CPU的性能测试
# yum install gcc gcc-c++ automake make libtool
$ cd /tmp && git clone https://github.com/akopytov/sysbench.git
注意要下载特定版本的话,登录github做个调整
$ cd /tmp/sysbench && ./autogen.sh
# ./configure --without-mysql
$ make
$ make install
安装时,如遇到:/usr/share/automake-1.13/am/library.am: warning: 'libsbdrizzle.a': linking libraries using a non-POSIX错误;
解决办法:
编辑configure.ac,在AM_PROG_CC_C_O下添加AM_PROG_AR
sysbench --test=cpu --cpu-max-prime=500000 run --num-threads=100
测试结果:
# sysbench --test=cpu --cpu-max-prime=500000 run --num-threads=100
sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options:
Number of threads: 100
Random number generator seed is 0 and will be ignored
Prime numbers limit: 500000
Initializing worker threads...
Threads started!
General statistics:
total time: 1356.4892s
total number of events: 10000
total time taken by event execution: 135415.4854s
response time:
min: 9276.10ms
avg: 13541.55ms
max: 45887.28ms
approx. 95 percentile: 14689.66ms
Threads fairness:
events (avg/stddev): 100.0000/4.63
execution time (avg/stddev): 1354.1549/2.20
磁盘性能测试
安装fio
# yum install gcc libaio-devel
下载fio v2.1 http://freecode.com/projects/fio/
# tar -zxvf fio-2.1.10.tar.gz
# cd fio-2.1.10
# make && make install
(1)8K随机读:
例:fio -filename=/dev/sda -direct=1 -iodepth 10 -thread -rw=randread -ioengine=psync -bs=8k -size=10G -numjobs=20 -runtime=300 -group_reporting -name mytest
(2)8K随机写:
例:fio -filename=/dev/sda -direct=1 -iodepth 10 -thread -rw=randwrite -ioengine=psync -bs=8k -size=10G -numjobs=20 -runtime=300 -group_reporting -name mytest
(3)8K混合读写模型(70%读/30%写):
例:fio -filename=/dev/sda -direct=1 -iodepth 10 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=8k -size=10G -numjobs=20 -runtime=300 -group_reporting -name mytest
(4)64K顺序读:
例:fio -filename=/dev/sda -direct=1 -iodepth 10 -thread -rw=read -ioengine=psync -bs=64k -size=10G -numjobs=20 -runtime=300 -group_reporting -name mytest
(5) 64K顺序写:
例:fio -filename=/dev/sda -direct=1 -iodepth 10 -thread -rw=write -ioengine=psync -bs=64k -size=10G -numjobs=20 -runtime=300 -group_reporting -name mytest
说明:
filename=/dev/sdb1 测试文件名称,通常选择需要测试的盘的data目录。 只能是分区,不能是目录,会破坏数据。使用fdisk -l查看分区
direct=1 测试过程绕过机器自带的buffer。使测试结果更真实。
rw=randwrite 测试随机写的I/O
rw=randrw 测试随机写和读的I/O
bs=16k 单次io的块文件大小为16k
bsrange=512-2048 同上,提定数据块的大小范围
size=5G 本次的测试文件大小为5g,以每次4k的io进行测试。此大小不能超过filename的大小,否则会报错。
numjobs=30 本次的测试线程为30个.
