本节内容
1. 函数基本语法及特性
2. 参数与局部变量
3. 返回值
嵌套函数
4.递归
5.匿名函数
6.函数式编程介绍
7.高阶函数
8.内置函数
温故知新
1. 集合
主要作用:
- 去重
- 关系测试, 交集\差集\并集\反向(对称)差集


1 >>> a = {1,2,3,4}
2 >>> b = {3,4,5,6}
3 >>> a
4 {1, 2, 3, 4}
5 >>> type(a)
6 <class 'set'>
7 >>> a.symmetric_difference(b)
8 {1, 2, 5, 6}
9 >>> b.symmetric_difference(a)
10 {1, 2, 5, 6}
11 >>>
12 >>>
13 >>> a.difference(b)
14 {1, 2}
15 >>> a.union(b)
16 {1, 2, 3, 4, 5, 6}
17 >>> a.issubset(b)
18 False
19 >>>
2. 元组
只读列表,只有count, index 2 个方法。
作用:如果一些数据不想被人修改, 可以存成元组,比如身份证列表。
3. 字典
key-value对特性:
- 无顺序
- 去重
- 查询速度快,比列表快多了
- 比list占用内存多
为什么会查询速度会快呢?因为他是hash类型的,那什么是hash呢?
哈希算法将任意长度的二进制值映射为较短的固定长度的二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一且极其紧凑的数值表示形式。如果散列一段明文而且哪怕只更改该段落的一个字母,随后的哈希都将产生不同的值。要找到散列为同一个值的两个不同的输入,在计算上是不可能的,所以数据的哈希值可以检验数据的完整性。一般用于快速查找和加密算法
dict会把所有的key变成hash 表,然后将这个表进行排序,这样,你通过data[key]去查data字典中一个key的时候,python会先把这个key hash成一个数字,然后拿这个数字到hash表中看没有这个数字, 如果有,拿到这个key在hash表中的索引,拿到这个索引去与此key对应的value的内存地址那取值就可以了。
待续 ...
4. 字符编码
先说python2
- py2里默认编码是ascii。
- 文件开头那个编码声明是告诉解释此代码(文件)的程序 以什么编码格式 把这段代码读入到内存(存储于内存的这段代码是以bytes二进制格式存储的,但是即使是2进制流,也可以按不同的编码格式转成2进制流)。
- 如果在文件头声明了#_*_coding:utf-8_*_,就可以写中文了, 不声明的话,python在处理这段代码时按ascii,显然会出错, 加了这个声明后,里面的代码就全是utf-8格式了。
- 在有#_*_coding:utf-8_*_的情况下,你在声明变量如果写成name=u"大保健",那这个字符就是unicode格式,不加这个u,那你声明的字符串就是utf-8格式。
- utf-8 to gbk怎么转,utf8先decode成unicode,再encode成gbk。
再说python3
- py3里默认文件编码就是utf-8,所以可以直接写中文,也不需要文件头声明编码了。
- 你声明的变量默认是unicode编码,不是utf-8, 因为默认即是unicode了(不像在py2里,你想直接声明成unicode还得在变量前加个u), 此时你想转成gbk的话,直接your_str.encode("gbk")即可以。
- 但py3里,你在your_str.encode("gbk")时,感觉好像还加了一个动作,就是就是encode的数据变成了bytes里,我擦,这是怎么个情况,因为在py3里,str and bytes做了明确的区分,你可以理解为bytes就是2进制流,你会说,我看到的不是010101这样的2进制呀, 那是因为python为了让你能对数据进行操作而在内存级别又帮你做了一层封装,否则让你直接看到一堆2进制,你能看出哪个字符对应哪段2进制么。
- 那你说,在py2里好像也有bytes呀,是的,不过py2里的bytes只是对str做了个别名(python2里的str就是bytes, py3里的str是unicode),没有像py3一样给你显示的多出来一层封装,但其实其内部还是封装了的。 这么讲吧, 无论是2还是三, 从硬盘到内存,数据格式都是 010101二进制到-->b'xe4xbdxa0xe5xa5xbd' bytes类型-->按照指定编码转成你能看懂的文字
编码应用比较多的场景应该是爬虫了,互联网上很多网站用的编码格式很杂,虽然整体趋向都变成utf-8,但现在还是很杂,所以爬网页时就需要你进行各种编码的转换,不过生活正在变美好,期待一个不需要转码的世界。
步入正题:
1. 函数基本语法及特性
函数是什么?
