一、Bean生命周期
主要分为四步
实例化、属性赋值、初始化、销毁
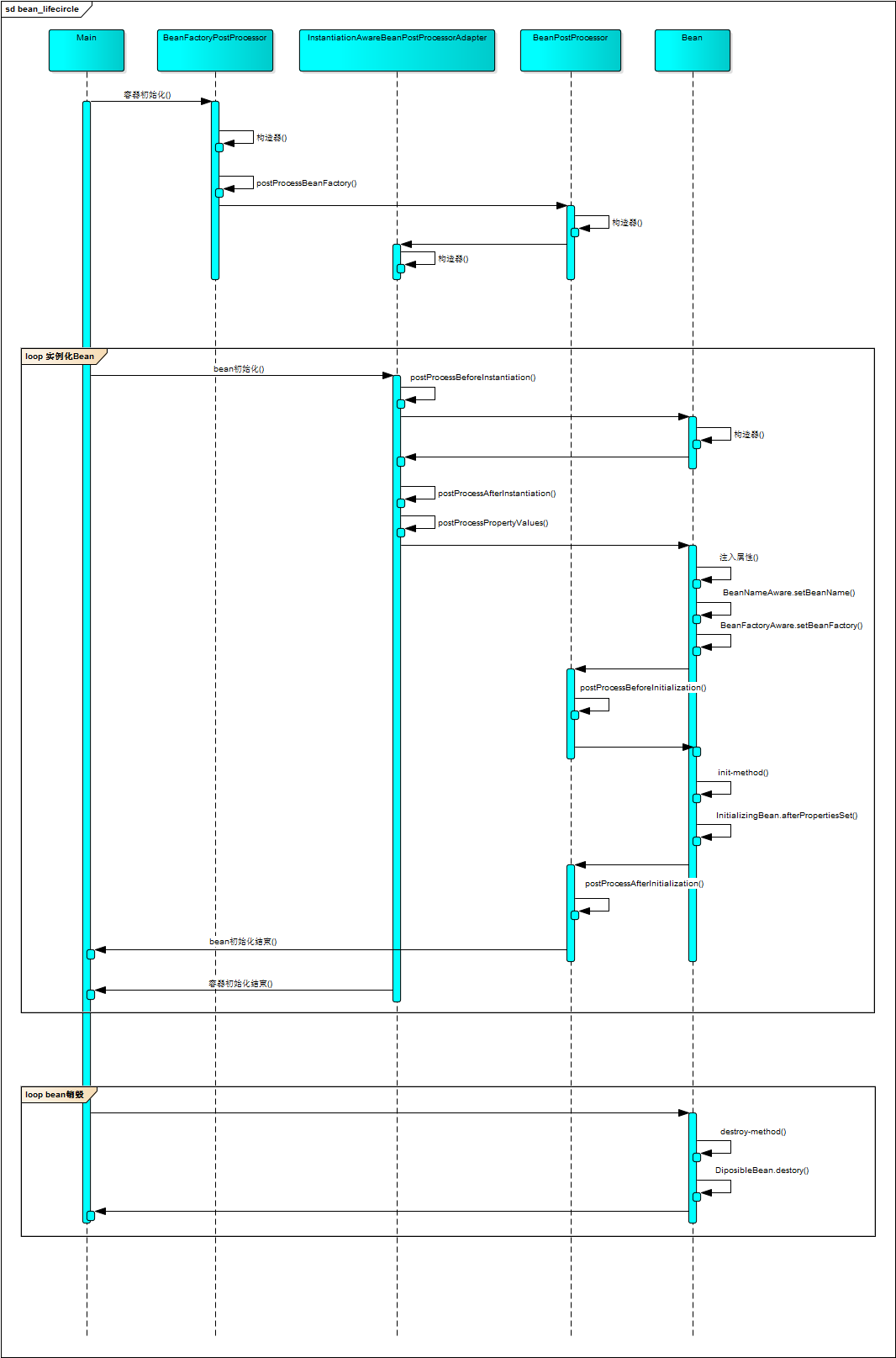
二、Bean加载顺序
2.1、情况一、容器初始化 (xxx implement InstantiationAwareBeanPostProcessor,BeanPostProcessor)
1、构造方法
2、Aware(BeanNameAware-->BeanFactoryAware-->-->ApplicationContextAware)
3、InitializingBean
4、InstantiationAwareBeanPostProcessor(Instantiation)
5、BeanPostProcessor(Initialization)
2.2、情况二、Bean加载
实例化部分
1、postProcessBeforeInstantiation(Instantiation)
2、构造方法
3、postProcessAfterInstantiation(Instantiation)
4、postProcessPropertyValues
注入属性部分
5、BeanNameAware
6、BeanFactoryAware等等Aware
初始化部分
7、postProcessBeforeInitialization
8、init-method
9、afterPropertiesSet
10、postProcessAfterInitialization
使用
销毁
11、destory-method
12、destory(DisposableBean)
3、用户可自定义接口
第一大类:影响多个Bean的接口
实现了这些接口的Bean会切入到多个Bean的生命周期中。正因为如此,这些接口的功能非常强大,Spring内部扩展也经常使用这些接口,例如自动注入以及AOP的实现都和他们有关。
- BeanPostProcessor
- InstantiationAwareBeanPostProcessor
第二大类:只调用一次的接口
这一大类接口的特点是功能丰富,常用于用户自定义扩展。
第二大类中又可以分为两类:
- Aware类型的接口
- 生命周期接口
无所不知的Aware
Aware类型的接口的作用就是让我们能够拿到Spring容器中的一些资源。基本都能够见名知意,Aware之前的名字就是可以拿到什么资源,例如BeanNameAware可以拿到BeanName,以此类推。调用时机需要注意:所有的Aware方法都是在初始化阶段之前调用的!
Aware接口众多,这里同样通过分类的方式帮助大家记忆。
Aware接口具体可以分为两组,至于为什么这么分,详见下面的源码分析。如下排列顺序同样也是Aware接口的执行顺序,能够见名知意的接口不再解释。
Aware Group1
- BeanNameAware
- BeanClassLoaderAware
- BeanFactoryAware
Aware Group2
- EnvironmentAware
- EmbeddedValueResolverAware 这个知道的人可能不多,实现该接口能够获取Spring EL解析器,用户的自定义注解需要支持spel表达式的时候可以使用,非常方便。
- ApplicationContextAware(ResourceLoaderAwareApplicationEventPublisherAwareMessageSourceAware) 这几个接口可能让人有点懵,实际上这几个接口可以一起记,其返回值实质上都是当前的ApplicationContext对象,因为ApplicationContext是一个复合接口,如下:
public interface ApplicationContext extends EnvironmentCapable, ListableBeanFactory, HierarchicalBeanFactory,
MessageSource, ApplicationEventPublisher, ResourcePatternResolver {}
