在master上执行hadoop namenode -format 后,
当执行start-dfs.sh时,jps一下,发现datanode没有启动。
原因:
查看master.log日志
【root@master logs]# cat hadoop-root-datanode-master.log

发现异常是namenode的clusterID 与datanode的clusterID不一致,是因为自己格式化两次namenode,每次格式化时,namenode会更新clusterID,但是datanode只会在首次格式化时确定,因此就造成不一致现象。
所以要把namenode 和datanode的 clusterID修改一致就好了。
使用find / -name VERSION找到VERSIONl所在路径。

vim /tmp/hadoop-root/dfs/name/current/VERSION 查看namenode的clusterID
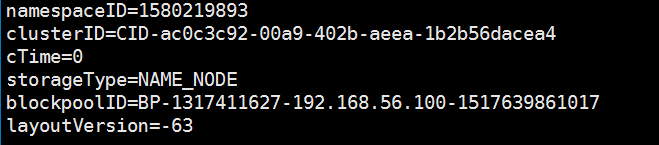
vim /tmp/hadoop-root/dfs/data/current/VERSION 查看datanode的cluterID
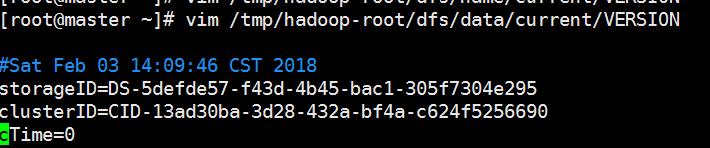
可以发现两者的cluterID的不一致,在master中把namenode的cluterID改的和datanodeID一致就可以了.
注意:在slave机器中也有CluseterID,不要把master中把dataenode的cluterID改的和namenodeID一致,这样子master和slave中的clusterID会不一致。要把
master中的
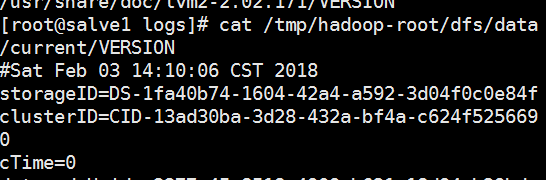
start-dfs.sh 发现namenode和datanode启动成功。