函数一词来源于数学,但编程中的「函数」概念,与数学中的函数是有很大不同的,具体区别,我们后面会讲,编程中的函数在英文中也有很多不同的叫法。在BASIC中叫做subroutine(子过程或子程序),在Pascal中叫做procedure(过程)和function,在C中只有function,在Java里面叫做method。
定义: 函数是指将一组语句的集合通过一个名字(函数名)封装起来,要想执行这个函数,只需调用其函数名即可。
特性:
- 减少重复代码
- 使程序变的可扩展
- 使程序变得易维护
语法定义
def sayhi(): # sayhi 函数名
print("Hello, I'm nobody!")
sayhi() # 调用函数
可以带参数
# 下面这段代码
a,b = 5,8
c = a**b
print(c)
# 改成用函数写
def calc(x,y):
res = x**y
return res # 返回函数执行结果
c = calc(a,b) # 结果赋值给c变量
print(c)
2. 函数参数与局部变量
形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量。
实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值。

默认参数
def stu_register(name,age,country,course):
print("----注册学生信息------")
print("姓名:",name)
print("age:",age)
print("国籍:",country)
print("课程:",course)
stu_register("王山炮",22,"CN","python_devops")
stu_register("张叫春",21,"CN","linux")
stu_register("刘老根",25,"CN","linux")
发现 country 这个参数 基本都 是"CN", 就像我们在网站上注册用户,像国籍这种信息,你不填写,默认就会是 中国, 这就是通过默认参数实现的,把country变成默认参数非常简单。
def stu_register(name,age,course,country="CN"):
这样,这个参数在调用时不指定,那默认就是CN,指定了的话,就用你指定的值。
另外,你可能注意到了,在把country变成默认参数后,我同时把它的位置移到了最后面,为什么呢?
1 #!/usr/bin/env python
2 # -*- coding:utf-8 -*-
3 # Author: antcolonies
4
5 def stu_register(name, age, country='CN', course):
6 print("----注册学生信息------")
7 print("姓名:", name)
8 print("age:", age)
9 print("国籍:", country)
10 print("课程:", course)
11
12
13 # stu_register("王山炮", 22, "python_devops")
14 # stu_register("张叫春", 21, "linux")
15 stu_register("刘老根", 25, "Japan", "linux")
16
17 '''
18 def stu_register(name, age, country='CN', course):
19 ^
20 SyntaxError: non-default argument follows default argument
21 '''
关键参数
正常情况下,给函数传参数要按顺序,不想按顺序就可以用关键参数,只需指定参数名即可,但记住一个要求就是,关键参数必须放在位置参数之后。
stu_register(age=22,name='alex',course="python"):
非固定参数
若你的函数在定义时不确定用户想传入多少个参数,就可以使用非固定参数。
def stu_register(name,age,*args): # *args 会把多传入的参数变成一个元组形式
print(name,age,args)
stu_register("Alex",22)
# 输出
# Alex 22 () #后面这个()就是args,只是因为没传值,所以为空
stu_register("Jack",32,"CN","Python")
# 输出
# Jack 32 ('CN', 'Python')
还可以有一个**kwargs:
def stu_register(name,age,*args,**kwargs): # *kwargs 会把多传入的参数变成一个dict形式
print(name,age,args,kwargs)
stu_register("Alex",22)
# 输出
# Alex 22 () {} # 后面这个{}就是kwargs,只是因为没传值,所以为空
stu_register("Jack",32,"CN","Python",sex="Male",province="ShanDong")
# 输出
# Jack 32 ('CN', 'Python') {'province': 'ShanDong', 'sex': 'Male'}
1 #!/usr/bin/env python
2 # -*- coding:utf-8 -*-
3 # Author: antcolonies
4
5
6 '''
7 def test(x,y):
8 print(x)
9 print(y)
10
11
12 test(1,2) # 位置参数,与形参一一对应
13 1
14 2
15
16 test(y=2,x=1) # 关键参数,与形参顺序无关
17 1
18 2
19
20 test(x=2,3) # 关键参数不能放于位置参数前