这里涉及到另一道面试题,ApplicationContext和BeanFactory的区别,可以从ApplicationContext继承的这几个接口入手,除去BeanFactory相关的两个接口就是ApplicationContext独有的功能,这里不详细说明。
4、总结
Spring Bean的生命周期分为四个阶段和多个扩展点。扩展点又可以分为影响多个Bean和影响单个Bean。整理如下:
四个阶段
- 实例化 Instantiation
- 属性赋值 Populate
- 初始化 Initialization
- 销毁 Destruction
多个扩展点
- 影响多个Bean
- BeanPostProcessor
- InstantiationAwareBeanPostProcessor
- 影响单个Bean
- Aware
- Aware Group1
- BeanNameAware
- BeanClassLoaderAware
- BeanFactoryAware
- Aware Group2
- EnvironmentAware
- EmbeddedValueResolverAware
- ApplicationContextAware(ResourceLoaderAwareApplicationEventPublisherAwareMessageSourceAware)
- Aware Group1
- 生命周期
- InitializingBean
- DisposableBean
- Aware
三、处理循环依赖
3.1 什么是循环依赖
举个例子,这里有三个类 A、B、C,然后 A 关联 B,B 关联 C,C 又关联 A,这就形成了一个循环依赖。如果是方法调用是不算循环依赖的,循环依赖必须要持有引用。

循环依赖根据注入的时机分成两种类型:
- 构造器循环依赖。依赖的对象是通过构造器传入的,发生在实例化 Bean 的时候。
- 设值循环依赖。依赖的对象是通过 setter 方法传入的,对象已经实例化,发生属性填充和依赖注入的时候。
如果是构造器循环依赖,本质上是无法解决的。比如我们准调用 A 的构造器,发现依赖 B,于是去调用 B 的构造器进行实例化,发现又依赖 C,于是调用 C 的构造器去初始化,结果依赖 A,整个形成一个死结,导致 A 无法创建。
如果是设值循环依赖,Spring 框架只支持单例下的设值循环依赖。Spring 通过对还在创建过程中的单例,缓存并提前暴露该单例,使得其他实例可以引用该依赖。
3.2. 原型模式的循环依赖
Spring 不支持原型模式的任何循环依赖。检测到循环依赖会直接抛出 BeanCurrentlyInCreationException 异常。
使用了一个 ThreadLocal 变量 prototypesCurrentlyInCreation 来记录当前线程正在创建中的 Bean 对象,见 AbtractBeanFactory#prototypesCurrentlyInCreation:
1 /** Names of beans that are currently in creation */ 2 private final ThreadLocal<Object> prototypesCurrentlyInCreation = 3 new NamedThreadLocal<Object>("Prototype beans currently in creation");
在 Bean 创建前进行记录,在 Bean 创建后删除记录。见 AbstractBeanFactory.doGetBean:
1 ... 2 if (mbd.isPrototype()) { 3 // It's a prototype -> create a new instance. 4 Object prototypeInstance = null; 5 try { 6 7 // 添加记录 8 beforePrototypeCreation(beanName); 9 prototypeInstance = createBean(beanName, mbd, args); 10 } 11 finally { 12 // 删除记录 13 afterPrototypeCreation(beanName); 14 } 15 bean = getObjectForBeanInstance(prototypeInstance, name, beanName, mbd); 16 } 17 ... 