Building Auto-Encoder Intrusion Detection System based on random forest feature selection.
构建基于随机森林特征选择的AE-IDS
abstract
机器学习技术在入侵检测中应用广泛,但这些技术尚面临着缺乏标记数据集、开销大和精度低的问题。为了提高分类精度、减少训练时间,本文提出了一种有效的深度学习方法,即基于随机森林算法的AE-IDS (Auto-Encoder Intrusion Detection System)--该方法采用特征选择和特征分组的方法构造训练集。训练后,该模型可以使用自动编码器对结果进行预测,大大减少了检测时间,有效提高了预测精度。实验结果表明,该方法训练简单,适应性强,检测精度高,从而优于传统的基于机器学习的入侵检测方法。
introduction
一、目前NIDS存在的问题:
1.检测率不稳定
2.对新攻击类型 / 新投放环境的适应性差
3.数据处理效率低
因此,本文计划提出一个基于自动编码器的轻量自编码入侵检测系统:(1)随机森林算法--选择特征,减小数据维度,提高数据质量(2)亲和力传播算法--划分特征子集(3)自动编码器--重构新数据,计算RMSE(4)GMM/K-means--实现分类。
本文的主要贡献:(1)在线检测,可直接使用步骤(1)中所选择的特征
(2)找到数据之间的强相关性,每个特征子集中数据量大小相近
(3)3层浅层AE神经网络,减小计算复杂度,轻量
(4)使用无监督聚类算法,但AE可用于提升聚类准确性。
related work
二、NIDS需要解决的问题
1.如何标记训练集会对系统acc造成影响,而标记数据的代价高昂。
2.数据的计算/数据的保存问题。
3.属性/特征选择问题:人工/机器自动选择?
4.KDD 99/NSL-KDD过时问题
5.减小数据所需内存问题:减维度
6.离线/在线,轻量/非轻量问题
7.数据去噪问题
三、为什么选择CSE-CIC-IDS 2018数据集?该数据集在特征和样本上具有广泛的尺度优势,且该数据集也在2018年更新过,所以最终选择该数据集的更新版本(CSE-CICIDS 2018 on AWS)进行NIDS评估。
四、与KitSune的比较?
1.kitsune划分了四个模块:(1)packet capture(2)feature extractor(3)feature mapper(4)anomaly detector
2.不同 --> (1)特征选择部分:kitsune使用阻尼窗口逐步更新pcap包的统计信息,进行特征提取;AE-IDS使用随机森林算法选出最有用的特征提高检测性能。
(2)特征映射部分:kitsune使用层次聚类;AE-IDS使用AP聚类,根据相似程度对特征进行子集划分,每个特征子集的样本具有相同的数量级,可通过计算正常样本的平均值来实现特征分组。
background
一、Auto-Encoder:g(f(x))=x'
输入层:x ->1*m 隐藏层:W 矩阵 -> m*n,得到1*n的隐藏层变量Z 输出层:x'
Lk:层数 l(i):第i层 ||l(i)||:第i层神经元数 Wi:连接第i和i+1层 b(i):第i+1层偏置 θ=(W,b) f为激活函数
![]()
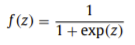
整体:hθ(x)=x'
代价函数:n为训练集样本数。