21 SyntaxError: non-keyword arg after keyword arg
22
23 test(3,x=2)
24 TypeError: test() got multiple values for argument 'x'
25
26 test(3,y=2)
27 3
28 2
29
30 '''
31
32
33 def test(x,y,z):
34 print(x)
35 print(y)
36 print(z)
37
38 # test(y=2,x=1,z=3)
39 # 1
40 # 2
41 # 3
42
43 # test(3,x=1,z=2)
44 # TypeError: test() got multiple values for argument 'x'
45
46 # test(3,y=1,z=2)
47 # 3
48 # 1
49 # 2
1 #!/usr/bin/env python
2 # -*- coding:utf-8 -*-
3 # Author: antcolonies
4
5 '''
6 def test(x, y):
7 print(x)
8 print(y)
9
10 test(1)
11 TypeError: test() missing 1 required positional argument: 'y'
12
13 test(1,2,3)
14 TypeError: test() takes 2 positional arguments but 3 were given
15 '''
16
17 # def test(x, y=3): # y = 3 为默认参数
18 # print(x)
19 # print(y)
20
21 # test(1)
22 # 1
23 # 3
24
25 # test(1,10)
26 # 1
27 # 10
28
29 # 默认参数特点:函数调用时,默认参数非必传
30
31
32 # def test(x=4, y): # SyntaxError: non-default argument follows default argument
33 # print(x)
34 # print(y)
35
36
37
38 def test(x,y,z=8):
39 print(x)
40 print(y)
41 print(z)
42
43 # test(3)
44 # TypeError: test() missing 1 required positional argument: 'y'
45
46 # test(2,4)
47 # 2
48 # 4
49 # 8
50
51 # test(2,4,10)
52 # 2
53 # 4
54 # 10
55
56 # test(2,z=4,y=10)
57 # 2
58 # 10
59 # 4
1 #!/usr/bin/env python
2 # -*- coding:utf-8 -*-
3 # Author: antcolonies
4
5 '''
6 # *args: 接收n个位置参数,转换成元组形式
7 def test(*args): # 传递不固定参数
8 print(args)
9
10 test(1,2,3,4,5,10) # (1, 2, 3, 4, 5, 10)
11 test(*[1,2,4,5]) # args = tuple([1,2,4,5]) (1, 2, 4, 5)
12
13
14 def test1(x,*args):
15 print(x) # 1
16 print(args) # (2, 4, 6, 7, 89, 10)
17
18 test1(1,2,4,6,7,89,10)
19 '''
20
21 '''
22 # **kwargs:接收n个关键字参数转换成字典的方式
23 def test2(**kwargs):
24 print(kwargs)
25 print(kwargs['name'])
26 print(kwargs['age'])
27 print(kwargs['gender'])
28
29 test2(name='alex',age=8,gender='F') # 关键字参数 {'gender': 'F', 'age': 8, 'name': 'alex'}
30 test2(**{'name':'alex','age':8,'gender':'F'}) # {'age': 8, 'name': 'alex'}
31 '''
32
33 '''
34 def test3(name,**kwargs):
35 print(name)
36 print(kwargs)
37
38 # test3('alex','xxxxx')
39 # TypeError: test3() takes 1 positional argument but 2 were given
40
41 # test3('alex',age=18,gender='F')
42 # alex
43 # {'age': 18, 'gender': 'F'}
44
45 # test3('alex')
46 # 'alex'
47 # {}
48 '''
49
50 '''
51 def test4(name,**kwargs,age=18): SyntaxError: invalid syntax
52 print(name)
53 print(age)
54 print(kwargs)
55 '''
56
57 '''
58 def test5(name,age=18,**kwargs):
59 print(name)
60 print(age)
61 print(kwargs)
62
63 # test5('alex',gender='F',hobby='tesla',age=3)
64 # alex
65 # 3
66 # {'gender': 'F', 'hobby': 'tesla'}
67
68 # test5('alex',34,gender='F',hobby='tesla',age=3)
69 # TypeError: test5() got multiple values for argument 'age'
70 '''
71
72 def test6(name,age=18,*args,**kwargs):
73 print(name)
74 print(age)
75 print(args)
76 print(kwargs)
77 logger('TEST4')
78
79 def logger(source):
80 print('from %s' %source)
81
82 test6('alex',34,gender='F',hobby='tesla')
83
84 # alex
85 # 34
86 # ()
87 # {'gender': 'F', 'hobby': 'tesla'}
88 # from TEST4
全局与局部变量
1 #!/usr/bin/env python
2 # -*- coding:utf-8 -*-
3 # Author: antcolonies
4
5 '''
6 school = 'Fire' # 全局变量
7
8 def change_name(name):
9 # global school # 修改全局变量
10 print('before changing ', name)
11 name = 'Alex Li' # 局部变量
12 school = 'Ted'
13 print('after changing ', name)
14
15 name = 'alex'
16 change_name(name)
17 print(school)
18 print(name)
19
20 # before changing alex
21 # after changing Alex Li
22 # Fire
23 # alex
24 '''
25
26 '''
27 def change_name_1():
28 global name 坚决不能在函数内修改全局变量,容易发生异常,不利于维护
29 name = 'alex'
30
31 change_name_1()
32 print(name) # alex
33 '''
34
35 name = ['Ted','Shooter','Kung']
36 def change_name(name):
37 name[0] = 'Alex Li' # 引用关系,类似于C语言中的通过函数指针修改源数据
38 print(name)
39
40 change_name(name)
41 print(name)
42
43 # ['Alex Li', 'Shooter', 'Kung']
44 # ['Alex Li', 'Shooter', 'Kung']
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 # Author: antcolonies 4 5 def gandpa(): 6 x = 'gandapa' 7 def dad(): 8 # x = 'dady' 9 def son(): 10 # x = 'sons' 11 print('x = ',x) 12 return son() 13 return dad() 14 15 gandpa()
3. 函数的返回值
要想获取函数的执行结果,就可以用return语句把结果返回(可以是任何类型的数据对象和函数等)
注意:
- 函数在执行过程中只要遇到return语句,就会停止执行并返回结果,so 也可以理解为 return 语句代表着函数的结束
- 如果未在函数中指定return,那这个函数的返回值为None
1 #!/usr/bin/env python
2 # -*- coding:utf-8 -*-
3 # Author: antcolonies
4
5 def func():
6 print('return values.')
7 return 1,'string',[1,2,{1,'list'}],{'key':'values','name':'Ted'}
8
9 val = func()
10 print(val)
11 print(type(val))
12
13 '''
14 >>> return values.
15 >>> (1, 'string', [1, 2, {1, 'list'}], {'key': 'values', 'name': 'Ted'})
16 >>> <class 'tuple'>
17 '''
插入知识点:嵌套函数
定义:在一个函数体内,定义的一个完整的函数(嵌套函数),嵌套函数又叫内部函数;被嵌套的函数叫做该嵌套函数的外部函数;
函数可以多重嵌套。
请看以下代码:
1 #!/usr/bin/env python
2 # -*- coding:utf-8 -*-
3 # Author: antcolonies
4
5 def test1():
6 print('in the test1.')
7 def innertest(): # 函数的嵌套
8 print('inner func.')
9 test() # 外部函数的调用
10 innertest() # 嵌套函数的调用
11
12 def test():
13 print('in the test.')
14
15 test1()
16 innertest() # 嵌套函数的作用域仅限于其外部函数体范围
17
18 '''
19 innertest()
20 NameError: name 'innertest' is not defined
21 in the test1.
22 in the test.
23 inner func.