18 见 AbtractBeanFactory.beforePrototypeCreation 的记录操作: 19 20 protected void beforePrototypeCreation(String beanName) { 21 Object curVal = this.prototypesCurrentlyInCreation.get(); 22 if (curVal == null) { 23 this.prototypesCurrentlyInCreation.set(beanName); 24 } 25 else if (curVal instanceof String) { 26 Set<String> beanNameSet = new HashSet<String>(2); 27 beanNameSet.add((String) curVal); 28 beanNameSet.add(beanName); 29 this.prototypesCurrentlyInCreation.set(beanNameSet); 30 } 31 else { 32 Set<String> beanNameSet = (Set<String>) curVal; 33 beanNameSet.add(beanName); 34 } 35 } 36 见 AbtractBeanFactory.beforePrototypeCreation 的删除操作: 37 38 protected void afterPrototypeCreation(String beanName) { 39 Object curVal = this.prototypesCurrentlyInCreation.get(); 40 if (curVal instanceof String) { 41 this.prototypesCurrentlyInCreation.remove(); 42 } 43 else if (curVal instanceof Set) { 44 Set<String> beanNameSet = (Set<String>) curVal; 45 beanNameSet.remove(beanName); 46 if (beanNameSet.isEmpty()) { 47 this.prototypesCurrentlyInCreation.remove(); 48 } 49 } 50 }
为了节省内存空间,在单个元素时 prototypesCurrentlyInCreation 只记录 String 对象,在多个依赖元素后改用 Set 集合。这里是 Spring 使用的一个节约内存的小技巧。
了解了记录的写入和删除过程好了,再来看看读取以及判断循环的方式。这里要分两种情况讨论。
- 构造函数循环依赖。
- 设置循环依赖。
这两个地方的实现略有不同。
如果是构造函数依赖的,比如 A 的构造函数依赖了 B,会有这样的情况。实例化 A 的阶段中,匹配到要使用的构造函数,发现构造函数有参数 B,会使用 BeanDefinitionValueResolver 来检索 B 的实例。见 BeanDefinitionValueResolver.resolveReference:
1 private Object resolveReference(Object argName, RuntimeBeanReference ref) { 2 3 ... 4 Object bean = this.beanFactory.getBean(refName); 5 ... 6 }
我们发现这里继续调用 beanFactory.getBean 去加载 B。
如果是设值循环依赖的的,比如我们这里不提供构造函数,并且使用了 @Autowire 的方式注解依赖(还有其他方式不举例了):
public class A {
@Autowired
private B b;
...