反向传播使用SGD:在线检测机制需要处理数据的高效性,一个包一处理。
二、RMSE
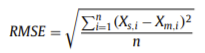
Xs,i -> 观察值 Xm,i -> 真实值
本实验中仅使用标签为normal类型的数据进行训练,目标是使Xs,i和Xm,i 尽可能相近,为此,ELM(Extreme Learning Machine method:极限学习机 --> 随机投影+线性模型)被用于优化整个学习过程,可以提高学习率,简化参数。
测试阶段:normal的RMSE值趋近于0,而abnormal的RMSE值大于0。
AE-IDS design and implementation
一、总体结构
1.data preprocessing:原始样本默认值/无穷值的替换 -->稠密/稀疏矩阵的划分 --> L2标准化
2.feature selection:随机森林算法选择最显著的特征 --> 使用袋外数据进行测试
3.feature grouping:计算所选择特征的样本均值作为新样本 --> AP算法划分特征子集,保证特征子集的样本具有相同数量级【优点:(1)相同数量级,使得每组数据特征具有可比性(2)可观察到异常流的变化】
4.anomaly detection:auto-encoder和K-means/GMM的组合,通过RMSE值判断normal/abnormal
2.data preprocessing:对数据清洗,选择最佳特征,对相似特征进行聚类,为异常检测提供合理数据。
(1)默认值/无穷值的替换:有过样本中有此类值,如何替换该值取决于这类值在总样本中的占比,如不超过1%,则直接使用0进行替换。
(2)稠密/稀疏矩阵的划分:使用tFp&tBp,若两者很小,意味着该条记录中大部分的统计信息为0,那么该条记录就是稀疏的。
注:两种不同的矩阵使用不同学习参数,训练时间减少,acc提高。
(3)总数据集的划分:
train set:85%的normal(划分为稠密/稀疏矩阵),其中75%用于AE训练,25%用于feature grouping
test set:剩余的15%normal和100%的abnormal
(4)L2正则化:尽可能转化强特征,突出值很小但意义较大的特征。
3.feature selection:随机森林算法。
优点:(1)短时间内处理高维数据 (2)随机性提升分类性能 (3)产生无偏误差估计
由于每棵树所使用的特征是随机选择的,故误差会较大,但整体的方差会较小以弥补误差较大的问题。
为每棵树随机选择m个特征进行建树且无需剪枝,可以完整显示normal流量的特征。
基尼指数(衡量样本纯度,值越高,不平衡程度越高,纯度越低)作为评分标准为子树选择区分特征。
每棵DT树会计算每个特征的排列重要性得分(FPI):①计算第一次预测的acc ②保持其他特征不变,将该特征进行随机扰动,再次计算acc ③将两次acc的差作为FPI的度量
FPI的三种情况:正值-->重要特征 负值-->差(非重要)特征,较分散 0值-->不相关特征
最后根据特征重要性对特征进行重新排序。
如何评估特征选择?仅部分样本用于建树,未使用样本(袋外样本)用于测试,计算acc。
4.feature grouping:在AI中,用于观察、提取、识别数据。
(1)为何可以使用无监督聚类算法进行feature grouping?不考虑变量间相关性。①无需数据特征的统计信息 ②可以解决数据特征分布不均的情况
(2)AP(亲和力传播)算法:将每个样本点作为候选类代表点(不受初始点选择的干扰),可以收敛到全局最优解,较稳定。本质是贪心算法解决组合优化问题,无需确定K值(聚类数),也没有对相似矩阵的对称性要求。
最终将m个特征划分为n个特征子集,每个子集中的特征都是强相关的:①解决特征分布不均-->划分相似特征子集 ②AP算法持续迭代直到全局最优 ③考虑所有节点进行迭代
(3)而迭代结束的条件如何确定?①经过几次迭代后聚类中心保持不变 ②迭代次数超过预定义的值 ③经过几次迭代后更新的信息保持不变
注意:我们并非直接使用样本进行AP聚类,而是提取部分样本(85%的25%)计算其均值,因为normal样本中所选取的特征不会有较大偏差/变化,同时,AP算法较为复杂,直接使用样本会消耗时间和空间。
5.anomaly detection:AE和无监督聚类算法(GMM根据概率/K-means根据得分)的组合。其中AE中的encoder和decoder使用相同的权重矩阵,仅需优化WT,减少计算代价。
(1)训练阶段:这里解释了为什么仅使用三层AE神经网络?①更深层、更复杂的算法非常容易过拟②浅层已达到良好的特征表达效果。
(2)测试阶段:仅使用已经选择出的特征计算RMSE,取所有子集RMSE均值,output结果经过正则化,超过阈值则为abnormal。
整体流程图如下:
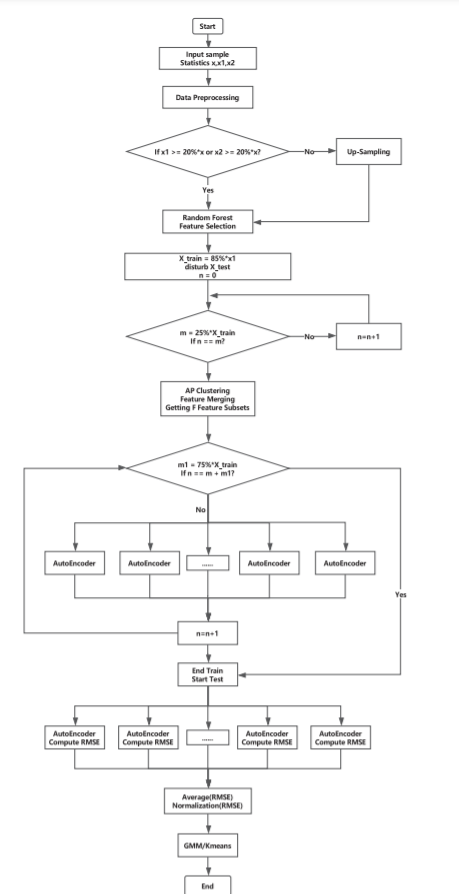
这里的上采样:可以解决数据不平衡,消除离群的敏感点问题。但最终得到的AUC面积与未经上采样的结果相同,故最终实验当中并未采用上采样的步骤。
二、实验评估
1.confusion matrix