runtime=1000 测试时间为1000秒,如果不写则一直将5g文件分4k每次写完为止。
ioengine=psync io引擎使用pync方式
rwmixwrite=30 在混合读写的模式下,写占30%
group_reporting 关于显示结果的,汇总每个进程的信息。
lockmem=1G 只使用1g内存进行测试。
zero_buffers 用0初始化系统buffer。
nrfiles=8 每个进程生成文件的数量。
测试结果解读:
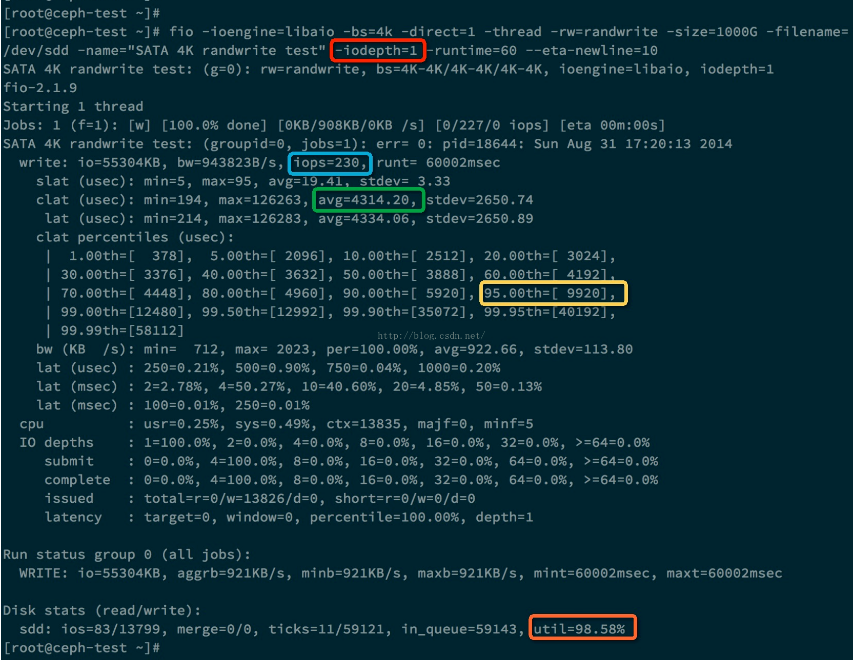
上图中蓝色方框里面的是测出的IOPS 230, 绿色方框里面是每个IO请求的平均响应时间,大约是4.3ms。黄色方框表示95%的IO请求的响应时间是小于等于 9.920 ms。橙色方框表示该硬盘的利用率已经达到了98.58%。bw这个是带宽。
测试的项包括(可以只测试4k和64k这两项):
4k,8k,16k:(1)100%随机读/ (2)100%随机写/ (3)70%随机读+30%随机写
64K,128K,512K:(1)100%顺序读/ (2)100%顺序写
网卡性能测试
在客户端和服务端,安装iperf
TCP测试
服务器执行:#iperf -s -i 1 -w 1M
客户端执行:#iperf -c 192.168.0.241 -i 1 -w 1M
(或者在服务端执行:#clush –g srv “iperf -c 192.168.0.241 -i 1 -w 1M”)
其中-w表示TCP window size,192.168.0.241为服务器地址。
UDP测试
服务器执行:#iperf -u -s
客户端执行:#iperf -u -c 192.168.0.241 -b 900M -i 1 -w 1M -t 60
(或者在服务端执行:#clush –g srv “iperf -u -c 192.168.0.241 -b 900M -i 1 -w 1M -t 60”)
其中-b表示使用带宽数量,千兆链路使用90%容量进行测试就可以了。
内存测试
软件编译:gcc -mtune=native -march=native -O3 -mcmodel=medium -fopenmp -DSTREAM_ARRAY_SIZE=100000000 -DNTIMES=10 stream.c -o stream.o
运行stream测试指令./stream.o
具体解释:
参考链接:https://blog.csdn.net/ztq157677114/article/details/51940983
Stream介绍
Stream测试是内存测试中业界公认的内存带宽性能测试基准工具,作为衡量服务器内存性能指标的通用工具。通过测试过程了解相关参数并记录如下(主要是编译过程的参数值设置),关于stream介绍可以参考如下官方网页
http://www.cs.virginia.edu/stream/ref.html
Stream的源码下载地址
http://www.cs.virginia.edu/stream/FTP/Code/我们下载stream.c源程序即可
编译参数介绍
在介绍测试过程前,需要了解CPU cache memory,L3 cache大小直接决定了编译时的参数值大小。
测试环境2路Intel(R) Xeon(R) CPU E5-2680 v3 @ 2.50GHz CPU,
gcc -mtune=native -march=native -O3 -mcmodel=medium -fopenmp -DSTREAM_ARRAY_SIZE=<num> -DNTIMES=<num> -DOFFSET=<num> stream.c -o stream.o
参数介绍:
1. -mtune=native -march=native
针对CPU指令的优化,由于测试编译机即运行机器,故采用native的优化方法
2. -O3
优化级别
3. -mcmodel=medium
当单个Memory Array Size 大于2GB时需要设置此参数
-fopenmp
适应多处理器环境;开启后,程序默认线程为CPU线程数,也可以运行时也可以动态指定运行的进程数 :export OMP_NUM_THREADS=12 #12为自定义的要使用的处理器数
-DSTREAM_ARRAY_SIZE
计算方法参考stream.c中的说明 例如本环境中查询cpu资料 L3
缓存 35MB
其值为 35000000,这个值可以大于L3的缓存,可以默认使用-DSTREAM_ARRAY_SIZE=100000000
-DNTIMES
执行次数,并从所有结果中取最优
-DOFFSET=4096
数组的偏移,一般可以不设置
注意测试时改变size大小,cpu个数,多测几组数据取平均值