1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
上次的作业我们讲过什么是过拟合,过拟合就是所建的机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在验证数据集以及测试数据集中表现不佳,机器学习时从样本学习了没用的特征。
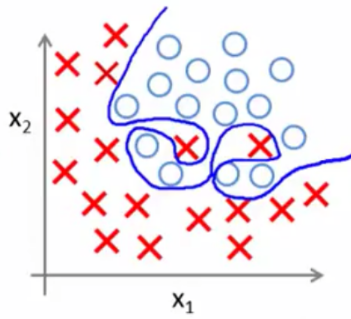
过拟合(也叫做高方差)
在逻辑回归中我们会用到正则化的方法来防止过拟合,正则化的思路就是在损失函数的后面加上模型复杂度的惩罚项,这样在最小化损失函数的时候需要平衡模型误差和模型的复杂度,以此来减小模型的复杂度,从而防止过拟合。
2.用logiftic回归来进行实践操作,数据不限。
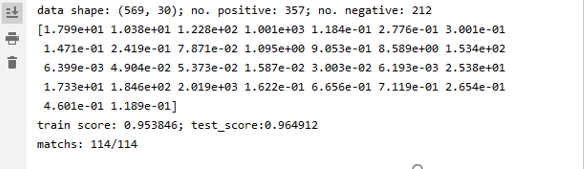
from sklearn.datasets import load_breast_cancer cancer = load_breast_cancer() X = cancer.data y = cancer.target print('data shape: {0}; no. positive: {1}; no. negative: {2}' .format(X.shape,y[y==1].shape[0],y[y==0].shape[0])) print(cancer.data[0]) # 加载load_breast_cancer数据集,并划分训练集与测试集 from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2) # 训练模型 from sklearn.linear_model import LogisticRegression model = LogisticRegression(solver='liblinear') model.fit(X_train,y_train) train_score = model.score(X_train,y_train) test_score = model.score(X_test,y_test) print('train score: {train_score:.6f}; test_score:{test_score:.6f}' .format(train_score=train_score, test_score=test_score)) #计算训练数据集的评分数据和测试数据集的评分数据 import numpy as np y_pred = model.predict(X_test) print('matchs: {0}/{1}'.format(np.equal(y_pred,y_test).shape[0],y_test.shape[0])) # 查看测试样本中预测正确的个数
运行得出: