一、前期准备
查看最新文章更新:请点击这里
1、写脚本刷数据
[root@computer opt]# vi slap.sh #!/bin/bash HOSTNAME="localhost" PORT="3306" USERNAME="root" PASSWORD="" DBNAME="oldboy" TABLENAME="t1" ##create database mysql -h ${HOSTNAME} -P${PORT} -u${USERNAME} -p${PASSWORD} -e "drop database if exists ${DBNAME}" create_db_sql="create database if not exists ${DBNAME}" mysql -h ${HOSTNAME} -P${PORT} -u${USERNAME} -p${PASSWORD} -e "${create_db_sql}" #create table create_table_sql="create table if not exists ${TABLENAME}(stuid int not null primary key,stuname varchar(20)
not null,stusex char(1) not null,cardid varchar(20) not null,birthday datetime,entertime datetime,address varchar(100) default null)" mysql -h ${HOSTNAME} -P${PORT} -u${USERNAME} -p${PASSWORD} ${DBNAME} -e"${create_table_sql}" #insert data to table i="1" while [ $i -le 500000 ] do insert_sql="insert into ${TABLENAME} values($i,'alexsb_$i','1','110011198809163418','1990-05-16','2017-09-13','oldboyedu')" mysql -h ${HOSTNAME} -P${PORT} -u${USERNAME} -p${PASSWORD} ${DBNAME} -e "${insert_sql}" let i++ done #select data select_sql="select count(*) from ${TABLENAME}" mysql -h ${HOSTNAME} -P${PORT} -u${USERNAME} -p${PASSWORD} ${DBNAME} -e "${select_sql}"
2、执行脚本,验证数据
[root@computer opt]# sh slap.sh

二、索引介绍
1、索引分类
Btree
HASH
Rtree
Fulltext
2、Btree结构分类
B -tree

B+tree
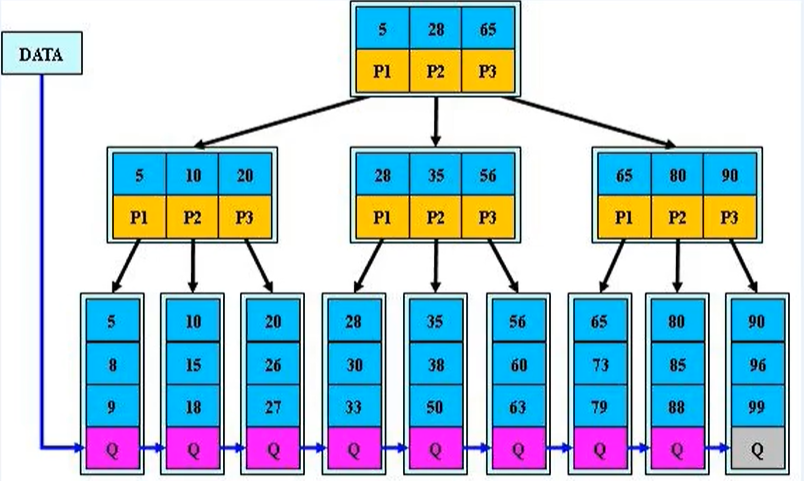
B*tree
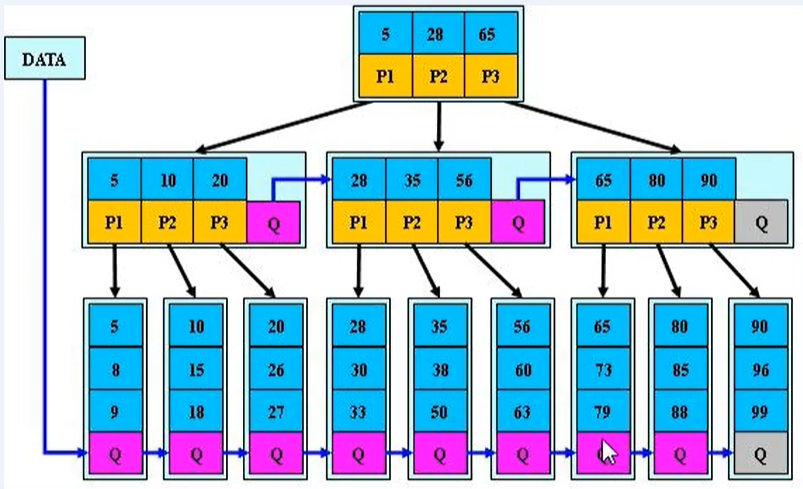
3、Mysql Btree种类细分
普通二级索引(辅助索引):人为操作最多

