主从模式幼教主仆模式,这种模式的核心思想试讲一个原始的任务,变为不同的子任务,就像一个主人把任务分配给自己的多个仆人一样进行完成,当仆人完成各自 的子任务之后再交还结果给自己的主人,主人再把所有仆人的结果整合到一起,得到一个真正的综合结果,这就是大概的运行思路,但是要仆人进行运算就得给仆人 时间和场地,所以程序还要专门的生出让仆人工作的场地,就是说要提供专门的线程来让子程序进行运算,所以我们可以看出来,主从模式实际是一种多线程模式。
多线程模式就有多线程模式的好处,首先因为线程较多,我们程序中的仆人可以一起进行运算,这就导致了运行效率的提高,也提高了程序的性能,让程序运行的资源利用率提高,进而造成的结果就是程序运行速度的提高,计算精度的提高,由于线程之多,我们程序的容错率也大大提高。
但同时这也造就了一些无法改变的缺点,由于线程的不断增多,会导致硬件的内存会被不断的占用,导致内从在运行大程序时不一定够用,而且由于主仆之间 不断地进行数据的交流,交流必然需要时间,这就导致了时间上会产生一些问题,主人要一直协调与不同仆人之间的时间交流问题,导致了数据交换和运行的不及时 性,仆人之间也会互相争夺资源来进行自己的运算。
- 在数据库复制中,主数据库被认为是权威的来源,并且要与之同步
- 在计算机系统中与总线连接的外围设备(主和从驱动器)
我们可以把主从模式认为是一种一对多的模式,由一个主模式对应着多个它下属的从模式。这种模式我们首先可以利用它来进行数据库标的设计,建立一个数 据库的主从表,而最基本的就是一个主表,一个从表。进而利用这种结构就可以完成一种最简单的程序的搭建,比如说百度贴吧的最简化搭建,每个人都可以在贴吧 里帖子,每一个不同的吧就可以看做是一个主表,每个人发的帖子就可以看做是一个从表。从这个例子中,我们很明显的就可以知道主从关系是什么对应关系了,主 表就是贴吧,从表就是吧里发的帖子,这两者就是一种一对多的关系,不但如此,每个帖子因为有人可以回复,一个帖子就拥有了多个回复,这又构成了一个新的主 从关系表,凡是类似这种的都可以利用主从模式来进行数据库的建立。
并行计算下模式举例
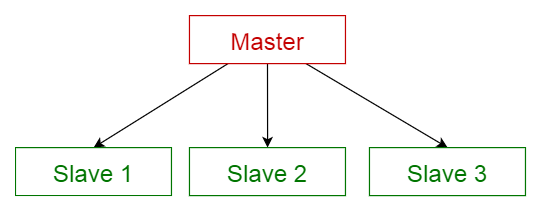
在分布式的系统中,这个模式还是比较常用的,简单的说,主从(Master-Slave)与进程-线程的关系类似,Master只有一台机器作为Master,其他机器作为Slave,这些机器同时运行组成了集群.Master作为任务调度者,给多个Slave分配计算任务,当所有的Slave将任务完成之后,最后由Master汇集结果,这个其实也是MapReduce思想所在.

例如在Hadoop中,HDFS采用了基于Master/Slave主从架构的分布式文件系统,一个HDFS集群包含一个单独的Master节点和多个Slave节点服务器,这里的一个单独的Master节点的含义是HDFS系统中只存在一个逻辑上的Master组件。一个逻辑的Master节点可以包括两台物理主机,即两台Master服务器、多台Slave服务器。一台Master服务器组成单NameNode集群,两台Master服务器组成双NameNode集群,并且同时被多个客户端访问,所有的这些机器通常都是普通的Linux机器,运行着用户级别(user-level)的服务进程.

在上图中展示了 HDFS 的 NameNode , DataNode 以及客户端之间的存取访问关系, NameNode 作为 Master 服务,它负责管理文件系统的命名空间和客户端对文件的访问。NameNode会保存文件系统的具体信息,包括文件信息、文件被分割成具体block块的信息、以及每一个block块归属的DataNode的信息。对于整个集群来说,HDFS通过NameNode对用户提供了一个单一的命名空间。DataNode作为slave服务,在集群中可以存在多个。通常每一个DataNode都对应于一个物理节点。DataNode负责管理节点上它们拥有的存储,它将存储划分为多个block块,管理block块信息,同时周期性的将其所有的block块信息发送给NameNode。