}
加载过程中,找到无参数构造函数,不需要检索构造参数的引用,实例化成功。接着执行下去,进入到属性填充阶段 AbtractBeanFactory.populateBean ,在这里会进行 B 的依赖注入。
为了能够获取到 B 的实例化后的引用,最终会通过检索类 DependencyDescriptor 中去把依赖读取出来,见 DependencyDescriptor.resolveCandidate :
public Object resolveCandidate(String beanName, Class<?> requiredType, BeanFactory beanFactory)
throws BeansException {
return beanFactory.getBean(beanName, requiredType);
}
发现 beanFactory.getBean 方法又被调用到了。
在这里,两种循环依赖达成了同一。无论是构造函数的循环依赖还是设置循环依赖,在需要注入依赖的对象时,会继续调用 beanFactory.getBean 去加载对象,形成一个递归操作。
而每次调用 beanFactory.getBean 进行实例化前后,都使用了 prototypesCurrentlyInCreation 这个变量做记录。按照这里的思路走,整体效果等同于 建立依赖对象的构造链。
prototypesCurrentlyInCreation 中的值的变化如下:

3.3 原型模式的设值依赖
调用判定的地方在 AbstractBeanFactory.doGetBean 中,所有对象的实例化均会从这里启动。
// Fail if we're already creating this bean instance:
// We're assumably within a circular reference.
if (isPrototypeCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
判定的实现方法为 AbstractBeanFactory.isPrototypeCurrentlyInCreation :
protected boolean isPrototypeCurrentlyInCreation(String beanName) {
Object curVal = this.prototypesCurrentlyInCreation.get();
return (curVal != null &&
(curVal.equals(beanName) || (curVal instanceof Set && ((Set<?>) curVal).contains(beanName))));
}
所以在原型模式下,构造函数循环依赖和设值循环依赖,本质上使用同一种方式检测出来。Spring 无法解决,直接抛出 BeanCurrentlyInCreationException 异常。
3.4. 单例模式的构造循环依赖
Spring 也不支持单例模式的构造循环依赖。检测到构造循环依赖也会抛出 BeanCurrentlyInCreationException 异常。
和原型模式相似,单例模式也用了一个数据结构来记录正在创建中的 beanName。见 DefaultSingletonBeanRegistry:
/** Names of beans that are currently in creation */
private final Set<String> singletonsCurrentlyInCreation =
Collections.newSetFromMap(new ConcurrentHashMap<String, Boolean>(16));
会在创建前进行记录,创建化后删除记录。
见 DefaultSingletonBeanRegistry.getSingleton
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
...
// 记录正在加载中的 beanName
beforeSingletonCreation(beanName);
...
// 通过 singletonFactory 创建 bean
singletonObject = singletonFactory.getObject();
...
// 删除正在加载中的 beanName
afterSingletonCreation(beanName);
}
记录和判定的方式见 DefaultSingletonBeanRegistry.beforeSingletonCreation :
protected void beforeSingletonCreation(String beanName) {
if (!this.inCreationCheckExclusions.contains(beanName) && !this.singletonsCurrentlyInCreation.add(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
}
这里会尝试往 singletonsCurrentlyInCreation 记录当前实例化的 bean。我们知道 singletonsCurrentlyInCreation 的数据结构是 Set,是不允许重复元素的,所以一旦前面记录了,这里的 add 操作将会返回失败。
比如加载 A 的单例,和原型模式类似,单例模式也会调用匹配到要使用的构造函数,发现构造函数有参数 B,然后使用 BeanDefinitionValueResolver 来检索 B 的实例,根据上面的分析,继续调用 beanFactory.getBean 方法。
所以拿 A,B,C 的例子来举例 singletonsCurrentlyInCreation 的变化,这里可以看到和原型模式的循环依赖判断方式的算法是一样:

- 加载 A。记录 singletonsCurrentlyInCreation = [a],构造依赖 B,开始加载 B。
- 加载 B,记录 singletonsCurrentlyInCreation = [a, b],构造依赖 C,开始加载 C。
- 加载 C,记录 singletonsCurrentlyInCreation = [a, b, c],构造依赖 A,又开始加载 A。
- 加载 A,执行到
DefaultSingletonBeanRegistry.beforeSingletonCreation,singletonsCurrentlyInCreation 中 a 已经存在了,检测到构造循环依赖,直接抛出异常结束操作。
3.5 单例模式的设值循环依赖
