宏观流程如下图:
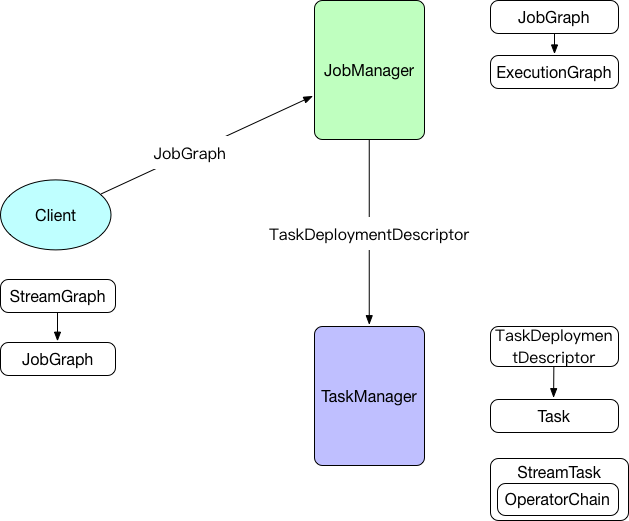
client端
生成StreamGraph
env.addSource(new SocketTextStreamFunction(...))
.flatMap(new FlatMapFunction())
.keyBy("word")
.timeWindow(Time.seconds(5))
.reduce(new ReduceFunction())
.print()
StreamExecutionEnvironment上的一系列api调用会在env->transformations中添加相应的StreamTransformation对象,然后调用StreamGraphGenerator->transformation方法遍历所有的StreamTransformation对象生成最终的StreamGraph。
如上代码段会生成如下StreamGraph:
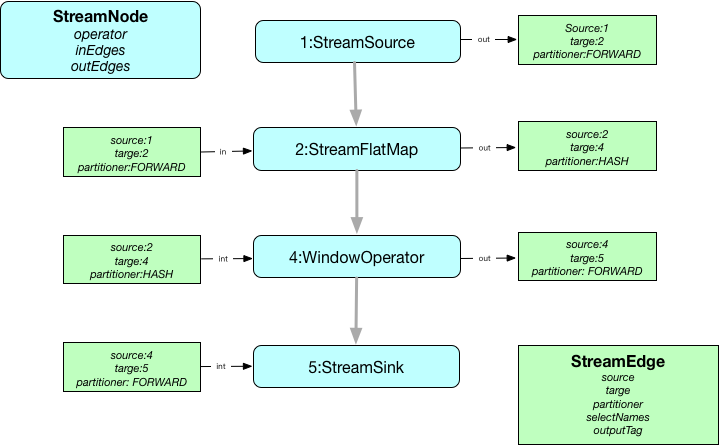
StreamGraph->JobGraph
private List<StreamEdge> createChain(
Integer startNodeId,
Integer currentNodeId,
Map<Integer, byte[]> hashes,
List<Map<Integer, byte[]>> legacyHashes,
int chainIndex,
Map<Integer, List<Tuple2<byte[], byte[]>>> chainedOperatorHashes)
从StreamGraph的所有sourceStreamNode开始遍历处理,如果是可链接的(isChainable为true)则继续,同时生成该节点的StreamConfig信息(包含StreamOperator``chainIndex``chainEnd等),否则生成新的JobVertex,最后链接connect函数创建JobEdge对象链接JobVertex。
public static boolean isChainable(StreamEdge edge, StreamGraph streamGraph) {
StreamNode upStreamVertex = edge.getSourceVertex();
StreamNode downStreamVertex = edge.getTargetVertex();
StreamOperator<?> headOperator = upStreamVertex.getOperator();
