需求:
爬取:https://v.taobao.com/v/content/video 所有主播详情页信息
首页分析
分析可以得知数据是通过ajax请求获取的.

分析请求头

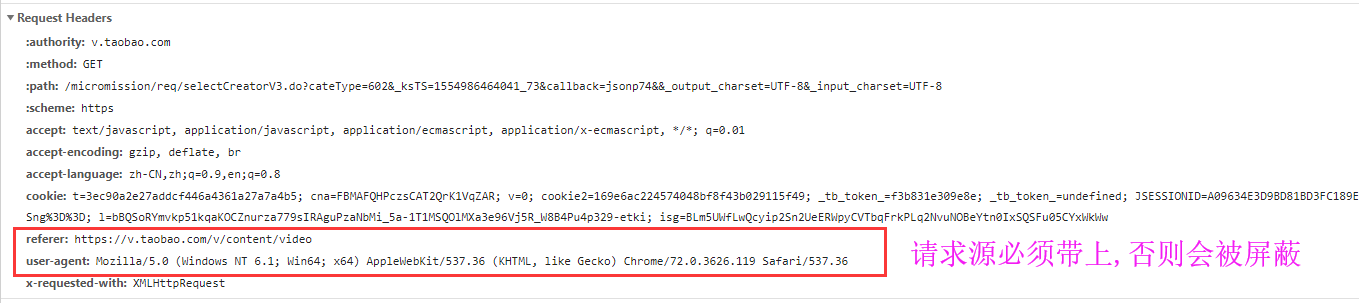
详情页分析
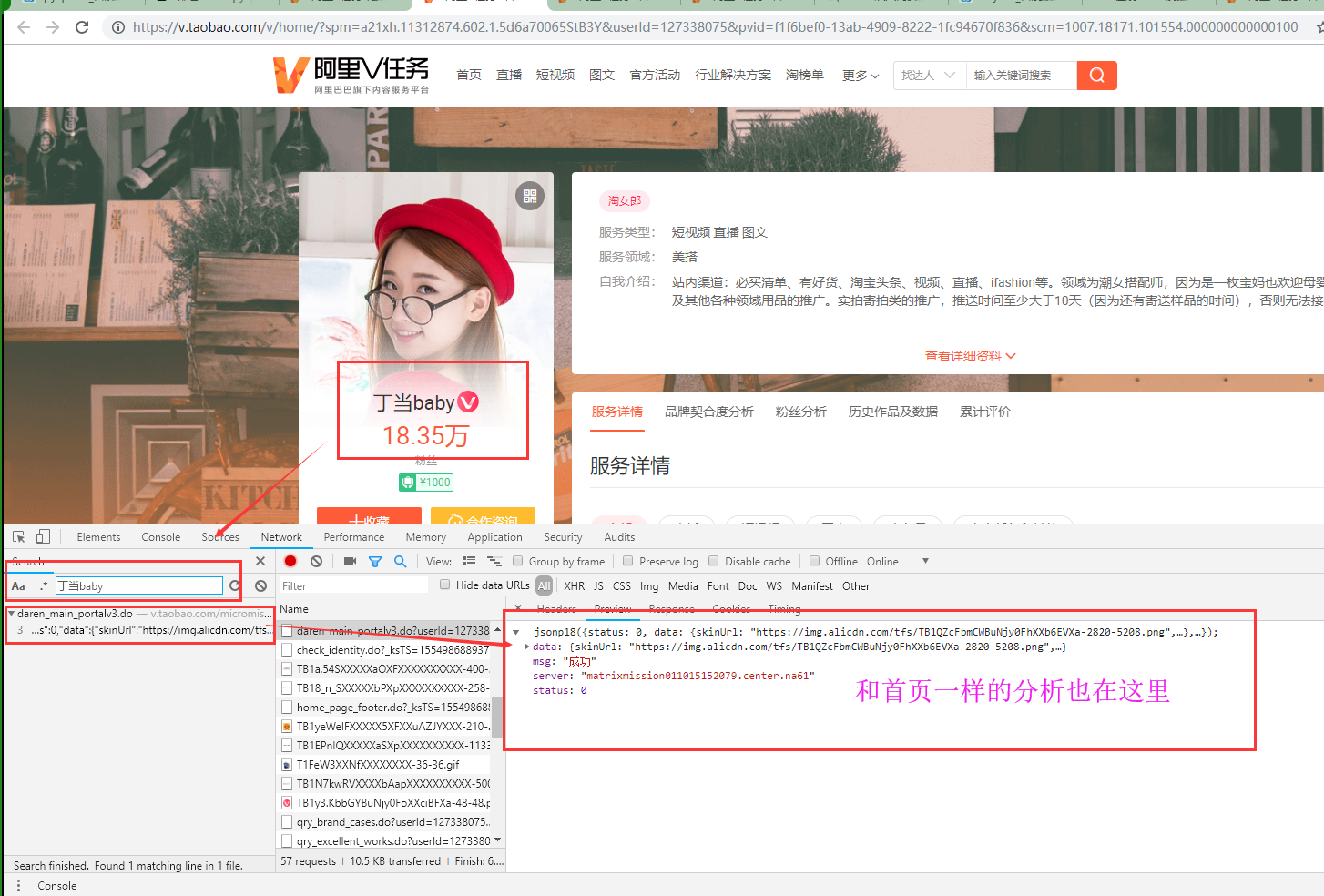
详情页和详情页数据url对比分析

