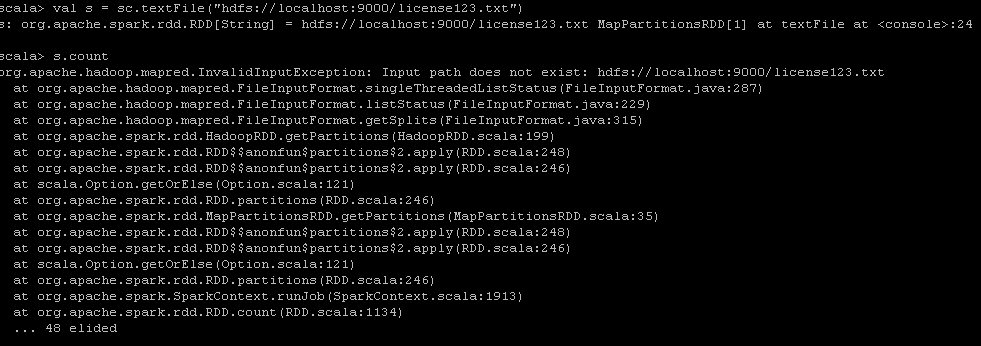
Step 2:读取license.txt文件,并check读取是否成功。如果不存在,则提示如下错误。
val s = sc.textFile("hdfs://localhost:9000/license.txt")
s.count
Step 3:设定输出的文件个数并执行统计逻辑
val numOutputFiles = 128
val counts = s.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _, numOutputFiles)
Step 4:保存计算结果到HDFS中
counts.saveAsTextFile("hdfs://localhost:9000/license_hdfs.txt")
Step 5:在shell中查看结果
hadoop fs -cat /license_hdfs.txt/*
结论:
通过HDFS,我们可以在Spark-shell中轻松地进行交互式的分析(word count统计)。
参考资料:
http://hadoop.apache.org/docs/r1.0.4/cn/commands_manual.html
http://spark.apache.org/docs/latest/programming-guide.html
http://coe4bd.github.io/HadoopHowTo/sparkScala/sparkScala.html
http://coe4bd.github.io/HadoopHowTo/sparkJava/sparkJava.html