聚集索引(cluster index): 主键索引,建表时创建

唯一索引(unique index):人为操作

4、索引的高度

三、索引的基本管理
1、压力测试,用mysql自带的压力测试工具,试一下没有索引的情况下,差不多跑了四个小时还没跑完
mysqlslap --defaults-file=/etc/my.cnf > --concurrency=100 --iterations=1 --create-schema='oldboy' > --query="select * from oldboy.t1 where stuname='alexsb_100'" engine=innodb > --number-of-queries=200000 -uroot -p123456 -verbose
2、辅助索引管理
1)单列普通辅助索引
创建索引
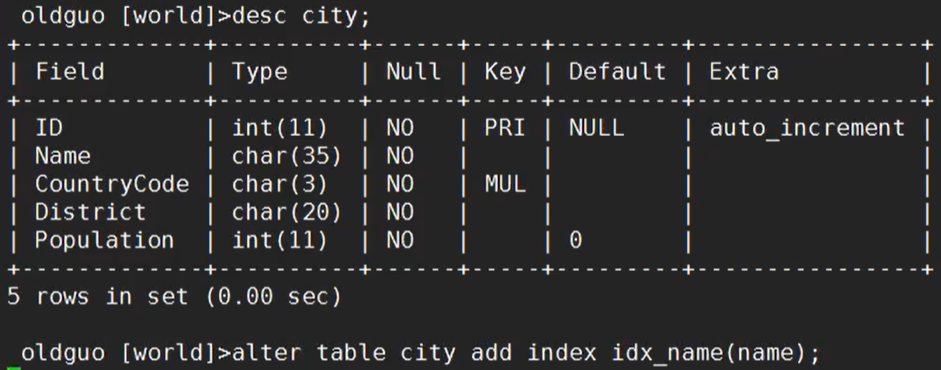
查看索引

命令:
alter table city add index idx_name(name); 创建索引
create index idx_name on city(name); 创建索引
alter table city drop index idx_name; 删除索引
desc city; 查询索引
show index from city; 查询索引
2)覆盖索引(联合索引)
创建索引

查看索引
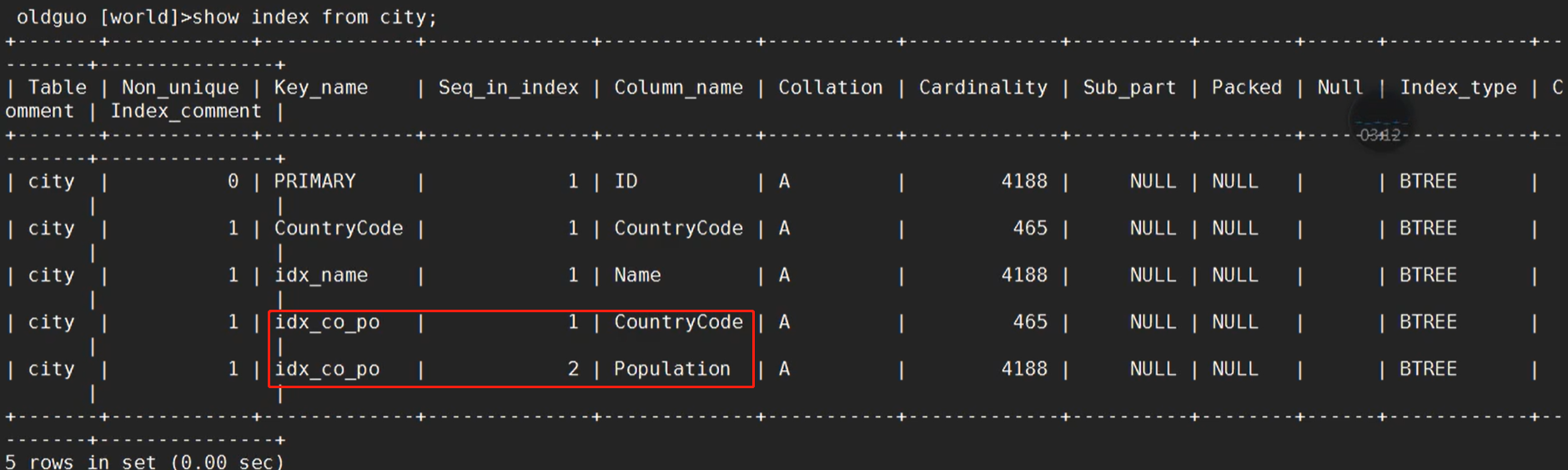
删除索引

3)前缀索引
创建索引

查看索引

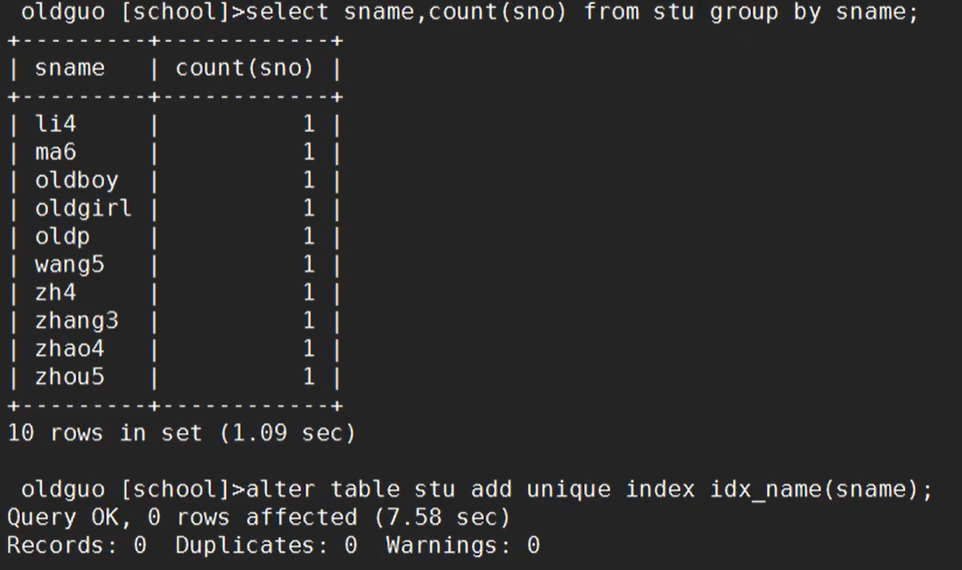
4)唯一索引
创建索引,建之前,确认一下,这一列没有重复值
四、执行计划
1、查看执行的语句

关注信息:

2、type类型



生产优化的目标:保证在RANGE以上。
3、其他字段的解释
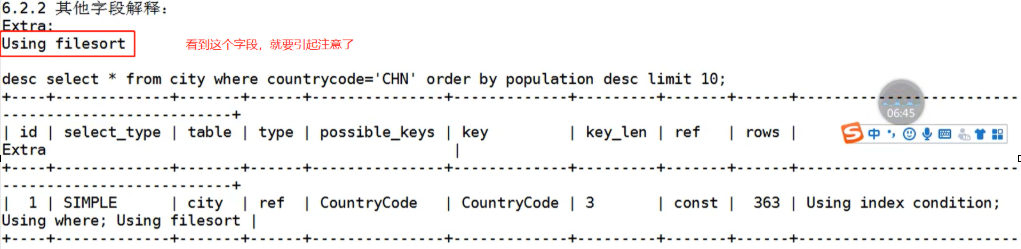
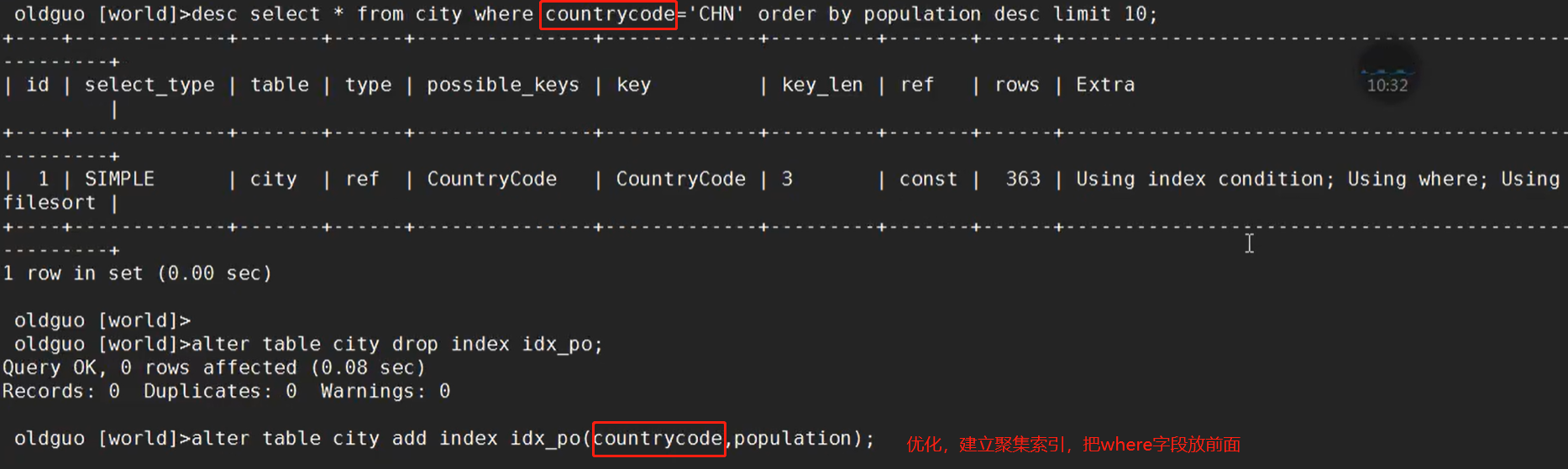
优化:


五、面试题
题目意思:我们公司业务慢,请你从数据库的角度分析原因
1,mysql出现性能问题,我总结有两种情况:
1)应急性的慢!突然夯住
应急情况:数据库hang(卡了,资源耗尽)
处理过程:
(1)show processlist; 获取到导致数据库hang的语句
(2)Explain分析SQL的执行计划,有没有走索引,索引的类型情况
(3)建索引,改语句
2)一段时间慢:
(1)记录忄曼日,分析slowlog
(2)explain分析SQL的执行计划,有没有走索引,索引的类型情况
(3)建索引,改语句


六、索引优化刚才压力测试的语句
1、查看查询情况,走的全表扫描

2、创建索引

3、执行结果对比,显而易见。

七、索引建立原则
1、建表时一定要有主键,如果相关列不可以作为主,做一个无关列
2、选择唯一性素引
唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录。
例如,学生表中学号是具有唯一性的字段。为该字段建立唯一性索引可很快的确定某个学生的信息
如果使用姓名的话,可能存在同名现象,从而降低查询速度。
主键索引和唯一键索引,在查询中使用是效率最高的。
select count(*) from world.city: select count(distinct countrycode)from world.city; select count(distinct countrycode,population) from world.city;
注意:如果重复值较多,可以考虑采用联合索引
3、为经常需要where、ORDERBY、GROUPBY,jo№on等操作的字段,排序操作会浪费很多时间。
如果为其建立索引,可以有效地避免排序操作。
4、为常作为ere查询条件的字段建立索引
如果某个字段经常用来做查询条件,那么该字段的查询速度会影响整个表的查询速度。
为这样的字段建立索引,可以提高整个表的查询速度。
4.1经常查询
4.2列值的重复值少(业务层面调整)
注:如果经常作为条件的列,重复值特别多,可以建立联合索引
5、尽量使用前缀来素引
如果索引字段的值很长,最好使用值的前缀来索引。
---以上的是重点关注的,以下是能保证则保证的----
6、限制索引的数目
素引的数目不是越多越好。每个素引都需要占用磁盘空间,素引越多,需要的磁盘空间就越大。
修改表时,对索引的重构和更新很麻烦。越多的索引,会使更新表变得很浪费时间。
7、删除不再使用或者很少硬的素引(percona tootkit)
表中的数据被大量更新,或者数据的使用方式被改变后,原有的一些索引可能不再需要。数据库管理
员应当定期找出这些索引,将它们删除,从而减少索引对更新操作的影响。
8、大表加索引,要在业务不繁忙期间操作
9、少在经常更新值的列上建索引
建索引原则:
(1)必须要有主键,如果没有可以做为主键条件的列,创建无关列
(2)经常做为where条件列 order by group by join on的条件(业务:产品功能+用户行为)
(3)最好使用唯一值多的列作为索引,如果索引列重复值较多,可以考虑使用联合索引
(4)列值长度较长的索引列,我们建议使用前缀索引,
(5)降低索引条目,一方面不要创建没用索引,不常使用的索引清理,perconatoolkit
(6)索引维护要避开业务繁忙期
八、不走索引的情况
1、不走索引的情况(开发规范)
重点关注:
(1)没有查询条件,或者查询条件没有建立索引
select * from tab;全表扫描: select * from tab where1=1;
在业务数据库中,特别是数据量比较大的表:
是没有全表扫描这种需求。
(2)对用户查看是非常痛苦的:
(3)《对服务器来讲毁灭性的0
(4)select*fromtab,
SQL改写成以下语句:
select * from tab order by price limit 10 需要在price列上建立索引 setect * from tab where name='zhangsan' name列没有索引

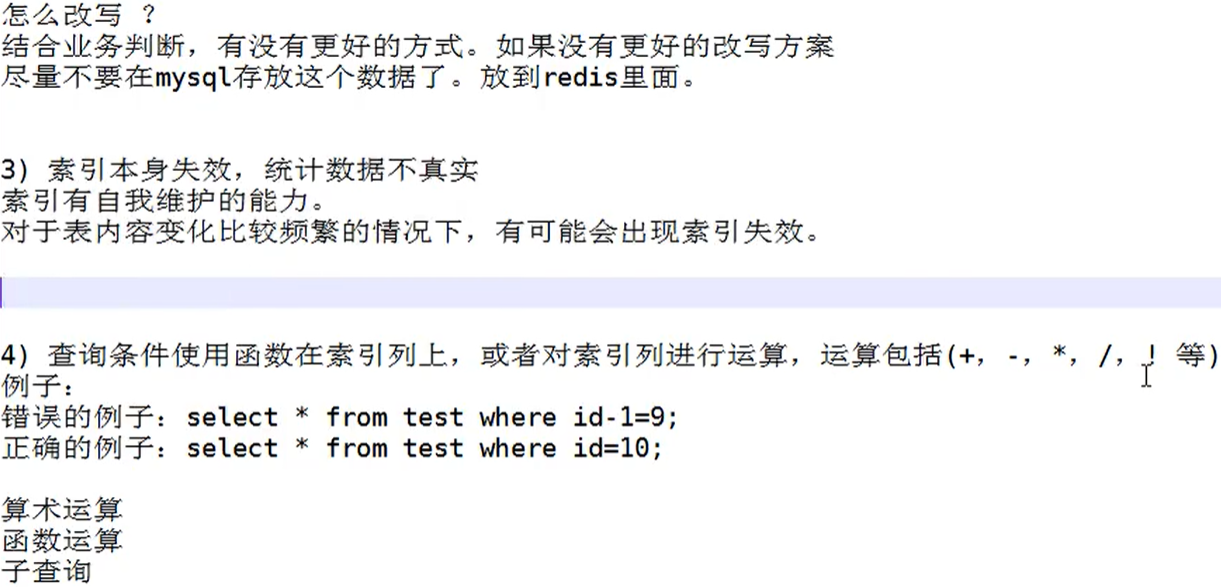

函数例子:




