从历史到未来的原因:时间知识图的两阶段推理
Abstract
Temporal Knowledge Graphs (TKGs) have been developed and used in many different areas. Reasoning on TKGs that predicts potential facts (events) in the future brings great challenges to existing models. When facing a prediction task, human beings usually search useful historical information (i.e., clues) in their memories and then reason for future
meticulously. Inspired by this mechanism, we propose CluSTeR to predict future facts in a two-stage manner, Clue Searching and Temporal Reasoning, accordingly. Specifically, at the clue searching stage, CluSTeR learns a beam search policy via reinforcement learning (RL) to induce multiple clues from historical facts. At the temporal reasoning stage, it
adopts a graph convolution network based sequence method to deduce answers from clues. Experiments on four datasets demonstrate the substantial advantages of CluSTeR compared with the state-of-the-art methods. Moreover, the clues found by CluSTeR further provide interpretability for the results.
时间知识图谱 TKGs 已经发展并应用到了许多领域,基于预测未来潜在事件的 EKGs 的推理给现有的模型带来了极大挑战。在面对预测任务时,人类通常会在记忆中搜索有用的历史信息(即线索),来仔细思考未来。在此机制的启发下,提出了基于线索搜索和时间推理两阶段的聚类预测方法CluSTeR。具体来说,在线索搜索阶段,通过强化学习RL学习波束搜索策略,从历史事实中归纳出多个线索。在时序推理阶段,采用基于图卷积网络的序列方法,从线索推出答案。此外CluSTeR发现的线索进一步提供了结果的可解释性。
Introduction
TKGs 中的每个事实都有一个时间戳,来指示其发生的时间。例如 ( COVID-19, New medical case occur, Shop, 2020-10-2 ), 表示2020-10-2在某商店发生了新病例。给定一个历史事实,如何回答问题( COVID-19, New medical case occur, ?, 2020-10-2 ) ?如图1,
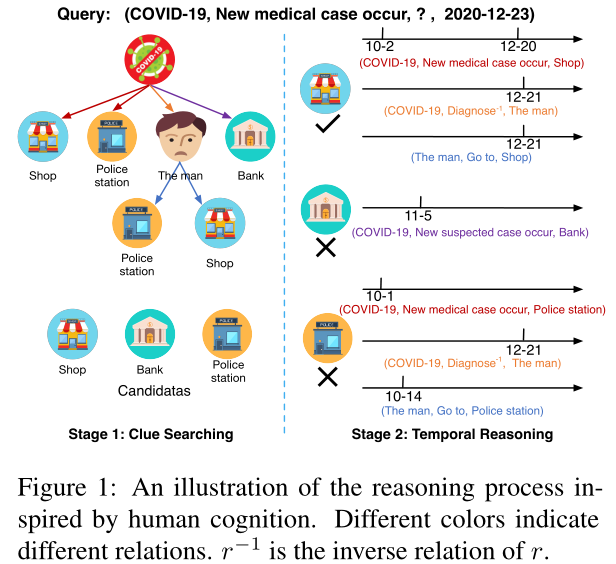
根据 dual process theory 双过程理论,人类预测未来的事件首先是搜索大容量的记忆,直观地找到一些相关的历史信息(即线索),如图1左侧所示,查询主要有三类重要线索:
- 与查询具有相同关系的 1 跳路径,称为重复单跳路径,例如 ( COVID-19, New medical case occur, Shop )
- 与查询关系不同的 1 跳路径,称为非重复单跳路径,例如 ( COVID-19, New suspectedcase occur, Bank )
- 2 跳路径,例如 ( COVID-19, Diagnose -1 , The man, Go to,Police station )
人类会从自己的记忆中回忆这些线索,并得出一些直观的备选答案。其次,人类通过更深入地挖掘时间信息线索和进行一个细致推理过程来得到准确的答案。如图 1 右侧所示,这个人在确诊前两个月去的警局,这明显不可能是正确答案,最终得出结论 Shop
现有模型主要关注上诉第二个过程,而低估了第一个过程,最近的一些研究,在考虑所有的历史事实的情况下,学习实体的演进嵌入。然而,只有少数的历史事实对特定的预测是有用的。因此还有别的研究主要是对历史中 1 跳重复路径(重复事实)进行编码。以广泛使用的数据集ICEWS18为例,41.2%的训练查询可以通过历史上的 1 跳重复路径得到答案,64.6%的人通过 1 跳重复和非重复路径得到答案,86.2% 的人通过 1 跳和 2 跳路径得到答案。
因此提出一个新的模型CluSTeR,包括两个阶段,线索搜索(阶段1)和时间推理(阶段2)。在阶段 1 中,CluSTeR 将线索搜索形成转换为一个马尔科夫决策过程 MDP,并用了一种束搜索策略来解决。在阶段 2 ,CluSTeR 将阶段 1 中发现的线索重新组织成一系列图,然后使用图卷积网络GCN和门控循环单元GRU从图中推导出准确答案。
CluSTeR Model
1.Notations
- TKG
 是实体之间具有时间标记边的多关系有向图
是实体之间具有时间标记边的多关系有向图 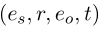 是一个 fact in , 本文是预测实体 es 或者是 e0
是一个 fact in , 本文是预测实体 es 或者是 e0 是一条线索路径,
是一条线索路径,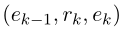 代表线索中的一跳
代表线索中的一跳
2.Model Overview
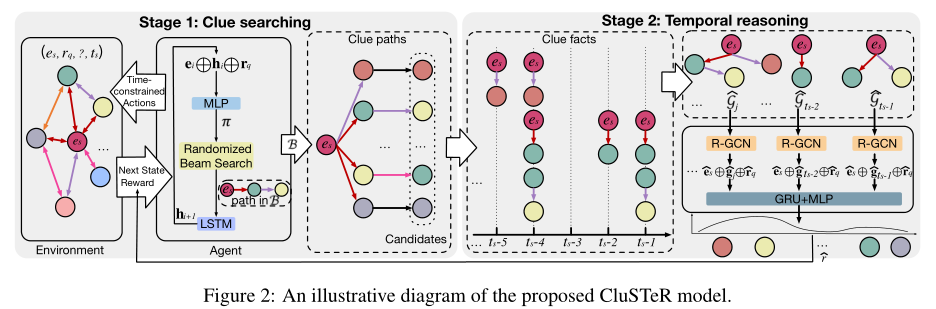
受人类认知启发,这俩阶段分别对应快思考(直觉)和慢思考(推理)。
3.Stage 1: Clue Searching
阶段 1 的目标是搜索和归纳出于给定查询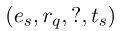 相关的线索路径,可以看成是一个顺序决策问题,并由RL系统解决。
相关的线索路径,可以看成是一个顺序决策问题,并由RL系统解决。
3.1 RL System
RL 系统由 agent 和 environment 组成,本文将 RL 系统构建为一个 MDP,这是一个从 agent 和 environment 之间的交互学习中学习以找到有希望的线索路径框架。从 es 开始,agent通过随机 beam search 依次选择出边,并遍历新的实体直到达到最大步长 I 。MDP 由下面这些部分组成:
- 状态

,
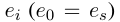 是 agent 遍历到第 i 步的实体,
是 agent 遍历到第 i 步的实体,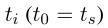 是上一步所采取措施的时间戳,
是上一步所采取措施的时间戳,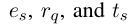 在同一查询的所有状态里是共享的。
在同一查询的所有状态里是共享的。 - 与静态的KG相比,加入了时间这一维度会导致一个大的行动空间,此外,人类的记忆主要集中在最近发生的事件上,因此设置 | ti - ts | ≤ m,前一个动作的时间戳与每个可用动作之间的时间间隔不超过

,| t‘ - ti | <
。因此可能的动作集合
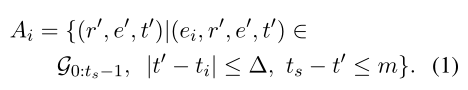
- agent 在搜索结束时会得到一个reward,如果目标实体是正确的目标实体,则 reward = 1,否则为 0.
3.2 Semantic Policy Network
考虑到时间信息建模,论文设计了一个语义策略网络,根据当前状态 si 和搜索历史
来计算所有 action 的概率分布,
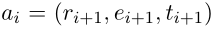
,
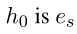
。The embedding the action
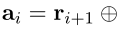
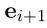 ,
,
是连接操作。
利用 LSTM 将候选路径 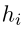 编码成向量
编码成向量 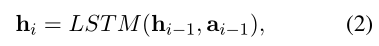 。
。
对于每一步 i,action space 都是通过叠加 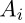 中所有的 action 来嵌入编码的。
中所有的 action 来嵌入编码的。
使用 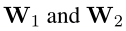 参数化的 MLP 来计算所有 action 的分布
参数化的 MLP 来计算所有 action 的分布
,
 ,
,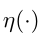
是 softmax 函数,
 是 ReLU 函数,
是 ReLU 函数,是阶段 1 中所有可学习参数的集合。
3.3 Randomized Beam Search
在 TKGs 中,一个事件的发生可能是由多个因素造成的,因此预测需要多条线索路径,采用随机波束搜索。
具体来说,在第 i 步,一个 beam 包含 B 候选线索路径,对于每个候选路径,给每个路径末尾添加最可能的 action(根据公式 3),从而生成一个新的路径池。然后,要么用概率 μ 选取得分最高的路径,要么用概率 1-μ 重复地对随机路径进行均匀采样。每个候选路径的得分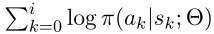
。
4.Stage 2:Temporal Reasoning
为了从不同时间戳的线索事实和并发的线索事实中分别挖掘出更深的时间信息和结构化信息,阶段 2 把所有的线索事实重整为一系列的图
,每个图
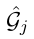 是一个由在时间戳
是一个由在时间戳下的线索事实组成的多关系图,使用 RGCN 来建模
。

 表示在时间戳 j 下在
表示在时间戳 j 下在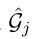
中实体 o 和 s 各自在第
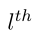
层的嵌入;
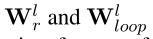 是在第
是在第
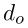 是实体 o 的入度;
是实体 o 的入度;
在公式 4 下,计算出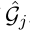
的嵌入
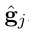
,然后连接
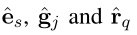
交给GRU处理
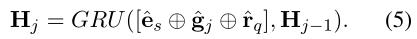
,然后将 GRU 的输出
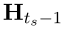
交给 使用
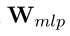 参数化解码的 MLP 来得到所有实体的最终得分
参数化解码的 MLP 来得到所有实体的最终得分 ,
, 是 sigmoid 激活函数。
是 sigmoid 激活函数。
最后根据公式 6 的得分对候选实体重新排序。为了获得到达答案的线索路径的一个正向反馈,阶段 2 给 阶段 1 一个波束级的奖励,这个奖励等于公式 6 的最终得分。
5. Training Strategy
阶段 1 中,波束搜索策略网络是通过训练训练集,使其最大化所有查询的期望回报,并使用 REINFORCE 算法来优化。
先阶段 1 预训练,然后在阶段 2 冻结阶段 1 的参数下训练,最后再联合训练阶段 1 和 2。
Experiment
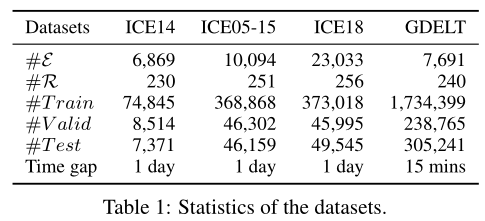
传统的 TKGs :ICEWS14、 ICEWS05-15、 ICEWS18、GDELT。
数据集: Integrated Crisis Early Warning System (ICEWS)、 Global Database of Events, Language, and Tone (GDELT)
Baseline
和两类模型比较:
- 静态KG模型:DistMult、ComplEx、RGCN、 ConvE、RotaE (这种会忽略时间戳信息)
- TKG 推断模型:MINERVA、the RL-based multi-hop reasoning model
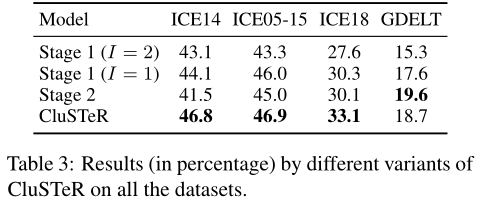
Result