to
撸的血泪史:大学四年几乎都在宿舍打撸,So,把官网的皮肤都保存下来,存到百度云,就当一种纪念
编辑器:pycharm
用到的包:urllib.request, requests, json, re, os
#######分析:
进入LOL官网,点击资料库,进入所有英雄列表(网址:http://lol.qq.com/web201310/info-heros.shtml)
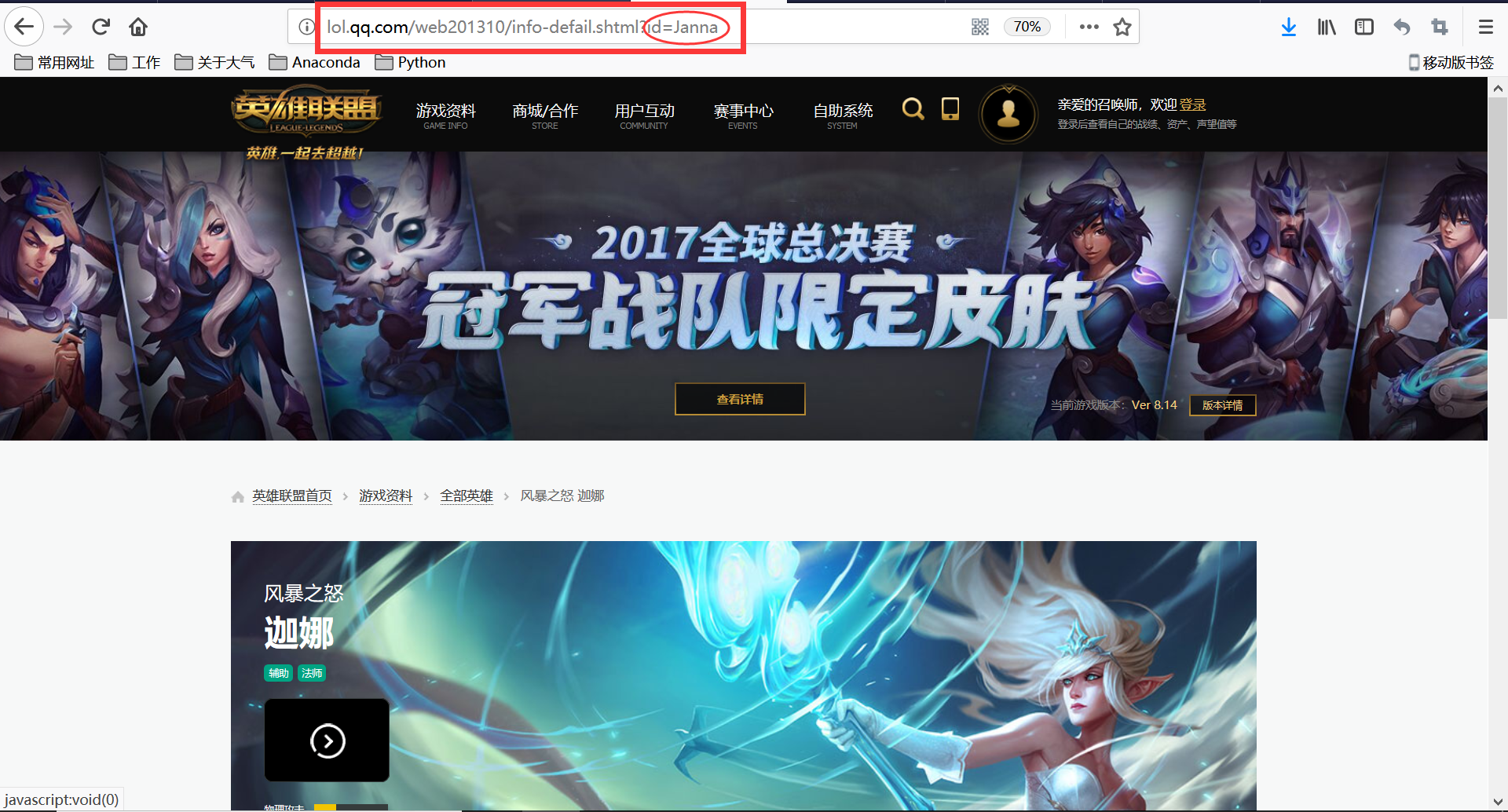
然后单击某个英雄进入皮肤列表,可以发现各个英雄皮肤的网页网址只有一部分是变化,如风女
再如:提莫
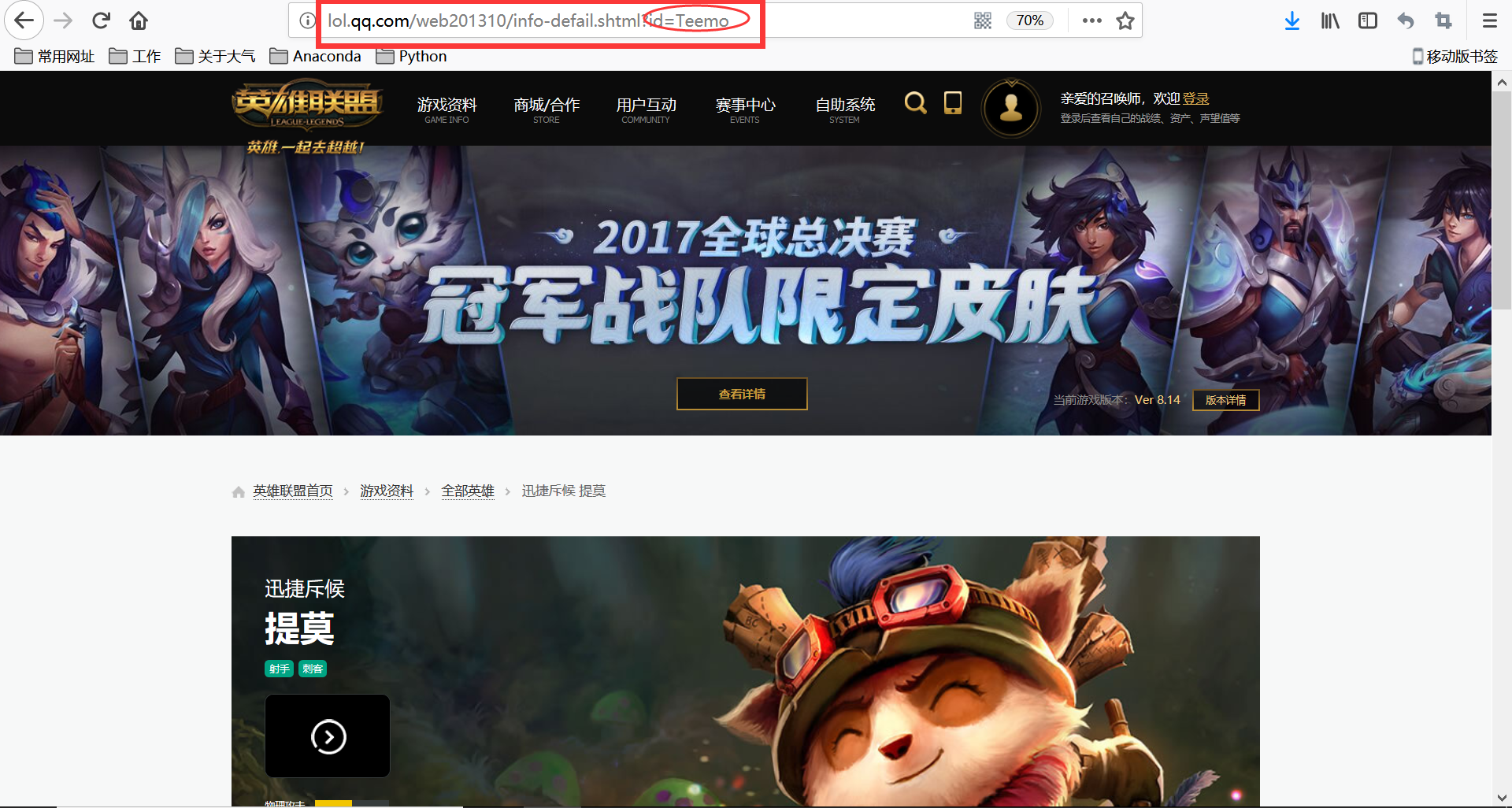
观察发现前面一部分网址是不变的,只有后面一部分的id随不同的英雄而不同
So,皮肤界面的网址是,http://lol.qq.com/web201310/info-defail.shtml? + 英雄id
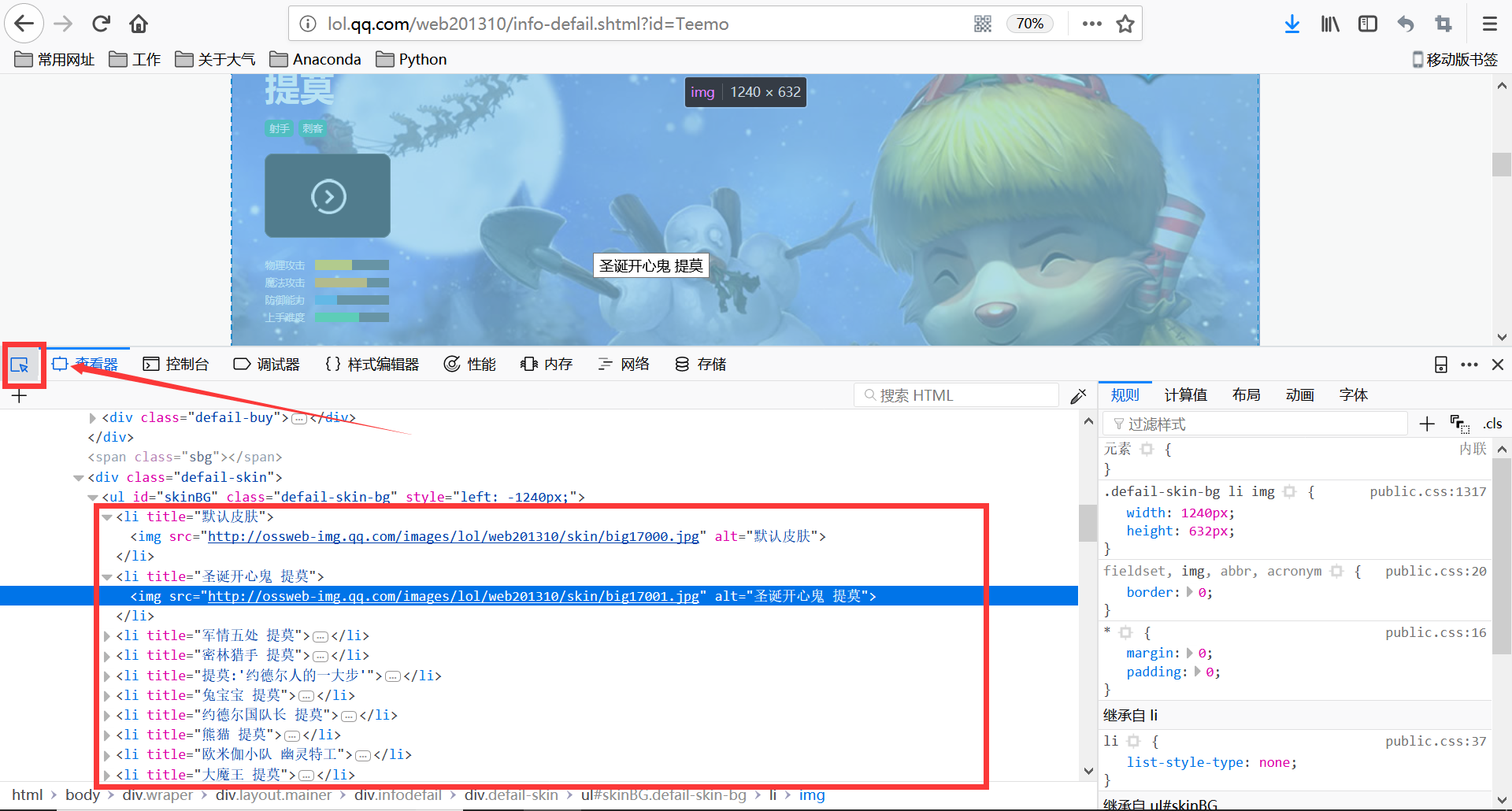
