基本概念
-
并发:指一个时间段内,有几个程序在同一个cpu上运行,但是任意时刻只有一个程序在cpu上运行。比如说在一秒内cpu切换了100个进程,就可以认为cpu的并发是100。
-
并行:指任意时刻点上,有多个程序同时运行在cpu上,可以理解为多个cpu,每个cpu独立运行自己程序,互不干扰。并行数量和cpu数量是一致的。
-
同步: 指调用IO操作时(注意同步和异步只是针对于I/O操作来讲的),必须等待IO操作完成后才开始新的的调用方式。
-
异步:指调用IO操作时,不必等待IO操作完成就开始新的的调用方式。
-
阻塞: 指调用函数的时候,当前线程被挂起。
-
非阻塞: 指调用函数的时候,当前线程不会被挂起,而是立即返回。
协程是什么?
协程(coroutine),又称为微线程,纤程。协程的作用:在执行A函数的时候,可以随时中断,去执行B函数,然后中断继续执行A函数(可以自动切换),单着一过程并不是函数调用(没有调用语句),过程很像多线程,然而协程只有一个线程在执行
优缺点
优点:
1、不需要锁,因为协程就只有一个线程,不存在竞争关系
2、效率高,协程是切换函数执行,没有多进程/多线程切换进程/线程的开销
缺点:
1、无法利用多核,从上面可以知道协程是一个线程,切换的是函数执行
2、其实就是一个程序,执行过程中中断切换到另一个执行函数,然后返回中断的地方继续执行,如果发生阻塞操作那就是阻塞整个程序了
发展过程
1. yield/send # 生成器模式,推荐学习一下生成器模式的协程,能过帮助理解执行原理
2. yield from # 新增委派
3. async/await # python3.5+新增关键字,主要替代2中协程装饰器机yield from
我这里主要介绍原生特性async/await 及标准库asyncio(异步)
还有一些第三方库gevent等
async/await关键字
async: 是定义协程函数的关键字,async def,会将函数标记为协程函数
await
使用示例
我这里先写个简单的看下效果
async def funct(index):
print("start ", index)
await asyncio.sleep(5) # 睡眠5秒
print("end ", index)
if __name__ == "__main__":
# async
print("async test")
start = time.time()
# 启动10个协程
p_list = [funct(i) for i in range(10)]
# 创建事件循环
loop = asyncio.get_event_loop()
# 直到协程任务全部完成才退出循环
loop.run_until_complete(asyncio.gather(*p_list))
print("async time ", time.time() - start)
我们先思考下,按照多任务并发,我们预期是全部一起运行,那总耗时应该在5秒这样的
多进程/多线程的代码可能就很好理解,这里就任务函数加了async/await关键字,会像多进程/多线程那样无序并发的运行吗?我们来看结果吧
async test start 2 start 6 start 0 start 7 start 1 start 8 start 3 start 9 start 4 start 5 end 2 end 0 end 3 end 5 end 4 end 8 end 9 end 1 end 6 end 7 async time 5.003999948501587
可以看出运行结果跟多进程/多线程是一样的效果的,很神奇吧,明明就启动了一个线程,这是怎么做到的呢
协程运行原理
从代码中看,任务执行到 await asyncio.sleep(5) 的时候就会被挂起,然后去执行其他空闲的协程,从而实现并发,起到重要作用的是loop事件循环对象,主要监控跟调度协程执行的,基本流程是这样的
1、启动协程,执行到await位置挂起
2、控制权返回给事件循环对象,查询空闲协程
3、返回步骤1,
流程图
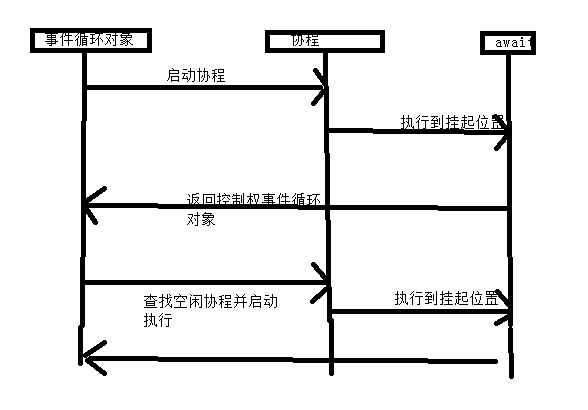
从而实现多进程多线程的并发效果,主要是把耗时的 I/O 操纵异步处理,这时就由事件循环控制其他协程继续执行
爬虫示例
# -*- coding=utf-8 -*-
import asyncio
from queue import Queue
import time
import aiohttp
from lxml import etree
import requests
# 创建队列保存结果
q = Queue()
async def send_request(url):
'''
用来发送请求的方法
:return: 返回网页源码
'''
headers = {
'Host': 'movie.douban.com',
'Referer': 'https://movie.douban.com/top250?start=225&filter=',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36',
}
# 请求出错时,重复请求3次,
i = 0
while i <= 3:
try:
print("[INFO]请求url:"+url)
async with aiohttp.ClientSession() as session:
async with session.get(url, timeout=5) as resp:
return await resp.text()
except Exception as e:
print('[INFO] %s %s'% (e, url))
