首先,"multipart/form-data" 编码格式的数据是不能用 querystring 或者 body-parser 来解析的,需要借助 formidable 或者其他的模块来解析。再学习这些第三方模块时我就在想,它们是怎么实现解析数据的呢?
如果是 "application/x-www-form-urlencoded" 格式的数据很好解决,请求体中的数据都是以 ”&“ 作为连接,特殊字符转换为ASCII HEX值,比如参数值中的 "&" 编码成 "%26" ,空格用 ”+“ 表示,但是 "multipart/form-data" 数据就有些麻烦了,因为它的请求体是这样的:

这里我将请求体 Buffer 类型的数据转换成了 utf-8 格式的字符串,数据以 boundary 作为分隔,文件以二进制数据传输,为了解析这段数据,声明函数 "function formParse( )" ,函数需要传入两个参数,请求体中的 data,和请求头中的 boundary 。代码如下:
module.exports = function formParse(body, boundary) {
//将Buffer类型的数据转化成binary编码格式的字符串
let formStr = Buffer.concat(body).toString('binary');
let formarr = formStr.split(boundary);
//去掉首尾两端的无用字符
formarr.shift();
formarr.pop();
//存储普通key-value
let filed = {};
//存储文件信息
let file = {};
for (let item of formarr) {
//去除首尾两端的非信息字符
item = item.slice(0, -2).trim();
//value存储input输入的值
let value = '';
//不同操作系统换行符不同,用变量a声明特殊分割点位的下标
let a;
if ((a = item.indexOf('
')) != -1) {
value = item.slice(a + 4);
} else if ((a = item.indexOf('
')) != -1) {
value = item.slice(a + 2);
} else if ((a = item.indexOf('
')) != -1) {
value = item.slice(a + 2);
}
//正则匹配,组中内容
let key = item.match(/name="([^"]+)"/)[1];
if (item.indexOf('filename') == -1) {
if (!(key in filed)) {
//将二进制字符串转化成utf8格式的字符串
filed[key] = Buffer.from(value,'binary').toString('utf8');
} else {
//将复选框的数据放入一个数组中
let arr = [];
filed[key] = arr.concat(filed[key], value);
}
} else {
let filename_b = item.match(/filename="([^"]*)"/)[1];
//解决中文文件名乱码的问题
let filename = Buffer.from(filename_b,'binary').toString();
let contentType = item.slice(item.indexOf('Content-Type:'), a);
let obj = {};
obj.filename = filename;
obj.contentType = contentType;
obj.binaryStream = value;//文件的二进制数据
let arr = [];
if (!(key in file)) {
arr.push(obj);
file[key] = arr;
} else {
//用于多文件上传
file[key] = arr.concat(file[key], obj);
}
}
}
return { filed, file };
}
然后,再使用这个函数,
const http = require('http');
const path = require('path');
const fs = require('fs');
const { promisify } = require('util');
const formParse = require('./formParse');
const server = http.createServer();
const readFile = promisify(fs.readFile);
const writeFile = promisify(fs.writeFile);
server.on('request', async (req, res) => {
if (req.url == '/ajax') {
if (req.method == 'GET') {
let pathName = path.join(__dirname, 'ajax.html');
let data = await readFile(pathName, 'utf8');
res.end(data);
}
if (req.method == 'POST') {
// req.setEncoding('binary');
let body = [];
let boundary = req.headers['content-type'].split('boundary=')[1];
//console.log(boundary);
req.on('data', (chunk) => {
body.push(chunk);
}).on('end', async () => {
let { filed, file } = formParse(body, boundary);
console.log(filed);
console.log(file);
try {
//文件输入框的name="files"
let fileArr = file.files;
for(let f of fileArr){
await writeFile(f.filename, f.binaryStream, 'binary');
console.log(`文件"${f.filename}"写入成功`);
}
} catch (error) {
console.log(error);
res.statusCode = 500;
res.end();
}
res.end('请求成功');
})
}
} else {
res.end('not found');
}
});
server.listen(8080);
console.log('服务器启动成功');
关于函数 formParse 的几点说明:
- formParse 将非文件的参数存入再 "field" 对象中,文件参数存在 "file" 对象中,文件以二进制字符串的形式存在,这样的话,文件存在哪,以什么名字或者格式存储,你可以自己设置。在命令行窗口打印 filed 和 file 对象,格式如下:
{ username: '张三', password: '123', book: [ 'book1', 'book2' ] }
{
files: [
{
filename: '测试文档.txt',
contentType: 'Content-Type: text/plain',
binaryStream: 'test text --En
ä¸æå符串 --zh-cn'
}
]
}
-
文件在写入时,需要设置编码格式为 "binary" ,因为 binaryStream 中存的是二进制的字符串。
-
在函数中,我是先这样处理 Buffer 类型的数据的:
let formStr = Buffer.concat(body).toString('binary');这样的话,会造成中文的字符串乱码,所以文件名,参数值在后面都要转换成 utf8 格式,当然,这个在函数内部实现了。
-
如果先将 Buffer 类型的数据转换成 utf8 格式的字符串,再将文件转换回 binary 编码,纯文本文件没什么问题,但是图片文件就会读不出来,具体原因不知道,可能这种 转换不可逆吧
-
我在一些博客上看见这样的处理方式:在读取请求体数据之前,设置
req.setEncoding('binary');因为我对 node 还不是很了解,到 node.js 官网去查了,了解到这里的 req 是回调函数中的参数,是一个 IncomingMessage 对象,它继承了 stream.Readable 类,所以设置读取时的数据编码为 binary。

-
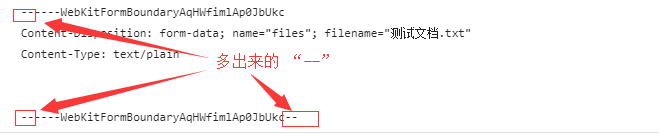
还有一个小细节,分隔数据的字符串是 "--"+boundary,结尾也会有两个”-“:
关于 formParse 的代码 https://github.com/Arduka/ajax-formParser