StreamOperator<?> outOperator = downStreamVertex.getOperator();
return downStreamVertex.getInEdges().size() == 1
&& outOperator != null
&& headOperator != null
&& upStreamVertex.isSameSlotSharingGroup(downStreamVertex)
&& outOperator.getChainingStrategy() == ChainingStrategy.ALWAYS
&& (headOperator.getChainingStrategy() == ChainingStrategy.HEAD ||
headOperator.getChainingStrategy() == ChainingStrategy.ALWAYS)
&& (edge.getPartitioner() instanceof ForwardPartitioner)
&& upStreamVertex.getParallelism() == downStreamVertex.getParallelism()
&& streamGraph.isChainingEnabled();
}
如上代码会生成包含两个JobVertex对象的JobGraph:
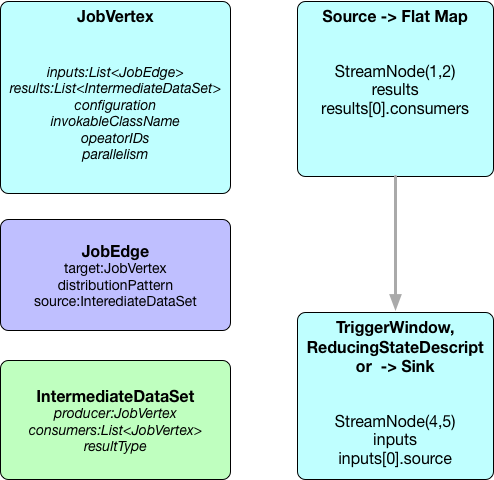
JobVertex的configuration属性中的chainedTaskConfig_``chainedOutputs分别包含了该节点链接的所有StreamNode节点的配置信息和所有SteamNode本身序列化后的二进制数组
JobManager
主要把客户端提交的JobGraph转化成ExecutionGraph,并把ExecutionGraph包含的所有ExecutionVertex对应的Execution提交给分配到其执行所需资源的TaskManager
DistributionPattern分发模式用于确定生产者(产生中间结果IntermediateResultPartition)与其消费者(通过ExecutionEdge)怎样链接
switch (channel.getShipStrategy()) {
case FORWARD:
distributionPattern = DistributionPattern.POINTWISE;
break;
case PARTITION_RANDOM:
case BROADCAST:
case PARTITION_HASH:
case PARTITION_CUSTOM:
case PARTITION_RANGE:
case PARTITION_FORCED_REBALANCE:
distributionPattern = DistributionPattern.ALL_TO_ALL;
break;
default:
throw new RuntimeException("Unknown runtime ship strategy: " + channel.getShipStrategy());
}
ExecutionVertex之间如何链接:
-
ALL_TO_ALL模式:
则每一个并行的ExecutionVertex节点都会链接到源节点产生的所有中间结果IntermediateResultPartition

-
POINTWISE模式:-
源的并行度和目标并行度相等。这种情况下,采用一对一的链接方式:

-
源的并行度小于目标并行度。这种情况下,对于每一个执行节点链接到的源的中间结果分区由如下公式计算得到:
sourcePartition = (int)subTaskIndex / (((float) parallelism) / numSources)
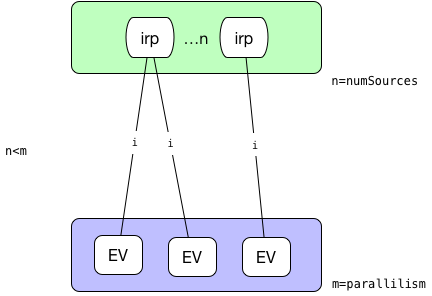 * 源的并行度大于目标并行度。这种情况下,计算每一个执行节点会平均链接到几个源节点,平均分配后余下的都分给最后一个节点。 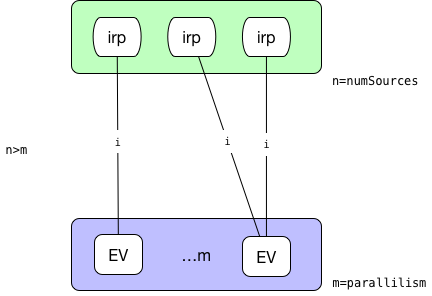 -
最后提交给TaskManager的TaskDeploymentDescriptor如下:
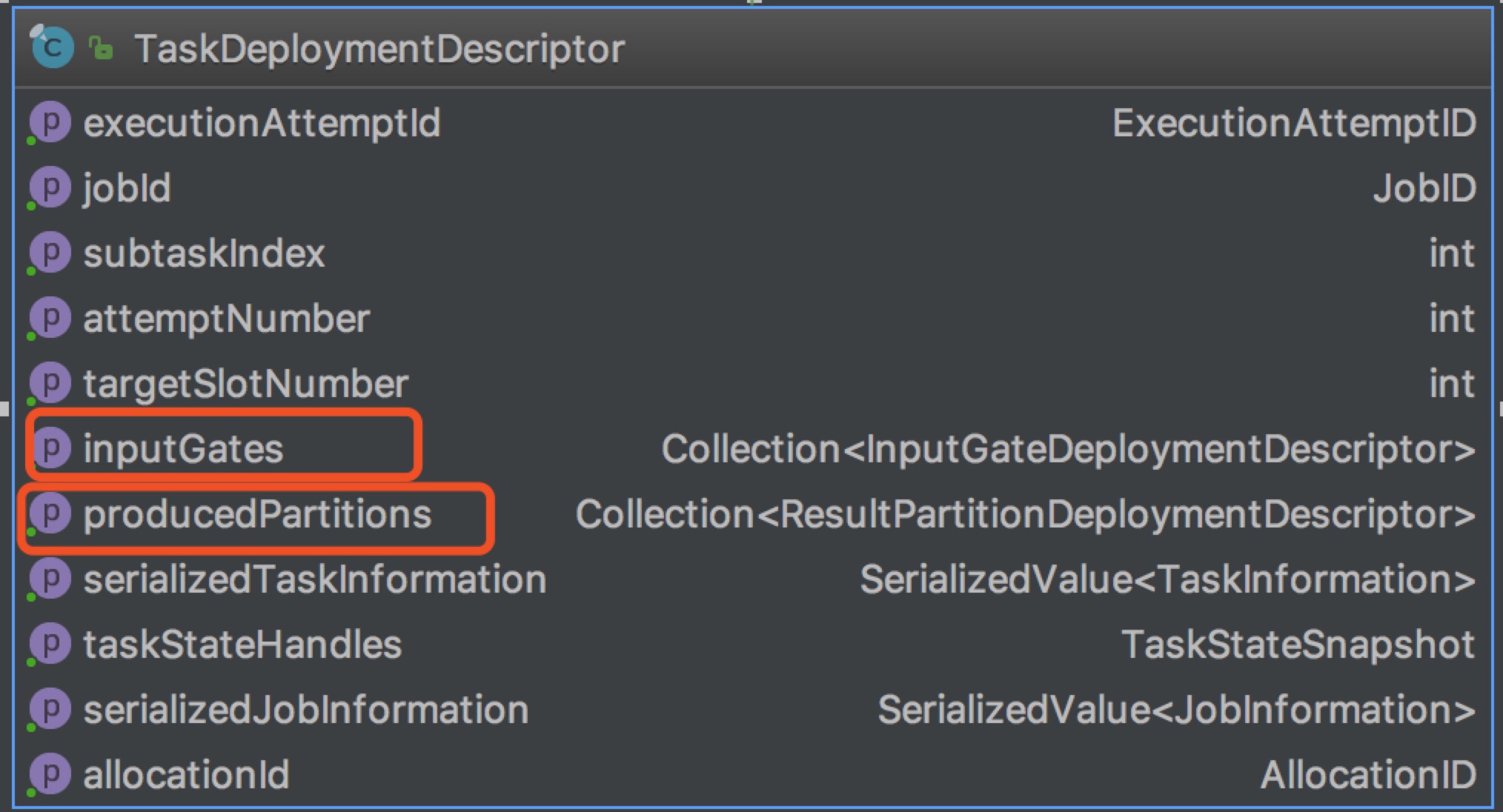
ResultPartitionDeploymentDescriptor有一个numberOfSubpartitions字段,其等于此ResultPartition的消费者的数量(被下级链接到的边数),因为最终执行的时候每一个ResultPartition还会拆分为numberOfSubpartitions相同数量的ResultSubPartition。
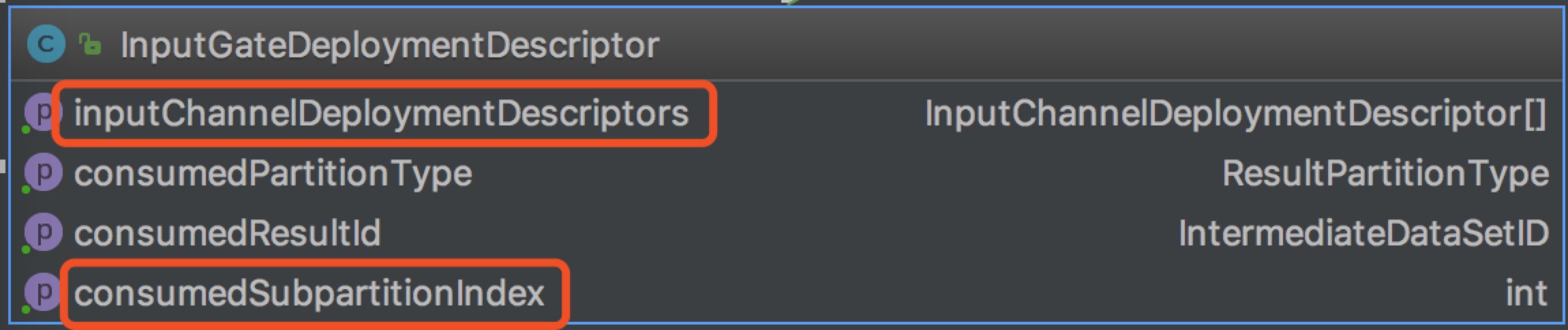
InputGateDeploymentDescriptor包含多个InputChannelDeploymentDescriptor和一个用以指示消费第几个ResultSubPartition的consumedSubpartitionIndex。每一个InputGateDeploymentDescriptor消费的所有ResultPartition的subPartitionIndex是一样的。