比较稀疏/稠密矩阵
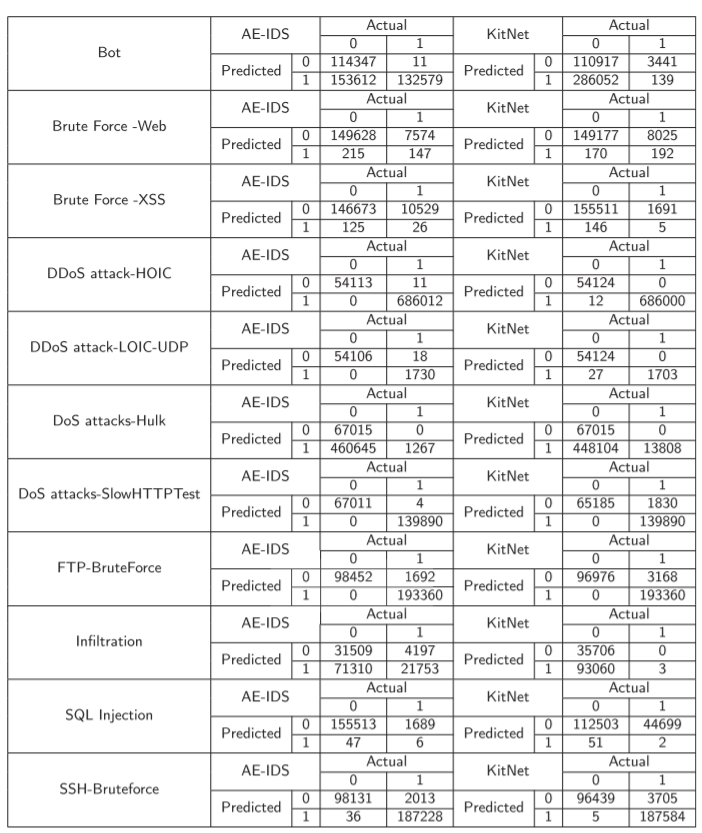
比较AE-IDS和kitsune
这里,有两种攻击的计算效果并不良好。
(1)Infiltration:通常发生在内部网络中,不会表现出可以的外部行为。
(2)SQL注入:提交包含错误SQL语句的HTTP请求,而从网络流的角度与普通HTTP请求相似。
猜测系统日志会对检测上述两种攻击效果良好。
2.recall

3.AUC:ROC与坐标轴围成的面积。


依然是前文提到的两种攻击效果较差。
4.detect time

稀疏/稠密矩阵对比

AE-IDS和kitsune对比