一、lucene索引
1、文档层次结构
- 索引(Index):一个索引放在一个文件夹中;
- 段(Segment):一个索引中可以有很多段,段与段之间是独立的,添加新的文档可能产生新段,不同的段可以合并成一个新段;
- 文档(Document):文档是创建索引的基本单位,不同的文档保存在不同的段中,一个段可以包含多个文档;
- 域(Field):一个文档包含不同类型的信息,可以拆分开索引;
- 词(Term):词是索引的最小单位,是经过词法分析和语言处理后的数据;
文档是Lucene索引和搜索的原子单位,文档为包含一个或多个域的容器,而域则依次包含“真正的”被搜索内容,域值通过分词技术处理,得到多个词元。如一篇小说信息可以称为一个文档;小说信息又包含多个域,比如标题,作者、简介、最后更新时间等;对标题这一个域采用分词技术,又可以等到一个或多个词元。
2、正向索引与反向索引
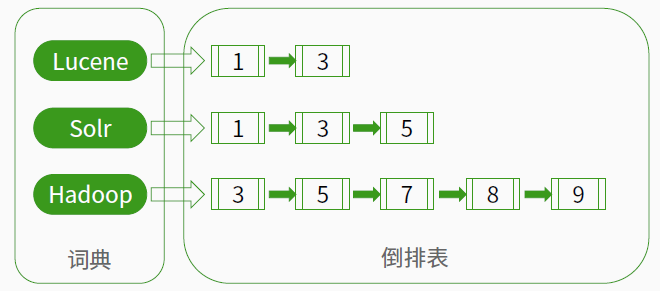
- 正向索引:文档占据了中心的位置,每个文档指向了一个它所包含的索引项的序列。正向信息就是按层次保存了索引一直到词的包含关系: 索引 -> 段-> 文档 -> 域 -> 词
- 反向索引:一种以索引项为中心来组织文档的方式,每个索引项指向一个文档序列,这个序列中的文档都包含该索引项。反向信息保存了词典的倒排表映射:词 -> 文档
lucene使用到的就是反向索引。如下图所示:
二、索引操作
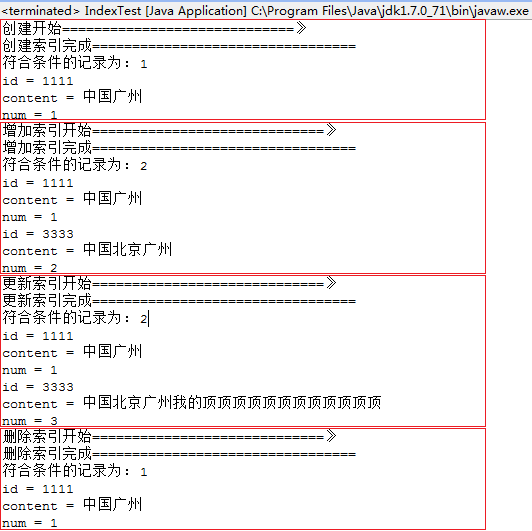
相关示例如下:
1 package com.test.lucene; 2 3 import java.io.IOException; 4 import java.nio.file.Paths; 5 6 import org.apache.lucene.analysis.Analyzer; 7 import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer; 8 import org.apache.lucene.document.Document; 9 import org.apache.lucene.document.Field.Store; 10 import org.apache.lucene.document.IntField; 11 import org.apache.lucene.document.StringField; 12 import org.apache.lucene.document.TextField; 13 import org.apache.lucene.index.DirectoryReader; 14 import org.apache.lucene.index.IndexWriter; 15 import org.apache.lucene.index.IndexWriterConfig; 16 import org.apache.lucene.index.Term; 17 import org.apache.lucene.index.IndexWriterConfig.OpenMode; 18 import org.apache.lucene.queryparser.classic.ParseException; 19 import org.apache.lucene.queryparser.classic.QueryParser; 20 import org.apache.lucene.search.IndexSearcher; 21 import org.apache.lucene.search.Query; 22 import org.apache.lucene.search.TopDocs; 23 import org.apache.lucene.store.Directory; 24 import org.apache.lucene.store.FSDirectory; 25 26 /** 27 * 索引增删改查 28 */ 29 public class IndexTest { 30 /** 31 * 创建索引 32 * 33 * @param path 34 * 索引存放路径 35 */ 36 public static void create(String path) { 37 System.out.println("创建开始=============================》"); 38 Analyzer analyzer = new SmartChineseAnalyzer();// 指定分词技术,这里使用的是中文分词 39 40 IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);// indexWriter的配置信息 41 42 indexWriterConfig.setOpenMode(OpenMode.CREATE_OR_APPEND); // 索引的打开方式:没有则创建,有则打开 43 44 Directory directory = null; 45 IndexWriter indexWriter = null; 46 // 文档一 47 Document doc1 = new Document(); 48 doc1.add(new StringField("id", "1111", Store.YES)); 49 doc1.add(new TextField("content", "中国广州", Store.YES)); 50 doc1.add(new IntField("num", 1, Store.YES)); 51 52 // 文档二 53 Document doc2 = new Document(); 54 doc2.add(new StringField("id", "2222", Store.YES)); 55 doc2.add(new TextField("content", "中国上海", Store.YES)); 56 doc2.add(new IntField("num", 2, Store.YES)); 57 58 try { 59 directory = FSDirectory.open(Paths.get(path));// 索引在硬盘上的存储路径 60 indexWriter = new IndexWriter(directory, indexWriterConfig); 