“条件”的作用:一种新的科学知识图表示与构建模型
Abstract
条件关系在科学观测、假设和陈述中起着重要作用,但是现有的科学知识图谱(SicKgs)与一般领域的知识图谱(KGs)一样,没有考虑事实有效的条件,仅将事实知识表示为一个平面的概念关系网络,从而丧失了推理和探索的重要上下文。
In this work, we propose a novel representation of SciKG, which has three layers. The first layer has concept nodes, attribute nodes, as well as the attaching links from attribute to concept. The second layer represents both fact tuples and condition tuples. Each tuple is a node of the relation name, connecting to the subject and object that are concept or attribute nodes in the first layer. The third layer has nodes of statement sentences traceable to the original paper and authors. Each statement node connects to a set of fact tuples and/or condition tuples in the second layer.
论文提出了一种新的SicKG表示,共有三层。第一层有概念节点、属性节点以及从属性到概念的附加连接。第二层表示事实元组和条件元组。每个元组都是关系名称的节点,连接到第一层的概念和或属性节点主语和宾语。第三层为语句节点,可溯源到原文和作者。每个语句节点连接到第二层的一组事实或条件元组。
We design a semi-supervised Multi-Input Multi-Output sequence labeling model that learns complex dependencies between the sequence tags from multiple signals and generates output sequences for fact and condition tuples. It has a self-training module of multiple strategies to leverage the massive scientific data for better performance when manual annotation is limited.
设计了一个半监督的多输入多输出的序列标记模型,该模型从多个信号中学习序列标记之间的复杂依赖关系,并生成事实元组和条件元组的输出序列。该模型有一个多种策略的自我训练模块,可以在人工注释有限的情况下,利用大量的科学数据来获得更好的性能。
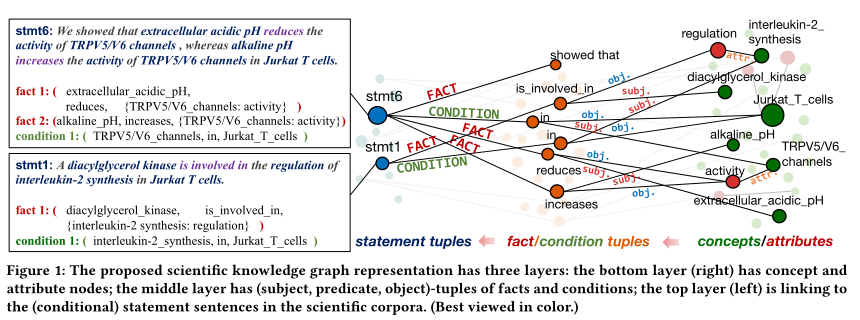
stmt6: 发现T细胞中细胞外酸性PH降低通道活性,而碱性PH增加通道活性。
stmt1:一种酶参加调节T细胞中一种化合物的合成
Introduction
由于搜索引擎无法满足科学家对文献的搜索需求,构建 SciKGs 的想法引起了人们的关注。KG构建模型从语料库中提取(实体,关系,实体)的三元组,并将其转换为用于推理的连接。
“During T lymphocyte activation as well as production of cytokines, ... ”
“在T淋巴细胞激活和产生细胞因子的过程中,……”
现有的SciKGs从文本构造时忽略了条件,例如上句,构建模型专注于主句,而忽略了描述具体、重要条件的从句。因此一个好的SicKGs不仅应该有实体元组,还应该有条件元组。
“We observed that ... alkaline pH increases the activity of TRPV5/V6 channels in Jurkat T cells. ”
现有的信息抽取会提取出 (alkaline pH, increases, activity of TRPV5/V6 channels in Jurkat T cells) 三元组作为SicKG中的事实知识单位。但这并不让人满意,因为:
- 缺少TRPV5/V6 channels 的属性 activity
- 条件 TRPV5/V6 channels in Jurkat T cells 没有从文本中结构化体现
为了尽可能保留句子中的信息,每个语句都用格式化的 {concept: attribute} (属性可以为空)一组实体元组表示。对于条件元组,如果主语描述的是观测的均值或环境,而不是实体中某些概念/属性的特定设置,则主语可以为空;对象可以是元组中的具体值,例如 (temperature, is, 63) 、(pH, is, 3.4)。按照这种规则,我们从上个例子中期望提取出
论文为任务构建了一个标签模式:
- Definition 1 (Tag Schema
):对于一个句子,每个 token 会被分配一个 tag ,来表示它在元组中的角色。non-“O(outside)” 标签被格式化为“B/I-XYZ”,其中

- Definition 2 (Fact Tuple and Condition Tuple): 一个(subject, relation, object)元组用来描述主语和宾语之间的关系。
- Definition 3 (Structured Statement):一个科学陈述句(例如,观察,假设)是由事实元组和/或条件元组组成的,它们形成语义依赖,只有当条件存在时,事实才是有效的(由源声明)。
有三个问题:
- 一个 token 在不同的元组中可能有不同的标记,就比如 “TRPV5/V6” 这个词被标记为: (1) 事实元组中的宾语; (2)条件元组中的主语;
- 注释是代价是昂贵的,在科学领域,专家手工注释科学文献需要很长时间;
- 序列标签在转换为元组结构时存在噪声,缺少训练示例,学习模型难确保序列标签正确定位到复合元组单元,因此降噪很重要;
为了解决这些问题,首先该模型采用多任务方案,同时为事实元组和条件元组生成标记序列,这些子任务共享相同的编码-解码器,但是使用不同的线性softmax层预测。
其次,由于注释有限,只能多寻求有效特征。而语言模型LM,词性标注POS、概念检测、属性提取、短语挖掘CAP等基础NLP任务效率高,将其和原始句子一起作为输入序列,这些信息互补来学习标签间复杂的依赖关系。
最后模型具有迭代的自训练模块,每次迭代训练和预测时,都将高置信的预测标签添加到训练集中,对模型进行重新训练,以修正常见错误。
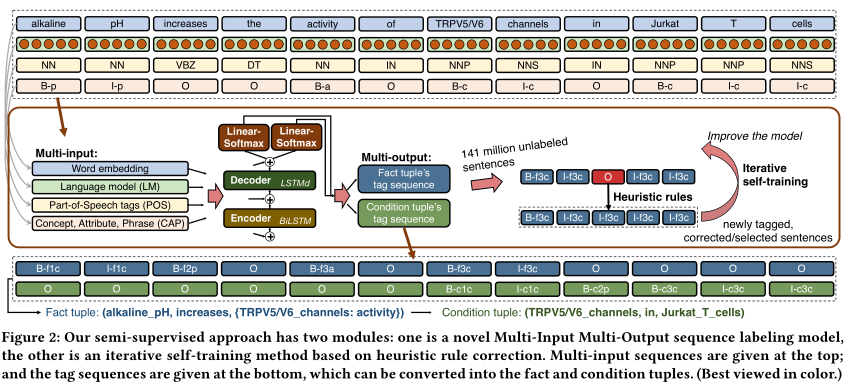
多输入模型:由多个基本NLP任务的结果提供。
WE: 通过聚合的全局词-词共现统计量的训练,将 token 的语义编码为分布式表示
LM:采用 Transformers(BERT)
POS: 为每个token分配一个label来指示语法类别
CAP:各种分配label
编码解码模型采用双向LSTM。
多输出模型:事实标记和条件标记使用相同的编码器-解码器模型,在共享上下文中相互增强。他们使用不同的线性-softmax层来分别预测事实和条件的具体标签。
采用迭代自训练半监督学习方案,对于每次迭代,通过在未标记的句子上添加预测标签来扩展训练集。由于新标记的句子上的噪声,自训练容易产生错误传播。为了修正这些错误,采用如下方法:
- 基于关联规则的校正(AR):使用关联规则挖掘从训练集中获得高支持度和置信度的规则。如图4 (a);
- 标签一致性校正(TC)和删除(TCDEL),如图4(b);
- 尽可能选择短句,因为短句比长句有更好的训练结果;
- 删除不完整的序列,因为可能会错过信息;

Experiments
Daraset: MEDLINE (一个生命科学和生物医学文献数据库) 的1550万篇文章的摘要, 领域内专家在31个随机文档中人工注释事实和条件标签。
与现有的方法比较 ALLENNLP OpenIE(有监督的提取命题列表模型,每个命题由谓词和参数组成)、Stanford OpenIE(切分句子)、Structured SVM(可处理数百万单词特征的注释问题)、CRF(条件随机场)。
为了验证多输入的效果,也进行了验证。

最终效果:
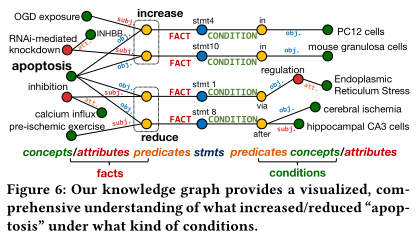
提供了一个带条件的知识图谱