首先了解KafkaProduce发送消息流程
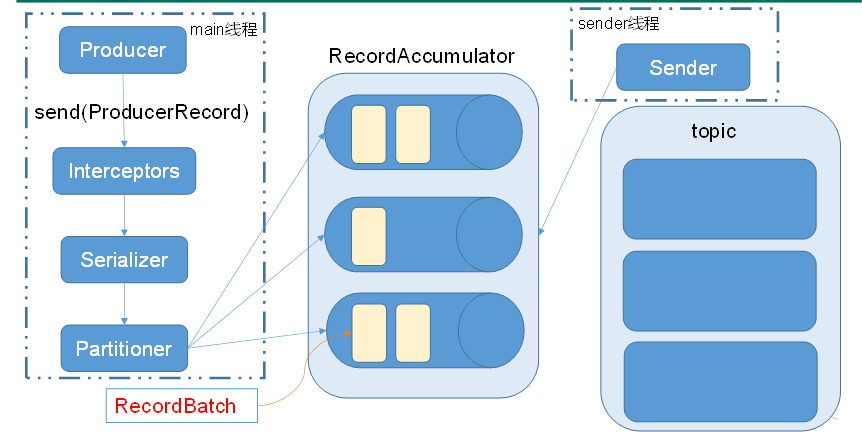
一、定义一个简单的生产者(不会写找源码抄--改)
代码:
public static void main(String[] args) { //producer的配置信息 Properties props = new Properties();
// 服务器的地址和端口 props.put("bootstrap.servers", "hadoop102:9092,hadoop103:9092,hadoop104:9092");
// 接受服务端ack确认消息的参数,0,-1,1 props.put("acks", "all");
// 如果接受ack超时,重试的次数 props.put("retries", 3);
// sender一次从缓冲区中拿一批的数据量 props.put("batch.size", 16384);
// 如果缓冲区中的数据不满足batch.size,只要和上次发送间隔了linger.ms也会执行一次发送 props.put("linger.ms", 1);
// 缓存区的大小 props.put("buffer.memory", 33554432);
//配置生产者使用的key-value的序列化器 props.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // <key,value>,泛型,必须要和序列化器所匹配 Producer<Integer, String> producer = new KafkaProducer<>(props); for (int i = 0; i < 10; i++){ producer.send(new ProducerRecord<Integer, String>("test1", i, "atguigu"+i)); }
producer.close(); }
二、自定义分区器
注意事项:
1、查找主题的分区数:找源码中是如何获取的,抄过来即可
代码:
public class MyPartitioner implements Partitioner { //为每个ProduceRecord计算分区号 // 根据key的hashCode() % 分区数 @Override public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { //获取主题的分区数 List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); int numPartitions = partitions.size(); return (key.hashCode() & Integer.MAX_VALUE) % numPartitions; } // Producer执行close()方法时调用 @Override public void close() { } // 从Producer的配置文件中读取参数,在partition之前调用 @Override public void configure(Map<String, ?> configs) {
} }
2、在Produce中设置自定义分区器
代码:
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.atguigu.kafka.custom.MyPartitioner");
三、自定义拦截器
注意事项:
1、拦截器链的概念,是一个集合,需要把拦截器放入到一个集合中,先放入的先执行
2、拦截器链:生产数据时,拦截一次,sender线程返回ack时,拦截一次
代码:
public class TimeStampInterceptor implements ProducerInterceptor<Integer,String> { //拦截数据 @Override public ProducerRecord<Integer, String> onSend(ProducerRecord<Integer, String> record) { String newValue=System.currentTimeMillis()+"|"+record.value(); return new ProducerRecord<Integer, String>(record.topic(),record.key(),newValue); } //当拦截器收到此条消息的ack时,会自动调用onAcknowledgement() @Override public void onAcknowledgement(RecordMetadata metadata, Exception exception) { } // Producer关闭时,调用拦截器的close() @Override public void close() { } //读取Producer中的配置 @Override public void configure(Map<String, ?> configs) { } }
3、在Produce中设置自定义拦截器
代码:
//拦截器链 ArrayList<String> interCeptors = new ArrayList<>(); // 添加的是全类名,注意顺序,先添加的会先执行 interCeptors.add("com.atguigu.kafka.custom.TimeStampInterceptor"); interCeptors.add("com.atguigu.kafka.custom.CounterInterceptor"); //设置拦截器 props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,interCeptors);