【学习总结】《大话数据结构》- 总
第5章串-代码链接
启示:
-
串(string)
串是由零个或多个字符组成的有限序列,又名叫字符串。
目录
========================================
5.1 开场白
- 一些可以略过的场面话...
- 回文诗等引入字符串
========================================
5.2 串的定义
-
串(string):由零个或多个字符组成的有限序列,又名叫字符串。

-
相关概念:
-
空格串:只包含空格的串。
-
注意:与空串区别,空格串是有内容有长度的,而且可以不止一个空格
-
-
子串:串中任意个数的连续字符组成的子序列,称为该串的子串。
主串:相应地,包含子串的串,称为主串。
-
子串在主串中的位置:子串的第一个字符在主串中的序号。
-
-
========================================
5.3 串的比较
-
串的比较:通过组成串的字符之间的编码来进行的
-
而字符的编码:指的是字符在对应字符集中的序号
-
-
ASCII 和 Unicode
-
ASCII码:用8为二进制数表示一个字符,总共可以表示256个字符
-
Unicode码:用16位二进制数表示一个字符,总共有216个字符,约65万多个字符
(PS:两个字节应该是65000吧,怎么65万了???)
-
为了和ASCII码兼容,Unicode码的前256个字符与ASCII码完全相同。
-
-
串相等:长度相等,各个对应位置的字符相等。

-
串的大小判断:

综上,即从第一个开始,分别遍历两串,当某i项不同时,可以分辨大小
========================================
5.4 串的抽象数据类型
-
串与线性表的比较:
-
线性表:更关注单个元素的操作,如查找一个元素,插入或删除一个元素
-
串:更多是查找子串位置、得到指定位置子串、替换子串等操作
-



-
举例一个Index操作的实现代码


========================================
5.5 串的存储结构
-
串的存储结构与线性表类似,分为两类:顺序和链式
-
串的顺序存储结构
-
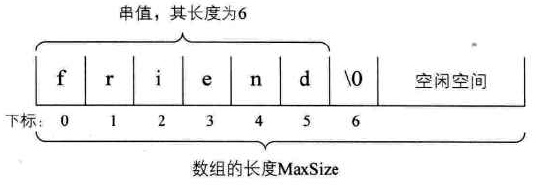
定义:用一组地址连续的存储单元来存储串中的字符序列。
-
按照预定义大小,为每个定义的串分配一个固定长度的存储区,一般用定长数组来定义。
-
一般可以将实际的串长值保存在数组的0下标位置,或者在数组的最后一个下标位置
-
但有的语言规定在串值后面加一个不计入串长度的结束标记符号“�”来表示串值的终结(但占用一个空间)
-
-
由于过于不便,串的顺序存储操作有一些变化:串值的存储空间可在程序执行过程中动态分配而得
比如堆:可由c语言动态分配函数malloc()和free()来管理
-
串的链式存储结构
-
若一个结点存放一个字符,会存在很大的空间浪费
-
故串的链式可以一个结点放多个字符,最后一个结点若不满,可用#或其他非串值字符补全
-

-
这里:一个结点存多少个字符才合适就变得很重要,会直接影响串处理的效率
-
弊端:窜的链式除了连接两串操作方便,总的来说比如顺序存储灵活,性能也不如。
========================================
5.6 朴素的模式匹配算法
-
模式匹配的定义:
-
子串(又称模式串)的定位操作通常称做串的模式匹配,是串中最重要的操作之一。
(比如:找一个单词在一篇文章中的定位问题,一篇文章相当于一个大字符串)
-
-
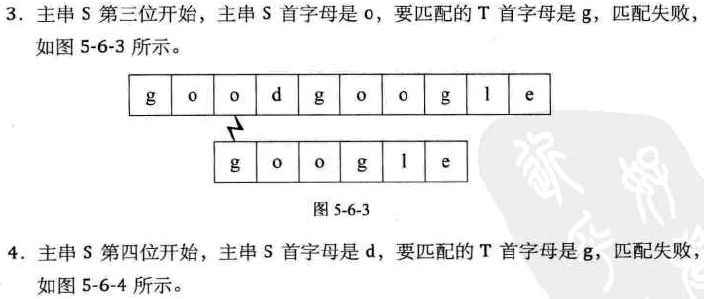
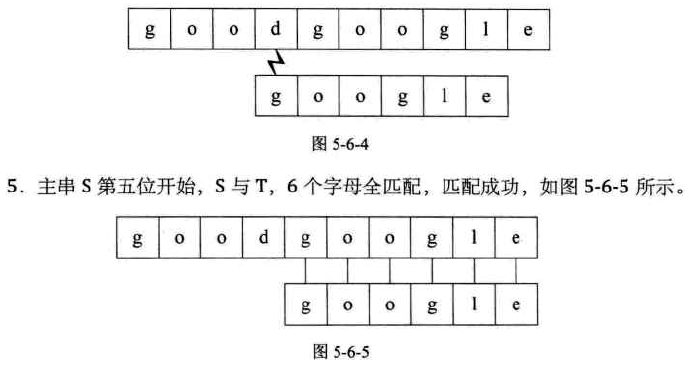
朴素的匹配方法(BRUTE FORCE算法,BF算法):
-
对主串的每个字符作为子串开头,与要匹配的字符串进行匹配
-
对主串做大循环,每个字符开头做要匹配子串的长度的小循环,直到匹配成功或全部遍历完成为止
-
-
图示:

-
代码实现:
(注:不考虑串的其他操作的代码,上一个Index代码中有多个其他操作)


-
时间复杂度分析:
-
n:主串长度,m:要匹配子串长度
-
最好情况:O(1) -- 第一次比较就找到
- (没有循环,比较次数是子串长度值,是个常数)
-
平均情况:O(n+m)
- 根据等概率原则,平均是(n+m)/2次查找。
- (严格讲,书中所举的例子,abcdegoogle匹配google,不是m+n,是(m-n)+n,不知道怎么就弄成m+n了。。)
-
最坏的情况: O(m×n) (注:(n-m+1)×m)
- 每遍比较都在最后出现不等,即每遍最多比较m次,最多比较n-m+1遍,总的比较次数最多为m(n-m+1)
-
<存疑,只有部分有m+n这个说法> 注:虽然,朴素的模式匹配,时间复杂度比较大,但是实际中,一般情况(除非模式串和主串之间存在很多的部分匹配的时候,因为此时每遍需要比较的次数很多,相乘不能近似),真正的执行时间是近似于 O(n+m) 的
-
========================================
5.7 KMP模式匹配算法
-
引入:
-
KMP算法:由三位前辈发表的一个模式匹配算法,可以大大避免重复遍历的情况,称之为克努特-莫里斯-普拉特算法,检查KMP算法。
-
-
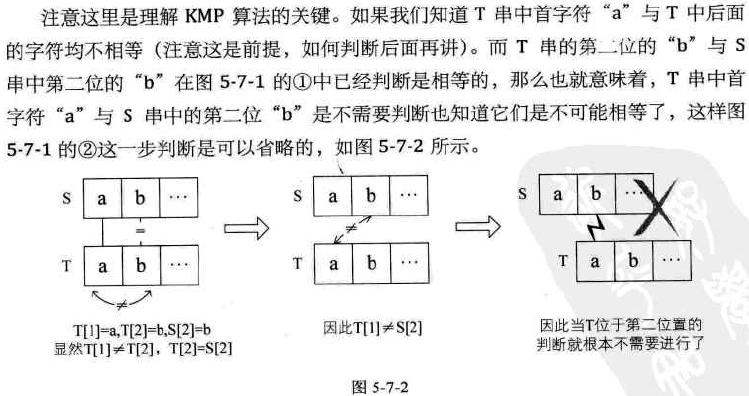
KMP算法原理
-
主串S与模式串T有部分相同子串时,可以简化朴素匹配算法中的循环流程
-
例子1:两串只有一部分相等时,S="abcdefgab", T="abcdex"
-
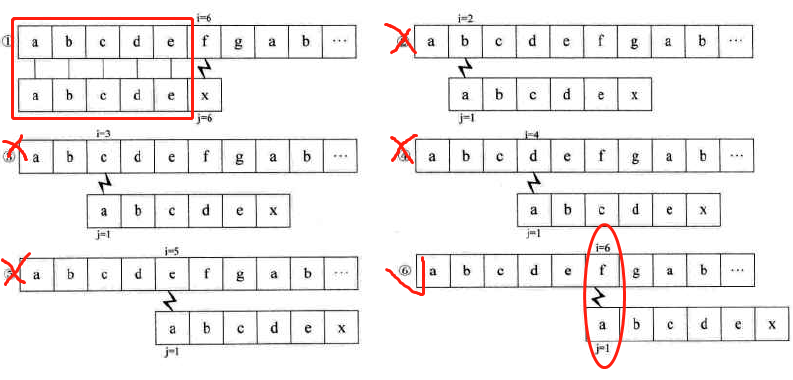

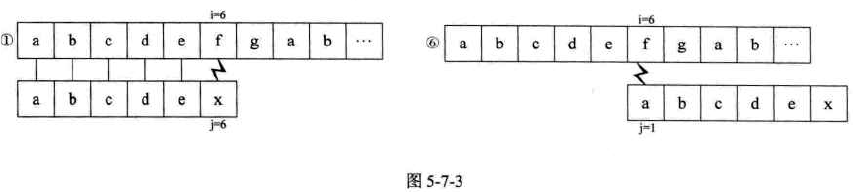
-
例子2:两串有不止一部分相等时,S="abcabcabc", T="abcabx"
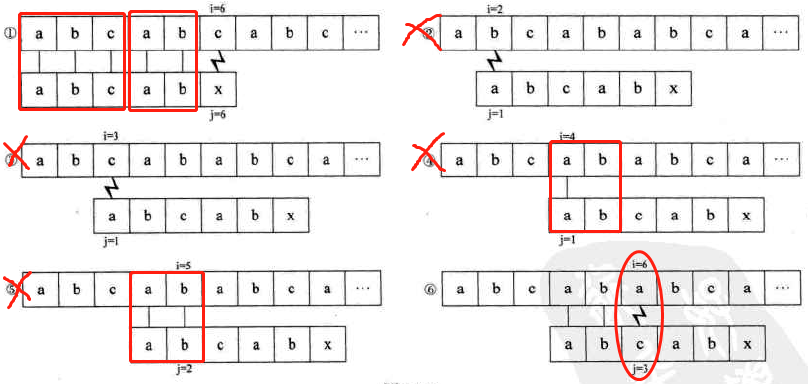

