要求0:
作业地址:【https://edu.cnblogs.com/campus/nenu/2016CS/homework/2110】
要求1:
https://git.coding.net/Antidotes/softwareFirstHomework.git git仓库地址:【https://git.coding.net/Antidotes/softwareFirstHomework.git】
https://git.coding.net/Antidotes/softwareFirstHomework.git
要求2:
1.
|
PSP阶段 |
所花时间百分比(807 / min) |
预计所花时间(350/min) |
|
|
计划 |
28 |
30 |
|
|
·明确需求和其他相关因素,估计每段时间成本 |
28 |
30 |
|
|
开发 |
751 |
360 |
|
|
·需求分析 |
20 |
20 |
|
|
·生成设计文档 |
30 |
30 |
|
|
·设计复审(和同学审核设计文档) |
20 |
10 |
|
|
·代码规范(为目前的开发制定合适的规范) |
30 |
20 |
|
|
·具体设计 |
功能一 |
25 |
10 |
|
功能二 |
36 |
10 |
|
|
功能三 |
30 |
10 |
|
|
·具体编码 |
功能一 |
60 |
30 |
|
功能二 |
120 |
50 |
|
|
功能三 |
120 |
60 |
|
|
·代码复审 |
50 |
30 |
|
|
·测试(自测、修改代码、提交修改) |
90 |
40 |
|
|
报告 |
60 |
30 |
|
|
·测试报告 |
30 |
5 |
|
|
·事后总结 |
30 |
25 |
|
2.分析预估耗时与实际耗时的差距原因:
1.自视甚高,想的过于简单,没有认真审题,没有考虑太多的细节。
2.对语言的不熟悉,换了三种语言才写出项目的半成品。
要求3:
1.解题思路:
看到作业的第一眼,我其实想用C语言写。因为觉得有点类似大一学算法做的ACM水题,用结构体排序就可以做到。而且“盲目自信”自己更为熟悉C语言。后来上手敲的时候发现并不是这样的,字符分割那里就出了一点问题,反复阅读题目之后觉得用面向过程语言过于繁琐。后来我尝试了PYTHON,还是在符号处理和排序除了问题,这里体现出我确实对PYTHON没有学到位…有点丢脸的贴上部分PYTHON代码。这不是我得意的地方,恰恰相反,这是我失败的地方,但想通过博客的方式来激励一下自己,提醒自己要继续钻研学习PYTHON。
1 import string 2 3 def processLine(line, wordCounts): 4 line = replacePunctuations(line) 5 words = line.split() 6 for word in words: 7 if word in wordCounts: 8 wordCounts[word] += 1 9 else: 10 wordCounts[word] = 1 11 12 13 def replacePunctuations(line): 14 line = line.replace(string.punctuation,' ') 15 return line 16 17 18 19 def main(): 20 infile = open("input.txt", 'r') 21 count = 10 22 words = [] 23 data = [] 24 25 # 建立用于计算词频的空字典 26 wordCounts = {} 27 for line in infile: 28 # 大写替换成小写,方便统计词频 29 processLine(line.lower(), wordCounts) 30 # 从字典中获取数据对 31 pairs = list(wordCounts.items()) 32 # 列表中的数据对交换位置,数据对排序 33 items = [[x, y] for (y, x) in pairs] 34 items.sort() 35 36 for i in range(len(items) - 1, len(items) - count - 1, -1): 37 print(items[i][1] + " " + str(items[i][0]) ) 38 data.append(items[i][0]) 39 words.append(items[i][1]) 40 41 infile.close() 42 43 44 if __name__ == '__main__': 45 main()
最后我选择了用JAVA语言来完成本次作业,因为利用java语言的map键值对,在排序要求上便于操作。但是在写代码的时候发现自己还是对面向对象这个概念理解的不到位,这次写作业很大程度上是为了完成任务,对于抽象出类的概念没有做好,而且也没有完成输入文件名的任务。也希望自己在今后的学习中能够更上一层楼。因为最近发现校园网不用翻就可以上谷歌,也算是开启了一扇新世界,本次资料搜索途径多通过谷歌。
通过分析题目,我觉得首先一点是关于题目中所定义单词的判断,这也是一个难点,所以我将其作为了一个单独的功能类。然后是字符的切割,我利用了正则表达式来区分文件中的符号并将单词分割出来,还有就是大小写问题。第一次做的时候忘掉了这点,看到结果以后才想起补充完全。最后就是按功能要求排序。
2.项目的重点难点:
①项目概要:使用JAVA语言完成的单词词频统计。
②项目模块:一个主类:wf(调用功能)
四个功能类:IsNum(判断是否是项目中定义的单词)
FunctionOne(实现功能一)
FunctionOne(实现功能二)
FunctionOne(实现功能三)
③实现过程:
IsNUM类:判断文件中的单词是否是项目中定义的单词
import java.util.regex.Matcher; import java.util.regex.Pattern; public class IsNum { public static boolean isNumeric(String word) { Pattern pattern = Pattern.compile("[a-zA-Z][a-zA-Z0-9]*$"); Matcher isNum = pattern.matcher(word); if(!isNum.matches()) { return false; } return true; } }
FunctionOne类:实现功能一,按文件单词出现顺序排序
package test; import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import test.IsNum; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStreamReader; import java.util.HashMap; import java.util.Iterator; import java.util.LinkedHashMap; import java.util.Map; import java.util.Scanner; import java.util.Set; public class FunctionOne { private static String lw; private static String file = ""; public static void funcOne(String path) throws IOException { FileInputStream inputStream = new FileInputStream(new File(path)); BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream)); while((lw = bufferedReader.readLine())!=null){ file += lw+" "; } Scanner scanner=new Scanner(file); //单词和数量映射表 Map<String, Integer> map = new LinkedHashMap<>(); while(scanner.hasNextLine()) { String line=scanner.nextLine(); line = line.toLowerCase(); String[] lineWords=line.split("\W+");//用非单词符来做分割 for(int i=0;i<lineWords.length;i++) { //单词是否合法 if (IsNum.isNumeric(lineWords[i])) { //如果已经有这个单词了, if(!("".equals(lineWords[i]))){ Iterator<String> iterator = map.keySet().iterator(); boolean exist = false; while(iterator.hasNext()){ String key = iterator.next(); if(key.equalsIgnoreCase(lineWords[i])) { exist = true; map.put(key, map.get(key) + 1); } } if (exist == false) { map.put(lineWords[i], 1); } } } } } System.out.println("Total words is "+map.size()); System.out.println("----------"); for(Map.Entry<String, Integer> entry : map.entrySet()) { System.out.printf("%-12s %d ",entry.getKey() ,entry.getValue()); } } }
其中,用到了下面的语句来将单词全部转换为小写。
line = line.toLowerCase();
用到了正则表达式来分割单词。
String[] lineWords=line.split("\W+");//用非单词符来做分割
功能一的实现结果如下(我没有实现输入文件名的功能,以后会多加改进):

FunctionTwo类:实现功能二,按照字典序排序
package test; import java.awt.List; import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStreamReader; import java.util.ArrayList; import java.util.Collection; import java.util.Collections; import java.util.Comparator; import java.util.HashMap; import java.util.Iterator; import java.util.LinkedHashMap; import java.util.Map; import java.util.Map.Entry; import java.util.Scanner; public class FunctionTwo { private static String lw; private static String file = ""; public static void funcTwo(String path) throws IOException { FileInputStream inputStream = new FileInputStream(new File(path)); BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream)); while((lw = bufferedReader.readLine())!=null){ file += lw+" "; } Scanner scanner=new Scanner(file); //单词和数量映射表 Map<String, Integer> map = new LinkedHashMap<>(); while(scanner.hasNextLine()) { String line=scanner.nextLine(); line = line.toLowerCase(); String[] lineWords=line.split("\W+");//用非单词符来做分割,分割出来的就是一个个单词 for(int i=0;i<lineWords.length;i++) { if (IsNum.isNumeric(lineWords[i])) { //如果已经有这个单词了, if(!("".equals(lineWords[i]))){ Iterator<String> iterator = map.keySet().iterator(); boolean exist = false; while(iterator.hasNext()){ String key = iterator.next(); if(key.equalsIgnoreCase(lineWords[i])) { exist = true; map.put(key, map.get(key) + 1); } } if (exist == false) { map.put(lineWords[i], 1); } } } } } System.out.println("Total words is "+map.size()); System.out.println("----------"); sortMap(map); } public static void sortMap(Map<String, Integer> oldMap){ ArrayList<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String,Integer>>(oldMap.entrySet()); Collections.sort(list,new Comparator<Map.Entry<String, Integer>>() { public int compare(Entry<String, Integer> o1,Entry<String,Integer> o2) { return o1.getKey().compareTo(o2.getKey()) ; } }); for(int i = 0; i<list.size(); i++){ System.out.printf("%-12s %d ",list.get(i).getKey(),+list.get(i).getValue()); } } }
其实功能二和功能一很多地方相类似,不过功能二使用了map键值对以及collecions来进行排序。
功能二运行结果如下:

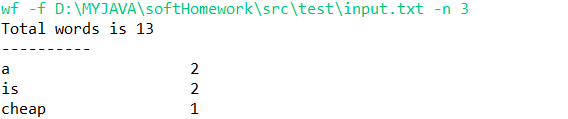
FunctionThree:实现功能三,按给定个数n输出前n个词频最高的单词,词频相同则按字典序输出
package test; import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStreamReader; import java.util.ArrayList; import java.util.Collection; import java.util.Collections; import java.util.Comparator; import java.util.HashMap; import java.util.Iterator; import java.util.LinkedHashMap; import java.util.Map; import java.util.Map.Entry; import java.util.Scanner; import java.util.TreeMap; public class FunctionThree { private static String lw; private static String file = ""; public void funcThree(String path,int n) throws IOException { FileInputStream inputStream = new FileInputStream(new File(path)); BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream)); while((lw = bufferedReader.readLine())!=null){ file += lw+" "; } Scanner scanner=new Scanner(file); //单词和数量映射表 Map<String, Integer> map = new TreeMap<String,Integer>(); while(scanner.hasNextLine()) { String line=scanner.nextLine(); line = line.toLowerCase(); String[] lineWords=line.split("\W+");//用非单词符来做分割,分割出来的就是一个个单词 for(int i=0;i<lineWords.length;i++) { if (IsNum.isNumeric(lineWords[i])) { //如果已经有这个单词了, if(!("".equals(lineWords[i]))){ Iterator<String> iterator = map.keySet().iterator(); boolean exist = false; while(iterator.hasNext()){ String key = iterator.next(); if(key.equalsIgnoreCase(lineWords[i])) { exist = true; map.put(key, map.get(key) + 1); } } if (exist == false) { map.put(lineWords[i], 1); } } } } } System.out.println("Total words is "+map.size()); System.out.println("----------"); sortValue(map,n); } public static void sortValue(Map<String, Integer> oldMap,int n){ ArrayList<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String,Integer>>(oldMap.entrySet()); Collections.sort(list,new Comparator<Map.Entry<String, Integer>>() { public int compare(Entry<String, Integer> o1,Entry<String,Integer> o2) { return o2.getValue().compareTo(o1.getValue()); } }); for(int i = 0; i < n; i++){ System.out.printf("%-12s %d ",list.get(i).getKey(),+list.get(i).getValue()); } } }
功能三运行结果如下:
总结来说,我觉得困难点在文件名的绝对路径和相对路径,我尝试了正则表达式“\”,可是未能解决。解决以后我会对项目加以更新完善。目前来看,十分惭愧。
3.个人感受
这次项目用时时间长,原因在于我本人对语言的不熟悉和自视甚高。回头重新看一下会发现CC++,JAVA,Python这三门语言都没有学精。在功能实现过程中欠火候,十分不成熟。在搜集资料的时候看到过中文分词的相关介绍,联想起之前做的机器人项目,在交互语义训练中也要去实现这个功能,但是当时只是从网上done下来一个代码套用了事,现在发现没有精读细学真的十分后悔。代码可以done,项目也可以done,别人脑袋里的东西如果不真正的去学习,却是怎么也done不下来的。深觉现在个人能力之欠缺与思想之浅薄,希望自己以后也能站到一个高度上,不断进步。
在做项目的过程中也产生了一点想法,现在市场上英语单词类APP非常多,英语但此类工具书也非常多,其中有关于词频的统计想来就是这个项目的应用。又联想起张邦佐老师在数据仓库一课中对于“《红楼梦》后四十回到底是谁写的?”这个引导问题,如果用调查词频的方式,找到作者惯用词汇,或者说在文言文中关于副词、语气词、宾语前置、定语后置等等的应用频率,是不是可以通过这样来鉴别作者呢?当然中华文化博大精深,人类也同样奇妙,不是通过小小的一方面就可以轻易得出结论的。但是如果可以,我希望以后自己能去研究一下这方面的内容,也算是为今天的后悔找了一颗后悔药。
联想到《构建之法》中对于团队的内容,以及上网浏览博客有时会看到“结对项目”这四个字,不禁产生一个想法是如果是团队合作我应该怎么去完成这个项目呢?软件工程说到底不是一个人的软件工程,是一个团队的软件工程。希望以后有机会可以尝试我的想法。
