一、UCI
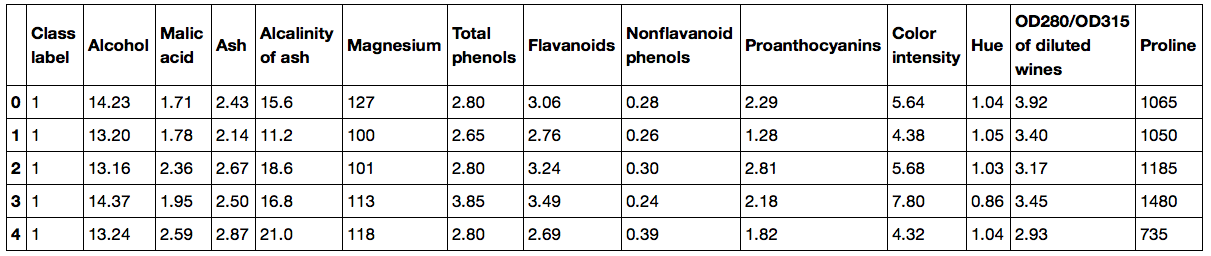
Wine dataset:https://archive.ics.uci.edu/ml/datasets/Wine,包含178个样本,每个样本包含13个与酒的化学特性的特征,标签有1,2,3,代表意大利不同地区生长的三种类型的葡萄
Breast Cancer Wisconsin dataset:https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Diagnostic),包含569个样本,每个样本是良性或者恶性癌细胞,M代表恶性,B代表良性,并且每个样本还有30个特征,可以用来构建模型预测样本是恶性还是良性。
import pandas as pd
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data', header=None)
from sklearn.preprocessing import LabelEncoder
X = df.loc[:, 2:].values
y = df.loc[:, 1].values
le = LabelEncoder()
y = le.fit_transform(y)
le.transform(['M', 'B'])
'''
array([1, 0])
'''
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=1)
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
pipe_lr = Pipeline([ ('scl', StandardScaler()), ('pca', PCA(n_components=2)) , ('clf', LogisticRegression(random_state=1))])
pipe_lr.fit(X_train, y_train)
print('Test Accuracy: %.3f' % pipe_lr.score(X_test, y_test))
#Test Accuracy: 0.947
二、MNIST数据集
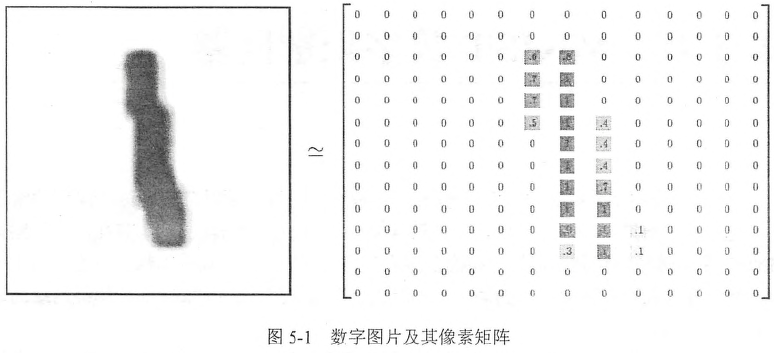
MNIST是NIST数据集的一个子集,包含60000张图片作为训练数据,10000张作为测试数据,其中每张图片代表0~9中的一个数字,图片大小为28*28。并且数字会出现在图片正中间。为了清楚的表示,用下面的14*14矩阵表示了。
http://yann.lecun.com/exdb/mnist有详细的介绍,共提供了4个下载文件:训练数据图片,训练数据答案,测试数据图片,测试数据答案。