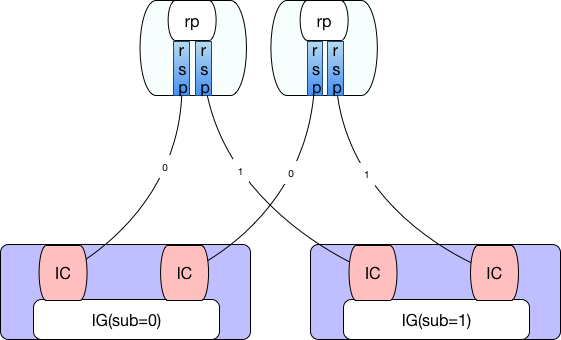
例如并行度均为2的两个ExecutionJobVertex采用ALL_TO_ALL方式链接的结果如下:
TaskManager
TaskManager接收到TaskDeploymentDescriptor对象后进行反序列化生成Task对象并进行一系列的初始化操作(如:根据ResultPartitionDeploymentDescriptor对象初始化writers[ResultPartitionWriter],根据InputGateDeploymentDescriptor初始化inputGates[SingleInputGate],重新设置classLoader等)然后启用新线程执行invokable[AbstractInvokable]->invoke方法。
也就是说Task的主要业务逻辑其实都包含在了AbstractInvokable对象中,我们来具体看下其子类StreamTask(SourceStreamTask和OneInputStreamTask)
StreamTask的invoke方法会创建OperatorChain
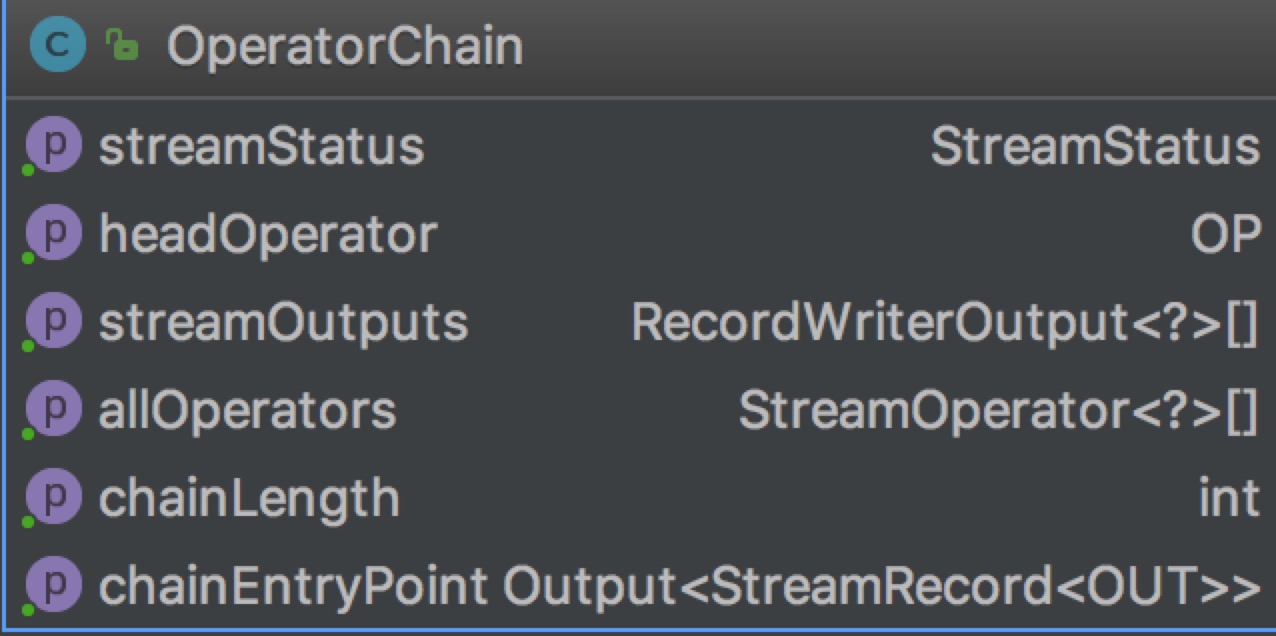
重点关注chainEntryPoint这个属性是BroadcastingOutputCollector类型,其collect方法如下:
public void collect(StreamRecord<T> record) {
for (Output<StreamRecord<T>> output : outputs) {
output.collect(record);
}
}
即使依次遍历链中的每一个output进行collect操作,而其中的每一个output又是ChainingOutput及其子类。
@Override
public void collect(StreamRecord<T> record) {
if (this.outputTag != null) {
// we are only responsible for emitting to the main input
return;
}
pushToOperator(record);
}
protected <X> void pushToOperator(StreamRecord<X> record) {
try {
// we know that the given outputTag matches our OutputTag so the record
// must be of the type that our operator expects.
