两方面(发散,相关)~三方法(FWE)
F:方皮卡互
W:RFE
E:惩罚树
一、简介
我们的数据处理后,喂给算法之前,考虑到特征的实际情况,通常会从两个方面考虑来选择特征:
1)特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用
2)特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优先选择
根据特征选择的形式又可以将特征选择方法分为3种:
- Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值选择特征
- Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征
- Embedded:集成法,先使用某些模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣
二、实践
1)Filter
a)方差法
使用方差法,要先计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。
使用feature_selection库的VarianceThreshold类来选择特征的代码如下:
from sklearn.datasets import load_iris from sklearn.feature_selection import VarianceThreshold iris = load_iris() print(iris.data[0]) print(iris.target[0])
一个样本的数据和标签,如下:

而我们将方差阈值设置为3之后,保留方差大于3的特征:
print(VarianceThreshold(threshold=3).fit_transform(iris.data)[0])
结果:
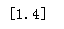
可见只有第三个特征满足方差大于3,被保留,注意:方差选择法,返回值为特征选择后的数据
b)皮尔逊系数
皮尔逊系数只能衡量线性相关性,先要计算各个特征对目标值的相关系数以及相关系数的P值。
用feature_selection库的SelectKBest类结合皮尔逊系数来选择特征的代码如下:
from sklearn.feature_selection import SelectKBest
from scipy.stats import pearsonr
from sklearn.datasets import load_iris
import numpy as np
iris = load_iris()
#选择K个最好的特征,返回选择特征后的数据
#第一个参数为计算评估特征是否好的函数,该函数输入特征矩阵和目标向量
#输出二元组(评分,P值)的数组
#数组第i项为第i个特征的评分和P值。在此定义为计算相关系数
#参数k为选择的特征个数
def multivariate_pearsonr(X, y):
scores, pvalues = [], []
for ret in map(lambda x: pearsonr(x, y), X.T):
print(ret)
scores.append( abs(ret[0]) )
pvalues.append( ret[1] )
return (np.array(scores), np.array(pvalues))
transformer = SelectKBest( score_func = multivariate_pearsonr, k=2)
Xt_pearson = transformer.fit_transform( iris.data, iris.target)
print(Xt_pearson)

Pearson相关系数的一个明显缺陷是,作为特征排序机制,他只对线性关系敏感。如果关系是非线性的,即便两个变量具有一一对应的关系,Pearson相关性也可能会接近0
from scipy.stats import pearsonr import numpy as np x = np.random.uniform(-1, 1, 10000) print( pearsonr(x, x**2) ) print( pearsonr(x, x**2)[0] )

c)卡方检验
在统计学中,卡方检验用来评价是两个事件是否独立,也就是$P(AB) = P(A)*P(B)$
from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import chi2 from sklearn.datasets import load_iris iris = load_iris() SelectKBest(chi2, k=2).fit_transform(iris.data, iris.target)
d)互信息
互信息是用来评价一个事件的出现对于另一个事件的出现所贡献的信息量
这里有通俗的理解(抛开公式):
原来我对X有些不确定(不确定性为H(X)),告诉我Y后我对X不确定性变为H(X|Y),这个不确定性的减少量就是X,Y之间的互信息I(X;Y)=H(X)-H(X|Y)。
互信息指的是两个随机变量之间的关联程度:即给定一个随机变量后,另一个随机变量不确定性的削弱程度,因而互信息取值最小为0,意味着给定一个随机变量对确定一另一个随机变量没有关系,最大取值为随机变量的熵,意味着给定一个随机变量,能完全消除另一个随机变量的不确定性
from sklearn.feature_selection import mutual_info_classif from sklearn.datasets import load_iris iris = load_iris() SelectKBest(mutual_info_classif, k=2).fit_transform(iris.data, iris.target)
反过头来看(y=x^2)这个例子,MIC算出来的互信息值为1(最大的取值)
from minepy import MINE m = MINE() x = np.random.uniform(-1, 1, 100000) m.compute_score(x, x**2) print ( m.mic() )

2)Wrapper
a)递归特征消除法(Recursive Feature Elimination)
递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。
使用feature_selection库的RFE类来选择特征的代码如下:
from sklearn.feature_selection import RFE from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_iris iris = load_iris() RFE(estimator=LogisticRegression(), n_features_to_select=2).fit_transform(iris.data, iris.target)
3)Embedded:集成法,先使用某些模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣
a)基于树模型的特征选择法
树模型中GBDT也可用来作为基模型进行特征选择,使用feature_selection库的SelectFromModel类结合GBDT模型,来选择特征的代码如下:
from sklearn.feature_selection import SelectFromModel from sklearn.ensemble import GradientBoostingClassifier from sklearn.datasets import load_iris iris = load_iris() SelectFromModel(GradientBoostingClassifier()).fit_transform(iris.data, iris.target)
b)基于惩罚项的特征选择法
使用带惩罚项的基模型,除了筛选出特征外,同时也进行了降维
三、总结