24 '''
1 #!/usr/bin/env python
2 # -*- coding:utf-8 -*-
3 # Author: antcolonies
4
5 def gandpa():
6 x = 'gandapa'
7 def dad():
8 # x = 'dady'
9 def son():
10 # x = 'sons'
11 print('x = ',x)
12 return son()
13 return dad()
14
15 gandpa()
4. 递归
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
def calc(n):
print(n)
if int(n/2) ==0:
return n
return calc(int(n/2))
calc(10)
输出:
10
5
2
1
递归特性:
1. 必须有一个明确的结束条件;
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少;
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)。
特点
要求
堆栈扫盲: http://www.cnblogs.com/ant-colonies/p/6654993.html
递归函数实际应用案例,二分查找
1 #!/usr/bin/env python
2 # -*- coding:utf-8 -*-
3 # Author: antcolonies
4
5 data = [1, 3, 5, 10, 50, 25, 60, 99, 72, 0, 4, 66]
6
7 def binary_search(dataset, find_num):
8 dataset.sort()
9 print(dataset)
10
11 length = len(dataset)
12 if length > 1:
13 mid = int(length/2)
14 if dataset[mid] == find_num:
15 print('got the number %s' %dataset[mid])
16 elif dataset[mid] < find_num:
17 print('�33[31;1mthe number you finding is on the right of %s'% dataset[mid])
18 return binary_search(dataset[mid + 1: ], find_num)
19 else:
20 print('�33[31;1mthe number you finding is on the left of %s' % dataset[mid])
21 return binary_search(dataset[ :mid + 1], find_num)
22 else:
23 if dataset[0] == find_num:
24 print('got the number %s' % dataset[0])
25 else:
26 print('Unfortunately, the number %s you finding is out of the list' %find_num)
27
28 print(data)
29 num = int(input('input a search number: '))
30 binary_search(data, num)
注意列表排序操作的特性:
1 #!/usr/bin/env python
2 # -*- coding:utf-8 -*-
3 # Author: antcolonies
4
5 data = [1, 3, 5, 10, 50, 25, 60, 99, 72, 0, 4, 66]
6
7 print(data) # [1, 3, 5, 10, 50, 25, 60, 99, 72, 0, 4, 66]
8 print(id(data)) # 32507656
9 print(data[0]) # 1
10 print(id(data[0])) # 1727051440
11 print(data[data.index(0)]) # 0
12 print(id(data[data.index(0)])) # 1727051408
13 for i in range(len(data)):
14 print('data[%d] : %d' %(i, id(data[i])))
15
16 print('=======================')
17
18 DATA = data.sort()
19 print(DATA) # None
20 print(type(DATA)) # <class 'NoneType'>
21 print(id(DATA)) # 1726802688
22 print(data) # [0, 1, 3, 4, 5, 10, 25, 50, 60, 66, 72, 99]
23 print(id(data)) # 32507656
24 print(data[0]) # 0
25 print(id(data[0])) # 1727051408
26 for i in range(len(data)):
27 print('data[%d] : %d' % (i, id(data[i])))
28
29
30 '''
31 在list排序操作中可以得出以下结论:
32 1、没有返回值
33 2、排序改变的只是索引关系,数据对象并未改变
34 3、变量名data指向的是数据对象的地址
35 4、数据对象索引的地址并非第一个元素的地址
36 (与C语言中数组的结构不同,
37 数组名与数组的第一个元素变量的地址索引相同,
38 且数组元素的地址是连续的)
39 '''
40
41
42 '''
43 [1, 3, 5, 10, 50, 25, 60, 99, 72, 0, 4, 66]
44 32507656
45 1
46 1727051440
47 0
48 data[0] : 1727051440
49 data[1] : 1727051504
50 data[2] : 1727051568
