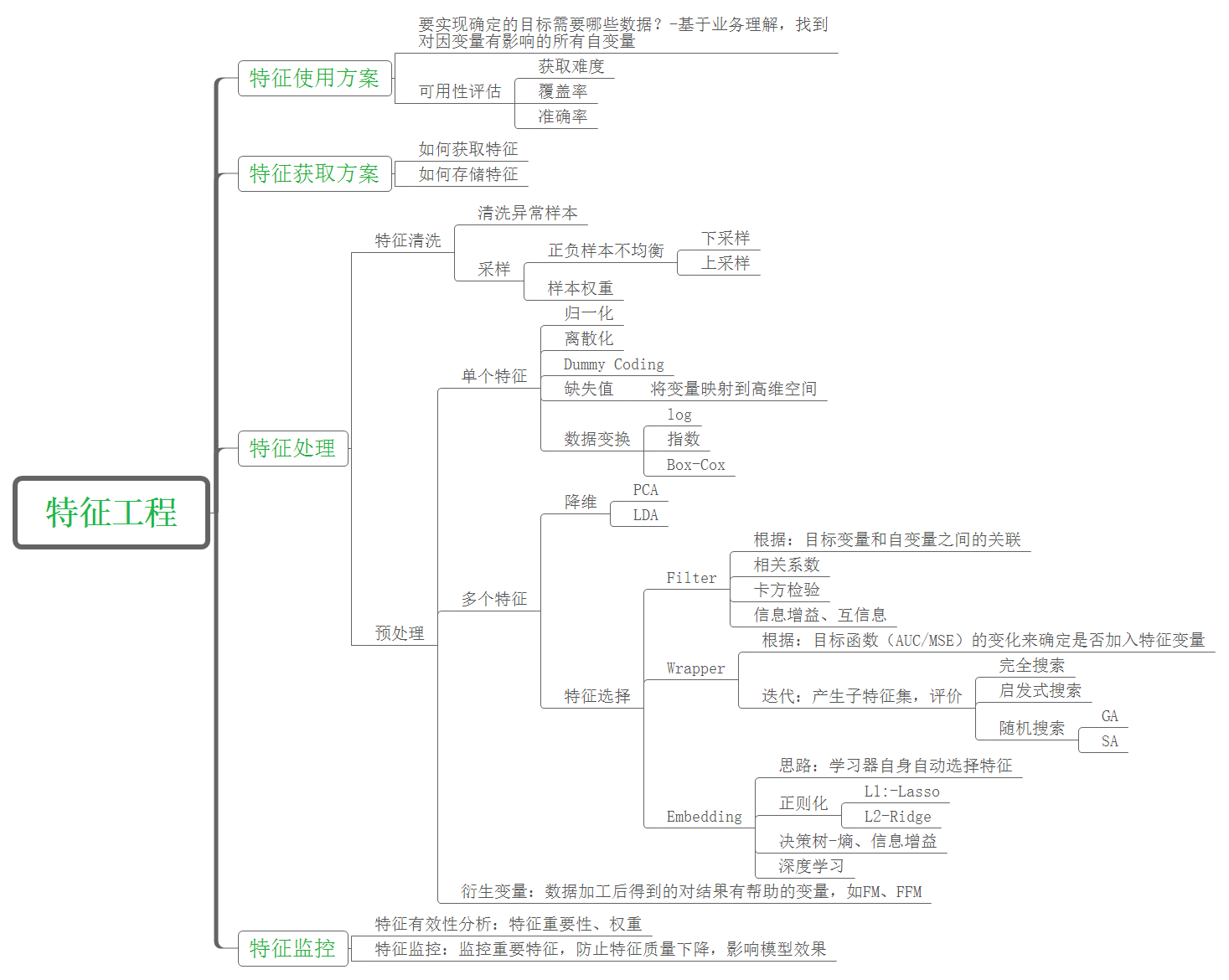
构建模型的个基本过程:


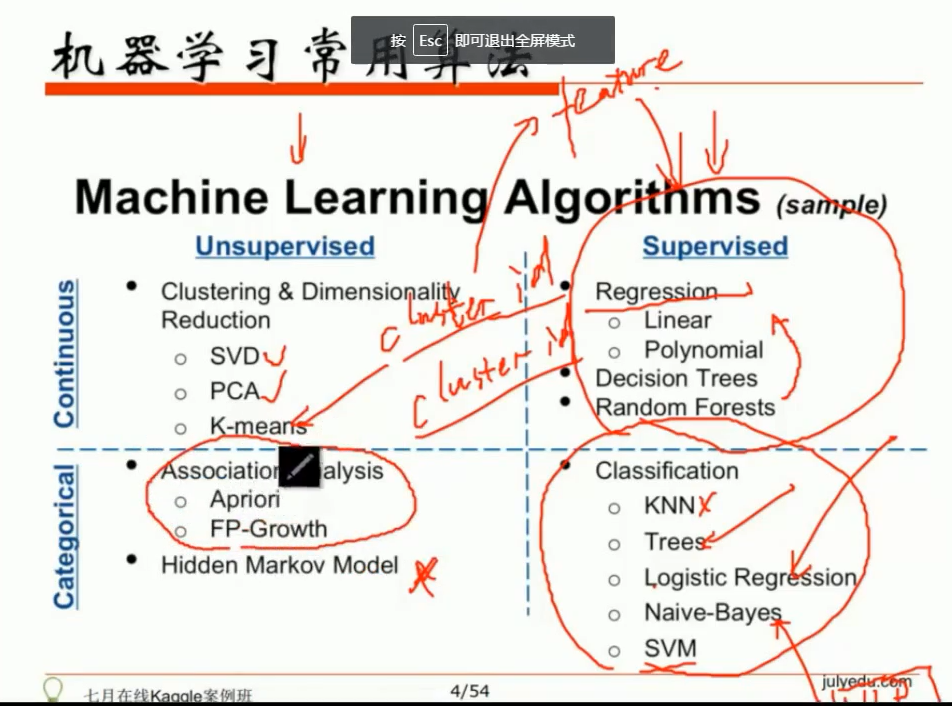
PCA 与 SVD关系
PCA : 降维度。过程:首先计算样本本协方差矩阵,然后·暴力特征分解·(非常消耗资源)。
SVD : 降维度,它的标准推导过程类似特征分解(耗资源),据说,sk-learn中它有其他实现过程。
scikit-learn的PCA算法的背后真正的实现就是用的SVD,而不是我们我们认为的暴力特征分解。
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
1. 收集足够数据量: 收集大于50的样本量,否则非常用于过拟合。
2. 问题划分:是否是一个回归问题、无监督的分类问题(关联规则)、有监督的分类问题
分类问题: 样本量很大 SGD(随机梯度下降), 样本量不是很大时,LR svm GBDT