单例模式下,构造函数的循环依赖无法解决,但设值循环依赖是可以解决的。
这里有一个重要的设计:提前暴露创建中的单例。
我们理解一下为什么要这么做。
还是拿上面的 A、B、C 的的设值依赖做分析,
=> 1. A 创建 -> A 构造完成,开始注入属性,发现依赖 B,启动 B 的实例化
=> 2. B 创建 -> B 构造完成,开始注入属性,发现依赖 C,启动 C 的实例化
=> 3. C 创建 -> C 构造完成,开始注入属性,发现依赖 A
重点来了,在我们的阶段 1中, A 已经构造完成,Bean 对象在堆中也分配好内存了,即使后续往 A 中填充属性(比如填充依赖的 B 对象),也不会修改到 A 的引用地址。
所以,这个时候是否可以 提前拿 A 实例的引用来先注入到 C ,去完成 C 的实例化,于是流程变成这样。
=> 3. C 创建 -> C 构造完成,开始注入依赖,发现依赖 A,发现 A 已经构造完成,直接引用,完成 C 的实例化。
=> 4. C 完成实例化后,B 注入 C 也完成实例化,A 注入 B 也完成实例化。
这就是 Spring 解决单例模式设值循环依赖应用的技巧。流程图为:

为了能够实现单例的提前暴露。Spring 使用了三级缓存,见 DefaultSingletonBeanRegistry:
/** Cache of singleton objects: bean name --> bean instance */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(256);
/** Cache of singleton factories: bean name --> ObjectFactory */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<String, ObjectFactory<?>>(16);
/** Cache of early singleton objects: bean name --> bean instance */
private final Map<String, Object> earlySingletonObjects = new HashMap<String, Object>(16);
这三个缓存的区别如下:
- singletonObjects,单例缓存,存储已经实例化完成的单例。
- singletonFactories,生产单例的工厂的缓存,存储工厂。
- earlySingletonObjects,提前暴露的单例缓存,这时候的单例刚刚创建完,但还会注入依赖。
从 getBean("a") 开始,添加的 SingletonFactory 具体实现如下:
protected Object doCreateBean ... {
...
addSingletonFactory(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
return getEarlyBeanReference(beanName, mbd, bean);
}
});
...
}
可以看到如果使用该 SingletonFactory 获取实例,使用的是 getEarlyBeanReference 方法,返回一个未初始化的引用。
读取缓存的地方见 DefaultSingletonBeanRegistry :
1 protected Object getSingleton(String beanName, boolean allowEarlyReference) { 2 Object singletonObject = this.singletonObjects.get(beanName); 3 if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) { 4 synchronized (this.singletonObjects) { 5 singletonObject = this.earlySingletonObjects.get(beanName); 6 if (singletonObject == null && allowEarlyReference) { 7 ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName); 8 if (singletonFactory != null) { 9 singletonObject = singletonFactory.getObject(); 10 this.earlySingletonObjects.put(beanName, singletonObject); 11 this.singletonFactories.remove(beanName); 12 } 13 } 14 } 15 } 16 return (singletonObject != NULL_OBJECT ? singletonObject : null); 17 }
先尝试从 singletonObjects 和 singletonFactory 读取,没有数据,然后尝试 singletonFactories 读取 singletonFactory,执行 getEarlyBeanReference 获取到引用后,存储到 earlySingletonObjects 中。
这个 earlySingletonObjects 的好处是,如果此时又有其他地方尝试获取未初始化的单例,可以从 earlySingletonObjects 直接取出而不需要再调用 getEarlyBeanReference。
从流程图上看,实际上注入 C 的 A 实例,还在填充属性阶段,并没有完全地初始化。等递归回溯回去,A 顺利拿到依赖 B,才会真实地完成 A 的加载。
四、SPRING事务隔离机制
1>PROPAGATION_REQUIRED:支持当前事务,假设当前没有事务。就新建一个事务。
2>PROPAGATION_SUPPORTS:支持当前事务,假设当前没有事务,就以非事务方式运行。
3>PROPAGATION_MANDATORY:支持当前事务,假设当前没有事务,就抛出异常。
4>PROPAGATION_REQUIRES_NEW:新建事务,假设当前存在事务。把当前事务挂起。
5>PROPAGATION_NOT_SUPPORTED:以非事务方式运行操作。假设当前存在事务,就把当前事务挂起。
6>PROPAGATION_NEVER:以非事务方式运行,假设当前存在事务,则抛出异常。
7>PROPAGATION_NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则进行与PROPAGATION_REQUIRED类似的操作。