51 data[3] : 1727051728
52 data[4] : 1727053008
53 data[5] : 1727052208
54 data[6] : 1727053328
55 data[7] : 1727054576
56 data[8] : 1727053712
57 data[9] : 1727051408
58 data[10] : 1727051536
59 data[11] : 1727053520
60 =======================
61 None
62 <class 'NoneType'>
63 1726802688
64 [0, 1, 3, 4, 5, 10, 25, 50, 60, 66, 72, 99]
65 32507656
66 0
67 data[0] : 1727051408
68 data[1] : 1727051440
69 data[2] : 1727051504
70 data[3] : 1727051536
71 data[4] : 1727051568
72 data[5] : 1727051728
73 data[6] : 1727052208
74 data[7] : 1727053008
75 data[8] : 1727053328
76 data[9] : 1727053520
77 data[10] : 1727053712
78 data[11] : 1727054576
79 '''
5. 匿名函数
匿名函数lambda 是一种快速定义单行的最小函数,可以用在任何需要函数的地方。
一般定义的函数:
def func(x,y):
return x*y
lambda函数定义:
r = lambda x,y:x*y
print r(2,3)
>>> f = lambda x: x*x
>>> f
<function <lambda> at 0x0000000003575488>
>>> f(5)
25
>>> list(map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9]))
[1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> res = map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> res
<map object at 0x000000000356E748>
>>> for i in res:
print(i)
1
4
9
16
25
36
49
64
81
>>>
6. 函数式编程
函数是Python内建支持的一种封装,我们通过把大段代码拆成函数,通过一层一层的函数调用,就可以把复杂任务分解成简单的任务,这种分解可以称之为面向过程的程序设计。函数就是面向过程的程序设计的基本单元。
函数式编程——Function Programming,虽也可归结于面向过程的程序设计,但其思想更接近数学计算。
计算机——CPU执行的是加减乘除指令,逻辑判断指令和跳转指令,因此汇编语言最接近计算机硬件的语言。
计算——数学意义上的计算,越是抽象的计算,离计算机硬件越远。
对应于编程语言,越低级的语言,越接近计算机语言,抽象程度越低,执行效率越高,比如C;
越高级的语言,越接近计算,抽象程度越高,执行效率越低,比如Lisp语言。
函数式编程是一种抽象程度很高的编程范式(programming paradigm),纯粹的函数式编程语言编写的函数没有变量,任意一个函数,只要输入参数确定,输出就唯一确定,这种纯函数我们称之为没有副作用。而允许使用变量的程序设计语言,由于函数内部的变量状态不定,同样的参数输入,可能得到不同的输出,这种函数具有副作用。
函数式编程的一个特点——允许把函数本身作为另一个函数的参数,并允许返回一个函数。
函数式编程中的函数这个术语不是指计算机中的函数(实际上是Subroutine),而是指数学中的函数,即自变量的映射。也就是说一个函数的值仅决定于函数参数的值,不依赖其他状态。比如sqrt(x)函数计算x的平方根,只要x不变,不论什么时候调用,调用几次,值都是不变的。
Python部分支持函数式编程。由于Python的函数中允许使用变量,因此,Python不是纯函数式编程语言。
一、定义
简单说,"函数式编程"是一种"编程范式"(programming paradigm),也就是如何编写程序的方法论。
主要思想是把运算过程尽量写成一系列嵌套的函数调用。举例来说,现在有这样一个数学表达式:
(1 + 2) * 3 - 4
传统的过程式编程,可能这样写:
var a = 1 + 2;
var b = a * 3;
var c = b - 4;
函数式编程要求使用函数,我们可以把运算过程定义为不同的函数,然后写成下面这样:
var result = subtract(multiply(add(1,2), 3), 4);
这段代码再演进以下,可以变成这样
add(1,2).multiply(3).subtract(4)
这基本就是自然语言的表达了。再看下面的代码,大家应该一眼就能明白它的意思吧:
merge([1,2],[3,4]).sort().search("2")
因此,函数式编程的代码更容易理解。
要想学好函数式编程,不要玩py,玩Erlang,Haskell。
7.高阶函数
函数即"变量",变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。
高阶函数的特性:
a. 把一个函数名当作实参传递给另一个函数(在不修改被装饰函数源代码的前提下为其添加新功能);
b. 返回值中包含函数名(不修改函数的调用方式)。
def add(x,y,f):
return f(x) + f(y)
res = add(3,-6,abs)
print(res)
8. 内置参数

内置参数详解 https://docs.python.org/3/library/functions.html?highlight=built#ascii