61 indexWriter.addDocument(doc1); 62 indexWriter.addDocument(doc2); 63 // 将indexWrite操作提交,如果不提交,之前的操作将不会保存到硬盘 64 // 但是这一步很消耗系统资源,索引执行该操作需要有一定的策略 65 indexWriter.commit(); 66 } catch (IOException e) { 67 e.printStackTrace(); 68 } finally { // 关闭资源 69 try { 70 indexWriter.close(); 71 directory.close(); 72 } catch (IOException e) { 73 e.printStackTrace(); 74 } 75 } 76 System.out.println("创建索引完成================================="); 77 } 78 79 /** 80 * 添加索引 81 * 82 * @param path 83 * 索引存放路径 84 * @param document 85 * 添加的文档 86 */ 87 public static void add(String path, Document document) { 88 System.out.println("增加索引开始=============================》"); 89 Analyzer analyzer = new SmartChineseAnalyzer();// 指定分词技术,这里使用的是中文分词 90 91 IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);// indexWriter的配置信息 92 93 indexWriterConfig.setOpenMode(OpenMode.CREATE_OR_APPEND); // 索引的打开方式:没有则创建,有则打开 94 Directory directory = null; 95 IndexWriter indexWriter = null; 96 try { 97 directory = FSDirectory.open(Paths.get(path));// 索引在硬盘上的存储路径 98 99 indexWriter = new IndexWriter(directory, indexWriterConfig); 100 indexWriter.addDocument(document); 101 indexWriter.commit(); 102 } catch (IOException e) { 103 e.printStackTrace(); 104 } finally { // 关闭资源 105 try { 106 indexWriter.close(); 107 directory.close(); 108 } catch (IOException e) { 109 e.printStackTrace(); 110 } 111 } 112 System.out.println("增加索引完成================================="); 113 } 114 115 /** 116 * 删除索引 117 * 118 * @param indexpath 119 * 索引存放路径 120 * @param id 121 * 文档id 122 */ 123 public static void delete(String indexpath, String id) { 124 System.out.println("删除索引开始=============================》"); 125 Analyzer analyzer = new SmartChineseAnalyzer();// 指定分词技术,这里使用的是中文分词 126 127 IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);// indexWriter的配置信息 128 129 indexWriterConfig.setOpenMode(OpenMode.CREATE_OR_APPEND); // 索引的打开方式:没有则创建,有则打开 130 IndexWriter indexWriter = null; 131 Directory directory = null; 132 try { 133 directory = FSDirectory.open(Paths.get(indexpath));// 索引在硬盘上的存储路径 134 indexWriter = new IndexWriter(directory, indexWriterConfig); 135 indexWriter.deleteDocuments(new Term("id", id));// 删除索引操作 136 } catch (IOException e) { 137 e.printStackTrace(); 138 } finally { // 关闭资源 139 try { 140 indexWriter.close(); 141 directory.close(); 142 } catch (IOException e) { 143 e.printStackTrace(); 144 } 145 } 146 System.out.println("删除索引完成================================="); 147 } 148 149 /** 150 * Lucene没有真正的更新操作,通过某个fieldname,可以更新这个域对应的索引,但是实质上,它是先删除索引,再重新建立的。 