此作业的要求参见:https://edu.cnblogs.com/campus/nenu/2020Fall/homework/11206
词频统计 SPEC
1、博客。
发表博客,介绍上述“项目”中每个功能的重点/难点,展示重要代码片断,给出执行效果截图,展示你感觉得意、突破、困难的地方。
功能1 小文件输入。键盘在控制台下输入命令。total一项中相同的单词不重复计数,出现2次的very计数1次。
执行效果如下:

功能2 支持命令行输入英文作品的文件名。
执行效果如下:

功能3 支持命令行输入存储有英文作品文件的目录名,批量统计。
执行效果如下:
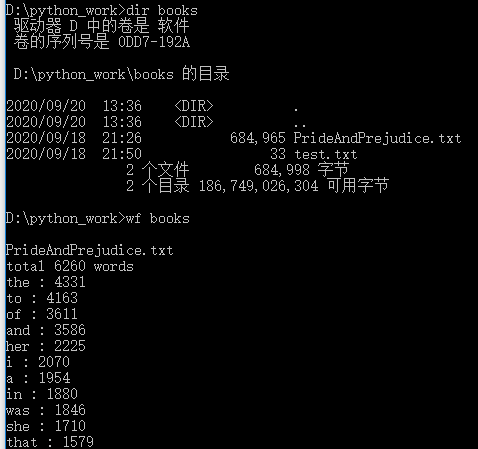
补充截图:
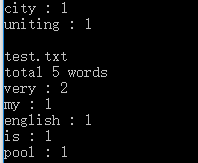
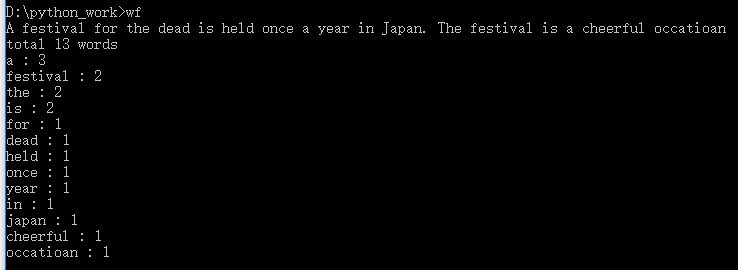
功能4 从控制台读入英文单篇作品,或者 bing: linux 重定向。
执行效果如下:
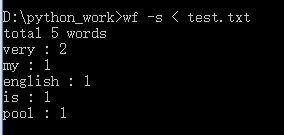
补充截图:
具体代码如下:
#功能2和功能3统计单词个数 def total_words(filename): with open(filename,encoding='utf-8') as f: str1 = f.read() str1 = re.sub('[^a-zA-Z]',' ',str1) #sub函数 将不是字母的用空格代替 str2 = str1.lower().split() #将所有单词变为小写统计 words_dic = {} total = 0 for word in str2: if word in words_dic: words_dic[word] += 1 #重复的单词加一 else: words_dic[word] = 1 #不重复的单词写入words_dic字典 total += 1 #统计单词个数 print("total " + str(total) + " words") #对统计单词个数按值排序 words_order = sorted(words_dic.items(),key=lambda words_dic : words_dic[1],reverse=True) for key,value in words_order: print(key + " : " + str(value)) f.close() #功能4统计单词个数 文章和重定向 def total_word(content): str3 = content.lower().split() word_dic = {} total_1 = 0 for word1 in str3: if word1 in word_dic: word_dic[word1] += 1 else: word_dic[word1] = 1 total_1 += 1 print("total " + str(total_1) + " words") words_order1 = sorted(word_dic.items(),key=lambda word_dic : word_dic[1],reverse=True) for key1,value1 in words_order1: print(key1 + " : " + str(value1)) #功能3打开文件夹 def files_dic(files): files_list = os.listdir(files) #获取文件夹下列表 for file in files_list: print(" " + file) if not os.path.isdir(file): total_words(file) def main(argv): #功能4 输入一段文章 if(len(argv)==1): str = input() str = re.sub('[^a-zA-Z]',' ',str) total_word(str) #功能1和功能4 elif sys.argv[1] == '-s': #功能1 if(len(argv) == 3): total_words(sys.argv[2]) #功能4 重定向 elif(len(argv) == 2): redirect_words = sys.stdin.read() #读取文章内容 redirect_words = re.sub('[^a-zA-Z]',' ',redirect_words) total_word(redirect_words) #功能3 elif os.path.isdir(sys.argv[1]): #判断是文件夹 files_dic(sys.argv[1]) #功能2 else: total_words(sys.argv[1]) #调用函数 if __name__ == "__main__": main(sys.argv[0:])
重点/难点:
功能1:统计单词的个数时,对于重复出现的单词不应计入总的词汇量。
功能2:在统计名著的单词个数时,要把不是字母的,例如数字、标点符号等,都不应计入总词汇量。
功能3:在进入存储有英文作品文件时,还要对下面的子文件进行判断,不是文件夹,再打开文章进行统计。
功能4:直接在控制台输入一段文章或重定向时,不需要打开文件,直接统计词汇量,要注意argv的个数。
突破:
1)在实现功能2时,一开始使用的分隔单词的方法是自己编写一个正则表达式,用replace方法将正则表达式中的符号替换为空格,再用split方法进行分隔,这样不但繁琐而且不能保证统计的全部是单词,编写的正则表达式有可能有遗漏,后用了sub函数的^(a-zA-Z)的方法,简单而且统计单词较全。
2)在实现功能4时因没有很好的理解重定向导致运行代码时找不到文件,后通过查阅资料及请教同学,知道重定向已经读出文件内容,可直接进行词汇量统计,不需要再一次执行打开文件操作。
困难:
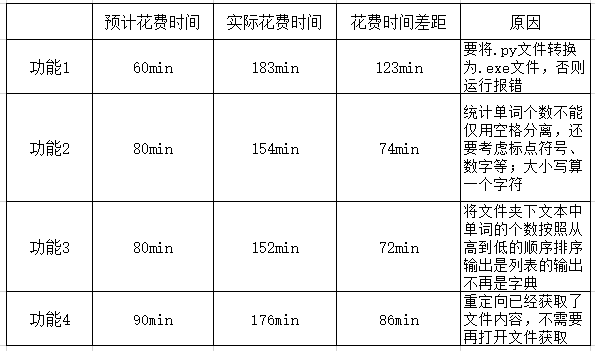
1)因用python编写程序,要想在控制台运行时达到目标,需将.py文件转变为.exe文件,否则程序报错。
2)统计单词时将单词与个数作为键值对存入字典,而要按照各个单词总数从高到低的顺序输出,用了sorted函数,返回的是一个包含元组的列表,不再是字典,因没搞清楚,输出一直按字典方式遍历输出,一直出错。
3)要在控制台-s后输入文本名,不能再是单纯的input(),需要用到argv
2、PSP
在同一篇博客中,参照教材第35页表2-2和表2-3,为上述“项目”制作PSP阶段表格。估算你对每个功能 (或/和子功能)的预计花费时间,记录词频统计项目实际花费时间,填入PSP阶段表格,时间颗粒度为分钟。对比每项时间花费的差距,分析原因。
3、代码及版本控制
Github中代码地址:https://github.com/amancer34/work_statistics
Coding.net中代码地址:https://amancer.coding.net/p/word-statistics/d/word_statistics/git
代码地址 :https://github.com/amancer34/work_statistics.git