1 #compile 2 f = open("函数递归.py") 3 data =compile(f.read(),'','exec') 4 exec(data) 5 6 7 #print 8 msg = "又回到最初的起点" 9 f = open("tofile","w") 10 print(msg,"记忆中你青涩的脸",sep="|",end="",file=f) 11 12 13 # #slice 14 # a = range(20) 15 # pattern = slice(3,8,2) 16 # for i in a[pattern]: #等于a[3:8:2] 17 # print(i) 18 # 19 # 20 21 22 #memoryview 23 #usage: 24 #>>> memoryview(b'abcd') 25 #<memory at 0x104069648> 26 #在进行切片并赋值数据时,不需要重新copy原列表数据,可以直接映射原数据内存, 27 import time 28 for n in (100000, 200000, 300000, 400000): 29 data = b'x'*n 30 start = time.time() 31 b = data 32 while b: 33 b = b[1:] 34 print('bytes', n, time.time()-start) 35 36 for n in (100000, 200000, 300000, 400000): 37 data = b'x'*n 38 start = time.time() 39 b = memoryview(data) 40 while b: 41 b = b[1:] 42 print('memoryview', n, time.time()-start)
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 # Author: antcolonies 4 5 # print(all([-1, 5, 3])) 6 # print(any([1,0])) 7 8 # a = ascii([1,2,'这是中文']) 9 # print(type(a), [a]) # <class 'str'> ["[1, 2, '\u8fd9\u662f\u4e2d\u6587']"] 10 # print(repr(a)) # "[1, 2, '\u8fd9\u662f\u4e2d\u6587']" 11 12 # print(bin(123)) 0b1111011 13 # print(bin(255)) 0b11111111 14 # print(bin(8)) 0b1000 15 # oct() 16 # hex() 17 18 # a = bytes('abcde', encoding='utf-8') 19 # print(a.capitalize(), a) # b'Abcde' b'abcde' 20 21 # b = bytearray('abcde', encoding='utf-8') 22 # print( b[0] ) # 97 a的ascii码 23 # print(b[1]) # 98 24 # b[1] = 50 25 # print(b) # bytearray(b'a2cde') 26 27 # print(callable([])) # False 28 # def sayhi():pass 29 # print(callable(sayhi)) # True 30 31 # print(chr(98)) # b 32 # print(chr(123)) # { 33 # print(ord('b')) # 98 34 # print(ord('{')) # 123 35 36 ''' 37 >>> code = 'for i in range(10):print(i)' 38 >>> 39 >>> code 40 'for i in range(10):print(i)' 41 >>> compile(code, '', 'exec') 42 <code object <module> at 0x000000000347AF60, file "", line 1> 43 >>> c = compile(code, '', 'exec') 44 >>> exec(c) 45 0 46 1 47 2 48 3 49 4 50 5 51 6 52 7 53 8 54 9 55 >>> 56 >>> code = '1+3/2*6' 57 >>> code 58 '1+3/2*6' 59 >>> c = compile(code, '', 'eval') 60 >>> c 61 <code object <module> at 0x0000000003451AE0, file "", line 1> 62 >>> eval(c) 63 10.0 64 >>> eval(code) 65 10.0 66 >>> 67 ''' 68 69 70 # >>> a = {} 71 # >>> dir(a) 72 # ['__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'clear', 'copy', 'fromkeys', 'get', 'items', 'keys', 'pop', 'popitem', 'setdefault', 'update', 'values'] 73 # >>> 74 75 # >>> divmod(5,3) 76 # (1, 2) 77 # >>> divmod(100,7) 78 # (14, 2) 79 # >>> 80 81 # eval() 82 # exec() 83 84 # >>> 85 # >>> (lambda x: print(x + 1))(5) 86 # 6 87 # >>> calc = lambda n: 3 if n < 4 else n 88 # >>> calc(5) 89 # 5 90 # >>> 91 # >>> res = filter(lambda n: n > 5, range(10)) 92 # >>> for i in res: 93 # print(i) 94 # 95 # 6 96 # 7 97 # 8 98 # 9 99 # >>> 100 101 ''' 102 >>> res = map(lambda