i += 1
async def parse_page(url):
'''
解析网站源码,并采用xpath提取 电影名称和平分放到队列中
:return:
'''
response = await send_request(url)
html = etree.HTML(response)
# 获取到一页的电影数据
node_list = html.xpath("//div[@class='info']")
for move in node_list:
# 电影名称
title = move.xpath('.//a/span/text()')[0]
# 评分
score = move.xpath('.//div[@class="bd"]//span[@class="rating_num"]/text()')[0]
# 将每一部电影的名称跟评分加入到队列
q.put(score + " " + title)
def main():
base_url = 'https://movie.douban.com/top250?start='
# 构造所有url
url_list = [parse_page(base_url+str(num)) for num in range(0,225+1,25)]
# 创建协程并执行
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.gather(*url_list))
while not q.empty():
print(q.get())
if __name__=="__main__":
start = time.time()
main()
print('[info]耗时:%s'%(time.time()-start))
执行结果
............. 9.2 大话西游之大圣娶亲 9.3 熔炉 9.2 龙猫 9.2 无间道 9.2 疯狂动物城 9.3 教父 9.1 当幸福来敲门 9.1 怦然心动 9.2 触不可及 [info]耗时:0.6089999675750732
爬取250条记录,用时半秒多,还是很给力的
注意
协程发起网络请求需要使用aiohttp,基于协程开发的,requests是同步的,不支持协程
看到有大神说这样可以用,使用run_in_executor执行requests发起网络请求,https://stackoverflow.com/questions/22190403/how-could-i-use-requests-in-asyncio
asyncio.get_event_loop().run_in_executor(None, requests.get, url)
这里写了个示例
# encoding=utf-8
import asyncio
import functools
import requests
async def req(url):
headers = {
'Host': 'movie.douban.com',
'Referer': 'https://movie.douban.com/top250?start=225&filter=',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36',
}
resp = await asyncio._get_running_loop().run_in_executor(None,
functools.partial(requests.get,
allow_redirects=False,
headers=headers),
url)
print(reqeust->{}, status:{}".format(url, resp.status_code))
if __name__ == "__main__":
base_url = 'https://movie.douban.com/top250?start='
# 构造所有url
url_list = [req(base_url + str(num)) for num in range(0, 225 + 1, 25)]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.gather(*url_list))
执行结果如下
reqeust->https://movie.douban.com/top250?start=175, status:200 reqeust->https://movie.douban.com/top250?start=0, status:200 reqeust->https://movie.douban.com/top250?start=200, status:200 reqeust->https://movie.douban.com/top250?start=150, status:200 reqeust->https://movie.douban.com/top250?start=125, status:200 reqeust->https://movie.douban.com/top250?start=100, status:200 reqeust->https://movie.douban.com/top250?start=225, status:200 reqeust->https://movie.douban.com/top250?start=25, status:200 reqeust->https://movie.douban.com/top250?start=50, status:200 reqeust->https://movie.douban.com/top250?start=75, status:200