经过测试,发现我们只需要更改'''userid'''的值就可以获取到不同的数据.
分析完毕开始编写代码
完整代码如下
import re import requests import json import jsonpath import pymongo class VtaoSpider: headers={ 'referer': 'https://v.taobao.com/v/content/video', 'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36', } db=None def open(self): '连接数据库' client=pymongo.MongoClient(host='106.12.108.236',port=27017) self.db=client['trip'] def get_first_page(self): '获取首页所有的数据' url_lst=[] for i in range(1,26): #25页数据 '处理页面' params={ 'cateType': 602, 'currentPage': i, '_ksTS': '1554971959356_87', '':'', '_output_charset': 'UTF-8', '_input_charset': 'UTF-8', } start_url='https://v.taobao.com/micromission/req/selectCreatorV3.do' first_data=requests.get(url=start_url,headers=self.headers,params=params) url_lst.append(first_data) # print(first_data.text) return url_lst def get_detail_url(self): '获取详情页的url' response_list=self.get_first_page() all_detail_url=[] for response in response_list: dd = response.text d_dict = json.loads(dd) detail_url = jsonpath.jsonpath(d_dict, '$..homeUrl') #detail_url是一个列表 all_detail_url.extend(detail_url) # print(all_detail_url) return all_detail_url def get_detail_data(self): url_list=self.get_detail_url() # print(url_list) for url in url_list: try: ex='userId=(.*?)&' user_id=re.findall(ex,url)[0] detail_data_url=f'https://v.taobao.com/micromission/daren/daren_main_portalv3.do?userId={user_id}&_ksTS=1554976401436_17' # print(detail_data_url) #获取响应数据 data = requests.get(url=detail_data_url, headers=self.headers).text data_json=json.loads(data) darenNick=jsonpath.jsonpath(data_json,'$..darenNick')[0] darenScore=jsonpath.jsonpath(data_json,'$..darenScore')[0] nick=jsonpath.jsonpath(data_json,'$..nick')[0] creatorType=jsonpath.jsonpath(data_json,'$..creatorType')[0] rank=jsonpath.jsonpath(data_json,'$..rank') res_data={ 'darenNick':darenNick, 'darenScore':darenScore, 'nick':nick, 'creatorType':creatorType, 'rank':rank, } #存入数据库 if self.db['vtaobao'].insert(res_data): print('save to mongo is successful!') except Exception as e: print(e) if __name__ == '__main__': vspider=VtaoSpider() #数据库启动只需要执行一次 vspider.open() vspider.get_detail_data()
一共爬取了450条数据,就是450个主播的相关信息!!!
此代码为使用多进程,多线程,爬取时间不能如你们所愿,感兴趣的朋友可以把代码重构一下,使用多进程,多线程,再分享一波,让大家学习一番,谢谢!!!