n:n>5,range(10)) 103 >>> for i in res: 104 print(i) 105 106 107 False 108 False 109 False 110 False 111 False 112 False 113 True 114 True 115 True 116 True 117 >>> res = map(lambda n:n*2,range(10)) 118 >>> for i in res: 119 print(i) 120 121 122 0 123 2 124 4 125 6 126 8 127 10 128 12 129 14 130 16 131 18 132 >>> res = [i*2 for i in range(10)] # res = [lambda i*2 for i in range(10)] 133 >>> for i in res: 134 print(i) 135 136 137 0 138 2 139 4 140 6 141 8 142 10 143 12 144 14 145 16 146 18 147 >>> 148 ''' 149 150 # import functools 151 # res = functools.reduce(lambda x,y:x+y,range(10)) 152 # print(res) # 45 153 # 154 # res = functools.reduce(lambda x,y:x*y,range(1,10)) 155 # print(res) # 362880 9! 156 157 # a = set([1,4,5,88,34,33,5,1]) 158 # print(a) # {1, 34, 33, 4, 5, 88} 159 # b = frozenset([1,4,5,88,34,33,5,1]) 160 # print(b) # frozenset({1, 34, 33, 4, 5, 88}) 161 162 # print(globals()) # 打印全局变量 163 164 # def test(): 165 # local_var = 333 166 # print(locals()) # {'local_var': 333} 167 # print(globals().get('local_var')) # None 168 # test() 169 # print(globals().get('local_var')) # None 170 171 # print(hash('alex')) # 8256347639460147595 172 # print(hash('alex')) # 8256347639460147595 173 # print(hash('Ted')) # 6081961024648288838 174 # print(hash('Ted')) # 6081961024648288838 175 176 # pow(2,8) 177 178 # print(round(1.2345)) # 1 179 # print(round(1.2345,2)) # 1.23 180 181 # d = range(20) 182 # print(d) # range(0, 20) 183 # print(d[slice(2,5)]) # range(2, 5) 184 # print(d[2:5]) # range(2, 5) 185 186 # a = {6:2,8:0,1:4,-5:6,99:11} 187 # print(a) 188 # print(sorted(a)) 189 # print(sorted(a.items())) 190 # print(sorted(a.items(), key=lambda x:x[1])) # 不懂 191 # print(a) 192 ''' 193 {8: 0, 1: 4, -5: 6, 6: 2, 99: 11} 194 [-5, 1, 6, 8, 99] 195 [(-5, 6), (1, 4), (6, 2), (8, 0), (99, 11)] 196 [(8, 0), (6, 2), (1, 4), (-5, 6), (99, 11)] 197 {8: 0, 1: 4, -5: 6, 6: 2, 99: 11} 198 ''' 199 200 # a = [1,2,3,4,5,6] 201 # b = ['a','b','c','d'] 202 # print(zip(a,b)) # <zip object at 0x0000000002213148> 203 # for i in zip(a,b): # map(a,b) 204 # print(i) 205 ''' 206 (1, 'a') 207 (2, 'b') 208 (3, 'c') 209 (4, 'd') 210 ''' 211 212 # import encode 213 # __import__('encode')
本节作业
有以下员工信息表
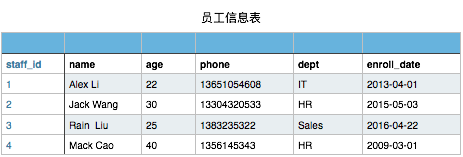
当然此表你在文件存储时可以这样表示
1,Alex Li,22,13651054608,IT,2013-04-01
现需要对这个员工信息文件,实现增删改查操作
- 可进行模糊查询,语法至少支持下面3种:
- select name,age from staff_table where age > 22
- select * from staff_table where dept = "IT"
- select * from staff_table where enroll_date like "2013"
- 查到的信息,打印后,最后面还要显示查到的条数
- 可创建新员工纪录,以phone做唯一键,staff_id需自增
- 可删除指定员工信息纪录,输入员工id,即可删除
- 可修改员工信息,语法如下:
- UPDATE staff_table SET dept="Market" WHERE where dept = "IT"
注意:以上需求,要充分使用函数,请尽你的最大限度来减少重复代码!
==================