1.环境配置
2.数据集获取
3.训练集获取
4.训练
5.调用测试训练结果
6.代码讲解
本文是第四篇,下载预训练模型并训练自己的数据集。
前面我们配置好了labelmap,下面我们开始下载训练好的模型。
http://download.tensorflow.org/models/object_detection/ssdlite_mobilenet_v2_coco_2018_05_09.tar.gz
下载下来解压,然后我们配置下pipeline文件
需要改动的地方有
num_classes:这个是我们的分类数,我们只有red和blue就填2
batch_size:这里我填的是2,batch_size过大,每次放入内存中训练的数据就会越多,如果你的内存不够大且数据量比较小,就填小点,我的是8G内存,图片也不过一两千张。
initial_learning_rate:学习速率,可以不修改。
fine_tune_checkpoint:输入我们下载的模型的ckpt文件的绝对路径
label_map_path:配置好的labelmap的绝对路径
tf_record_input_reader的input_path:填之前生成好的tfrecord文件的绝对路径
我的配置为以下文件:
model { ssd { num_classes: 2 image_resizer { fixed_shape_resizer { height: 300 300 } } feature_extractor { type: "ssd_mobilenet_v2" depth_multiplier: 1.0 min_depth: 16 conv_hyperparams { regularizer { l2_regularizer { weight: 3.99999989895e-05 } } initializer { truncated_normal_initializer { mean: 0.0 stddev: 0.0299999993294 } } activation: RELU_6 batch_norm { decay: 0.999700009823 center: true scale: true epsilon: 0.0010000000475 train: true } } use_depthwise: true } box_coder { faster_rcnn_box_coder { y_scale: 10.0 x_scale: 10.0 height_scale: 5.0 width_scale: 5.0 } } matcher { argmax_matcher { matched_threshold: 0.5 unmatched_threshold: 0.5 ignore_thresholds: false negatives_lower_than_unmatched: true force_match_for_each_row: true } } similarity_calculator { iou_similarity { } } box_predictor { convolutional_box_predictor { conv_hyperparams { regularizer { l2_regularizer { weight: 3.99999989895e-05 } } initializer { truncated_normal_initializer { mean: 0.0 stddev: 0.0299999993294 } } activation: RELU_6 batch_norm { decay: 0.999700009823 center: true scale: true epsilon: 0.0010000000475 train: true } } min_depth: 0 max_depth: 0 num_layers_before_predictor: 0 use_dropout: false dropout_keep_probability: 0.800000011921 kernel_size: 3 box_code_size: 4 apply_sigmoid_to_scores: false use_depthwise: true } } anchor_generator { ssd_anchor_generator { num_layers: 6 min_scale: 0.20000000298 max_scale: 0.949999988079 aspect_ratios: 1.0 aspect_ratios: 2.0 aspect_ratios: 0.5 aspect_ratios: 3.0 aspect_ratios: 0.333299994469 } } post_processing { batch_non_max_suppression { score_threshold: 0.300000011921 iou_threshold: 0.600000023842 max_detections_per_class: 100 max_total_detections: 100 } score_converter: SIGMOID } normalize_loss_by_num_matches: true loss { localization_loss { weighted_smooth_l1 { } } classification_loss { weighted_sigmoid { } } hard_example_miner { num_hard_examples: 3000 iou_threshold: 0.990000009537 loss_type: CLASSIFICATION max_negatives_per_positive: 3 min_negatives_per_image: 3 } classification_weight: 1.0 localization_weight: 1.0 } } } train_config { batch_size: 2 data_augmentation_options { random_horizontal_flip { } } data_augmentation_options { ssd_random_crop { } } optimizer { rms_prop_optimizer { learning_rate { exponential_decay_learning_rate { initial_learning_rate: 0.00400000018999 decay_steps: 800720 decay_factor: 0.949999988079 } } momentum_optimizer_value: 0.899999976158 decay: 0.899999976158 epsilon: 1.0 } } fine_tune_checkpoint: "/home/xueaoru/models/research/ssdlite_mobilenet_v2_coco_2018_05_09/model.ckpt" num_steps: 200000 fine_tune_checkpoint_type: "detection" } train_input_reader { label_map_path: "/home/xueaoru/models/research/car_label_map.pbtxt" tf_record_input_reader { input_path: "/home/xueaoru/models/research/train.record" } } eval_config { num_examples: 60 max_evals: 10 use_moving_averages: false } eval_input_reader { label_map_path: "/home/xueaoru/models/research/car_label_map.pbtxt" shuffle: true num_readers: 1 tf_record_input_reader { input_path: "/home/xueaoru/models/research/test.record" } }
在models/research目录下执行以下命令:
python object_detection/model_main.py --pipeline_config_path=/home/xueaoru/models/research/ssdlite_mobilenet_v2_coco_2018_05_09/pipeline.config --num_train_steps=200000 --sample_1_of_n_eval_examples=25 --alsologtostderr --model_dir=/home/xueaoru/models/research/car_data
其中pipeline_config_path为之前配置好的pipeline的绝对路径
num_train_steps为训练步数
sample_1_of_n_eval_examples为每多少个验证数据抽样一次
alsologtostderr输出std错误信息
model_dir输出训练过程中的数据的存放文件夹
执行完以上命令之后,基本上训练就开始了,我们只需要通过tensorboard来看看训练效果就可以了
tensorboard --logdir car_data
打开输出的地址:
就可以看到训练效果啦
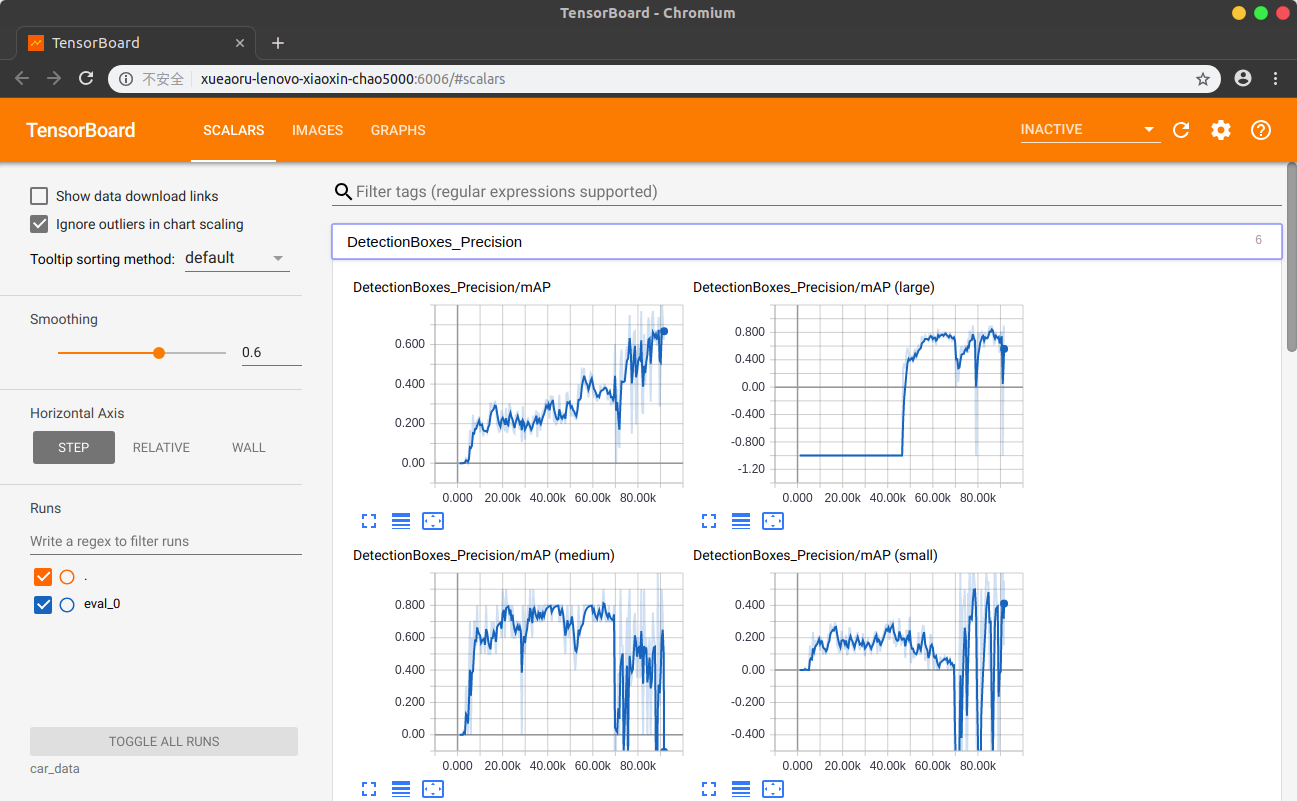
等到差不多收敛了,我们就可以输出我们的模型了
命令行输入以下命令:
python object_detection/export_inference_graph.py --input_type image_tensor --pipeline_config_path /home/xueaoru/models/research/ssdlite_mobilenet_v2_coco_2018_05_09/pipeline.config --trained_checkpoint_prefix /home/xueaoru/models/research/car_data/model.ckpt-87564 --output_directory /home/xueaoru/models/research/inference_graph_v2
配置基本上跟上面差不多,改改路径即可。
然后我们就在inference_graph_v2目录下拿到了训练后的模型了。