151 * 152 * @param indexpath 153 * 索引存放路径 154 * @param newDoc 155 * 更新后的文档 156 * @param oldDoc 157 * 需要更新的目标文档 158 */ 159 public static void update(String indexpath, Document newDoc, Document oldDoc) { 160 System.out.println("更新索引开始=============================》"); 161 Analyzer analyzer = new SmartChineseAnalyzer(); 162 IndexWriterConfig config = new IndexWriterConfig(analyzer); 163 config.setOpenMode(OpenMode.CREATE_OR_APPEND); 164 IndexWriter indexWriter = null; 165 Directory directory = null; 166 try { 167 directory = FSDirectory.open(Paths.get(indexpath)); 168 indexWriter = new IndexWriter(directory, config); 169 indexWriter.updateDocument(new Term("id", oldDoc.get("id")), newDoc); 170 } catch (IOException e) { 171 e.printStackTrace(); 172 } finally { // 关闭资源 173 try { 174 indexWriter.close(); 175 directory.close(); 176 } catch (IOException e) { 177 e.printStackTrace(); 178 } 179 } 180 System.out.println("更新索引完成================================="); 181 } 182 183 /** 184 * 搜索 185 * 186 * @param keyword 187 * 关键字 188 * @param indexpath 189 * 索引存放路径 190 */ 191 public static void search(String keyword, String indexpath) { 192 Directory directory = null; 193 try { 194 directory = FSDirectory.open(Paths.get(indexpath));// 索引硬盘存储路径 195 196 DirectoryReader directoryReader = DirectoryReader.open(directory);// 读取索引 197 198 IndexSearcher searcher = new IndexSearcher(directoryReader);// 创建索引检索对象 199 200 Analyzer analyzer = new SmartChineseAnalyzer();// 分词技术 201 202 QueryParser parser = new QueryParser("content", analyzer);// 创建Query 203 Query query = parser.parse(keyword);// 查询content为广州的 204 // 检索索引,获取符合条件的前10条记录 205 TopDocs topDocs = searcher.search(query, 10); 206 if (topDocs != null) { 207 System.out.println("符合条件的记录为: " + topDocs.totalHits); 208 for (int i = 0; i < topDocs.scoreDocs.length; i++) { 209 Document doc = searcher.doc(topDocs.scoreDocs[i].doc); 210 System.out.println("id = " + doc.get("id")); 211 System.out.println("content = " + doc.get("content")); 212 System.out.println("num = " + doc.get("num")); 213 } 214 } 215 directory.close(); 216 directoryReader.close(); 217 } catch (IOException e) { 218 e.printStackTrace(); 219 } catch (ParseException e) { 220 e.printStackTrace(); 221 } 222 } 223 /** 224 * 测试代码 225 * @param args 226 */ 227 public static void main(String[] args) { 228 String indexpath = "D://index/test"; 229 create(indexpath);// 创建索引 230 search("广州", indexpath); 231 Document doc = new Document(); 232 doc.add(new StringField("id", "3333", Store.YES)); 233 doc.add(new TextField("content", "中国北京广州", Store.YES)); 234 doc.add(new IntField("num", 2, Store.YES)); 235 add(indexpath, doc);// 添加索引 236 search("广州", indexpath); 237 Document newDoc = new Document(); 238 newDoc.add(new StringField("id", "3333", Store.YES)); 239 newDoc.add(new TextField("content", "中国北京广州我的顶顶顶顶顶顶顶顶顶顶顶顶", Store.YES)); 240 newDoc.add(new IntField("num", 3, Store.YES)); 241 update(indexpath, newDoc, doc);// 更新索引 242 search("广州", indexpath); 243 delete(indexpath, "3333");// 删除索引 244 search("广州", indexpath); 245 } 246 }
运行结果如下: