一、元字符
1、.表示匹配任意单个字符;
2、[]表示字符种类,如0-9,a-z,A-Z,表示范围;
3、[^]里面的^表示匹配的是除[]内的其他字符;
4、*表示匹配>=0个字符,如/abc*/表示匹配ab后面跟任意个c;
5、+表示匹配>=1个字符,如/abc+/表示匹配ab后面跟至少1个c;
6、?表示匹配的这个字符可有可无,如/abc?/表示匹配的是ab或abc;
7、{n, m}表示匹配的字符数num为n<=num<=m,
如/abc{2, 3}/表示匹配ab后跟2~3个c,/abc{2,}表示匹配ab后跟至少2个c。
8、(xyz)表示字符集,只匹配xyz这个字符串;
9、|表示或,如(a|b)表示匹配的是a或b;
10、^$分别表示匹配字符串的开头和结尾,如/^<[div|span]>$/表示匹配的是<div>或<span>;
11、转义字符,用来匹配一些保留字符[](){}.*+?^$/。
二、锚点
用来指定开头和结尾,使用^和$来实现。
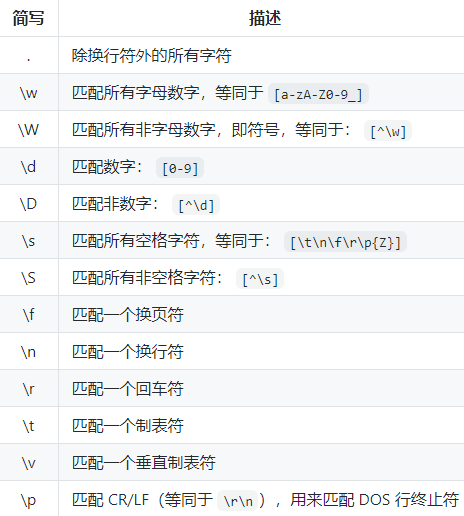
三、简写字符集
四、零宽度断言(以下为我自己的理解,正表存在,负表排除)
1、(?=...),正先行断言,判断匹配表达式后面是否存在...,匹配到的表达式后面需要存在...;
2、(?!...),负先行断言,判断匹配表达式后面是否存在...,匹配到的表达式后面排除...,也就是不存在...才符合;
3、(?<=...),正后发断言,判断匹配表达式前面是否存在...,匹配到的表达式前面需要存在...;
4、(?<!...),负先行断言,判断匹配表达式前面是否存在...,匹配到的表达式前面排除...,也就是不存在...才符合。
五、标志
1、i表示忽略大小写;
2、g表示全局搜索;
3、m为多行修饰符,表达式内^$工作范围在每行的起始。
六、贪婪/惰性匹配
正则表达式默认会启用贪婪匹配,尽可能多的匹配长的字符,如果不想要贪婪匹配则需要加上?开启惰性匹配,其区别如下所示。
被匹配字符串:abcabc
贪婪匹配写法:/(.*bc)/ ——匹配到字符串:abcabc
惰性匹配写法:/(.*?bc)/ ——匹配到的字符串:abc
(内容来源于正则表达式github地址:learn-regex/README-cn.md at master · ziishaned/learn-regex · GitHub)