@SuppressWarnings("unchecked")
StreamRecord<T> castRecord = (StreamRecord<T>) record;
numRecordsIn.inc();
operator.setKeyContextElement1(castRecord);
operator.processElement(castRecord);
}
catch (Exception e) {
throw new ExceptionInChainedOperatorException(e);
}
}
其中operator是OneInputStreamOperator类型其子类业务实现逻辑(processElement)方法:调用用户自定义函数userFunction[Function]处理后按需调用output.collect(element)其中output可能也是一个ChainingOutput类型,这样整个执行链路就被一级一级链接起来了。
this.chainEntryPoint = createOutputCollector(
containingTask,
configuration,
chainedConfigs,
userCodeClassloader,
streamOutputMap,
allOps);
if (headOperator != null) {
Output output = getChainEntryPoint();
headOperator.setup(containingTask, configuration, output);
}
对于StreamTask常见的一个子类SourceStreamTask,其run方法:
@Override
protected void run() throws Exception {
headOperator.run(getCheckpointLock(), getStreamStatusMaintainer());
}
对于OperatorChain链上最后一个operator其output为RecordWriterOutput类型其封装了StreamRecordWriter配合ChannelSelector写入到具体的某个ResultSubPartition
public void emit(T record) throws IOException, InterruptedException {
for (int targetChannel : channelSelector.selectChannels(record, numChannels)) {
sendToTarget(record, targetChannel);
}
}
常见的ChannelSelector:
RescalePartitioner|RebalancePartitioner: 轮询KeyGroupStreamPartitioner: 基于key分组GlobalPartitioner: 全局,只通过subpartition==0ShufflePartitioner:随机到子分区ForwardPartitioner: 本地转发BroadcastPartitioner: 广播到所有分区
另一个StreamTask常见的一个子类OneInputStreamTask,其run方法:
@Override
protected void run() throws Exception {
// cache processor reference on the stack, to make the code more JIT friendly
final StreamInputProcessor<IN> inputProcessor = this.inputProcessor;
while (running && inputProcessor.processInput()) {
// all the work happens in the "processInput" method
}
}
其inputProcessor是StreamInputProcessor类型,在init方法中创建
if (checkpointMode == CheckpointingMode.EXACTLY_ONCE) {
long maxAlign = taskManagerConfig.getLong(TaskManagerOptions.TASK_CHECKPOINT_ALIGNMENT_BYTES_LIMIT);
if (!(maxAlign == -1 || maxAlign > 0)) {
throw new IllegalConfigurationException(
TaskManagerOptions.TASK_CHECKPOINT_ALIGNMENT_BYTES_LIMIT.key()
+ " must be positive or -1 (infinite)");
}
this.barrierHandler = new BarrierBuffer(inputGate, ioManager, maxAlign);
}
else if (checkpointMode == CheckpointingMode.AT_LEAST_ONCE) {
this.barrierHandler = new BarrierTracker(inputGate);
}
barrierHandler与设置的CheckpointingMode相关:
EXACTLY_ONCE:BarrierBufferAT_LEAST_ONCE:BarrierTracker
inputProcessor的processInput方法会调用barrierHandler.getNextNonBlocked()如果获取到一条完整记录则调用streamOperator.processElement(record)触发整体调用链的执行。