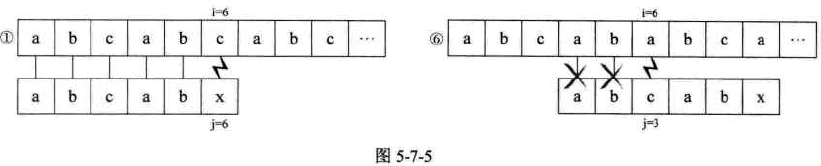
-
next数组
-
定义:
-


-
注:
-
每次只先判断是否符合中间,并且只看1到j-1的串,并且只看前缀最长能和后缀重复的个数
-
前后缀若有n个字符相等,k就是n+1
-
-
例1:T="abcdex"
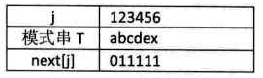

-
例2:T="abcabx"


-
例3:T="ababaaaba"


-
例4:T="aaaaaaaab"



-
KMP模式匹配算法的代码实现
-
next数组
-

-
KMP算法


-
KMP算法的时间复杂度:O(m+n)
-
get_next的时间复杂度:O(m)
-
while循环的时间复杂度:O(n)
-
-
KMP算法的改进
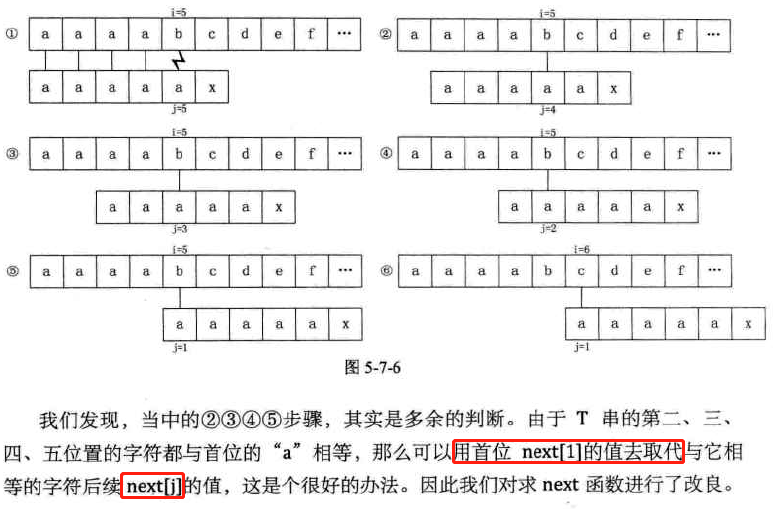
-
代码实现:


-
nextval数组值推导
-
注:
-
根据第j个的next值找它的next值x对应的第x个字符,并判断第j个和第x个字符是否相等
-
若不相等,保持val值等于next值;若相等,val值等于第x个值的val值
-
-

-
例1:T="ababaaaba"


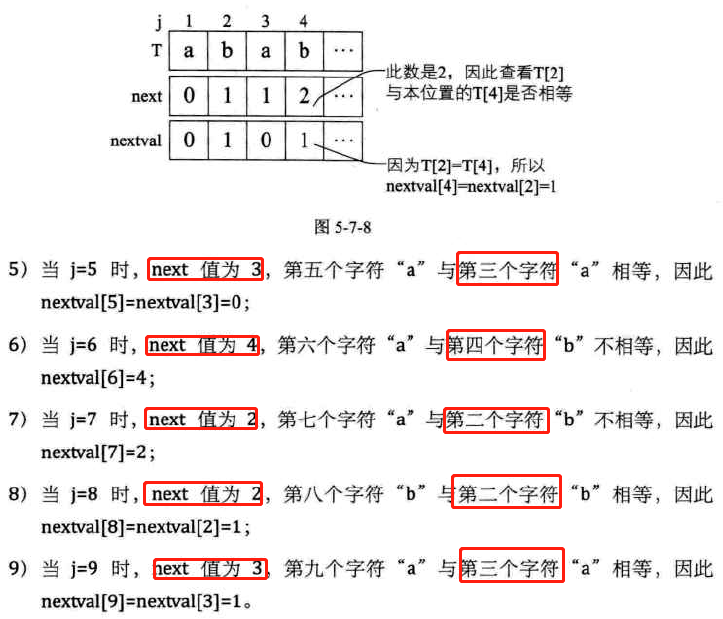
-
例2:T="aaaaaaaab"


========================================
5.8 总结回顾
-
串定义
-
KMP算法
-
next数组和nextval数组常见考点
========================================
5.9 结尾语
-
回文诗千古力作“璇玑图”666