在皮肤页面 切换各个皮肤,利用键盘Fn+F12 (或F12) 用页面元素获取功能 ,鼠标移到到各个皮肤上面,定位到网页代码里面图片的网址
如下图,可以看出皮肤的网址:
http://ossweb-img.qq.com/images/lol/web201310/skin/big17000.jpg
http://ossweb-img.qq.com/images/lol/web201310/skin/big17001.jpg
规律:17是和英雄id对应的数字,000是默认皮肤,从001开始是英雄的皮肤,有几个皮肤就到00几
皮肤的网址是http://ossweb-img.qq.com/images/lol/web201310/skin/big(同一个英雄这部分是不变的)+与英雄id对应的数+皮肤的编号+.jpg
Ps:用程序保存图片和人工差不多,首先要找到该图片然后保存本地。
#######思路
要找到英雄id保存在那个文件and 皮肤id保存在哪个文件(Ps很重要)
进入英雄列表,键盘Fn+F12(或F12) ,点击网络或Network,点选GS。英雄的id在champion.gs文件中
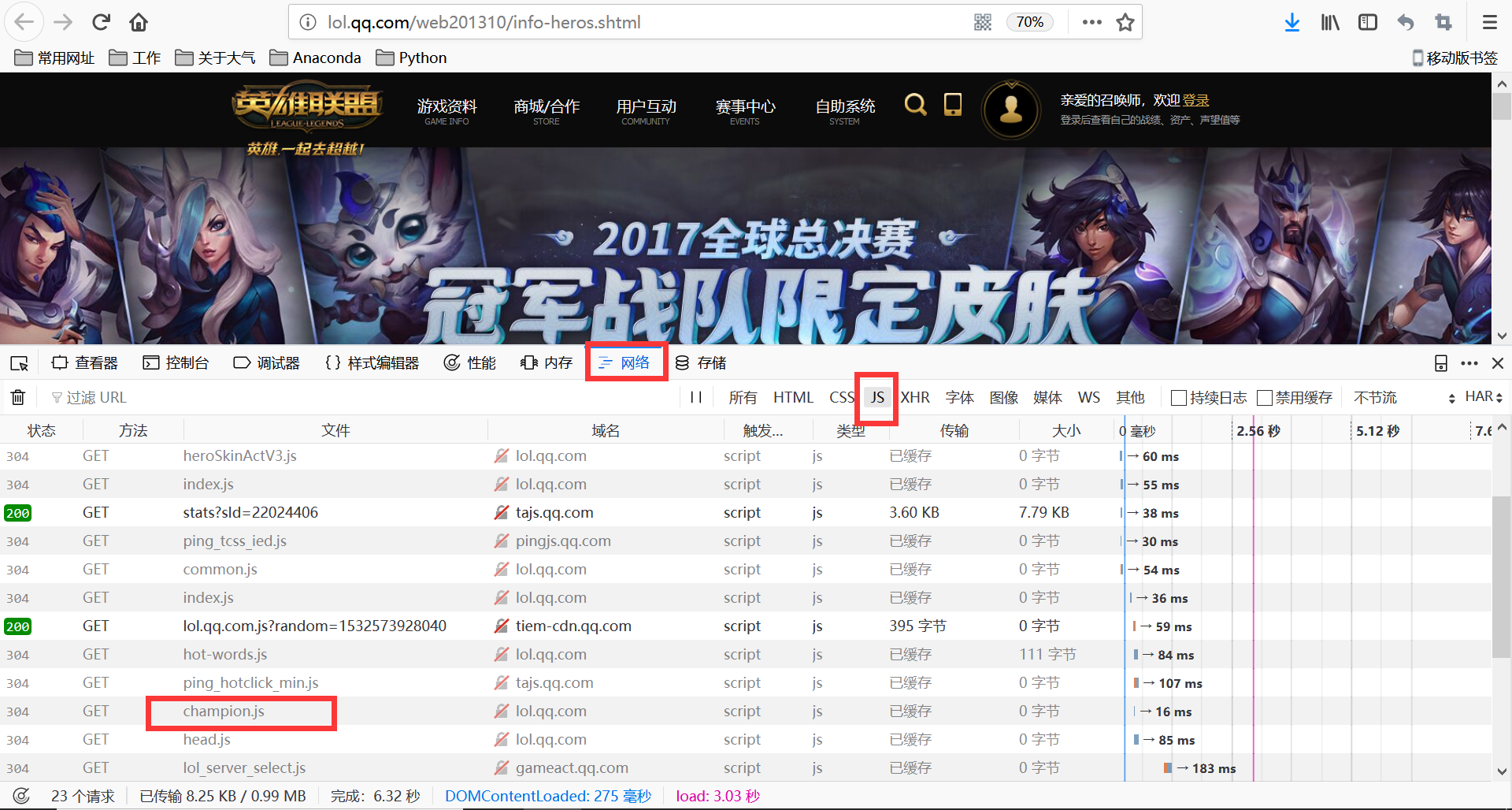
打开这个文件,复制请求网址,在浏览器中打开:观察发现英雄id与其对应的数都在里面
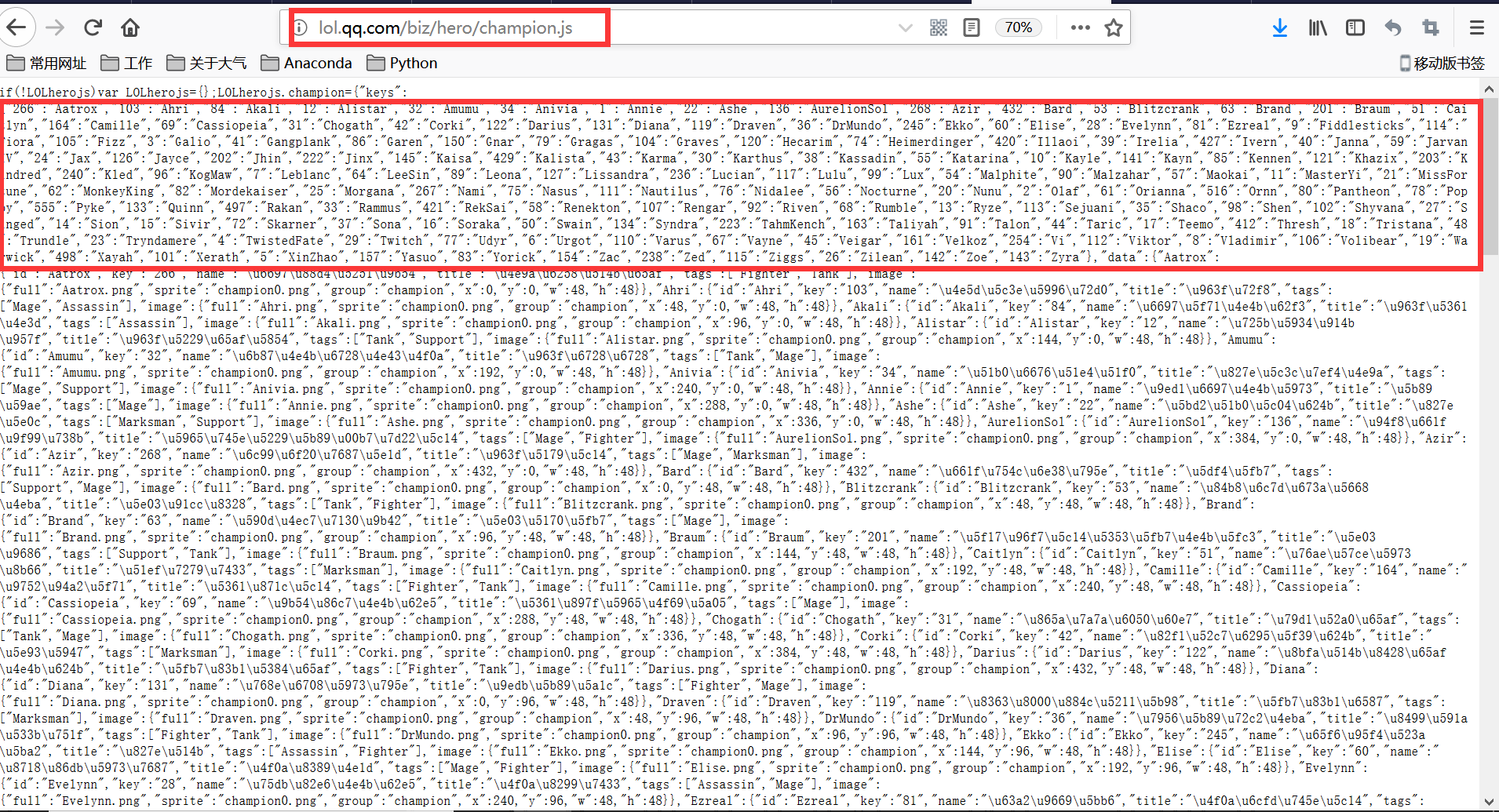
然后进入皮肤界面寻找皮肤id,同理,键盘Fn+F12(或F12) ,点击网络或Network,点选GS。提莫皮肤的id在teemo.gs文件中
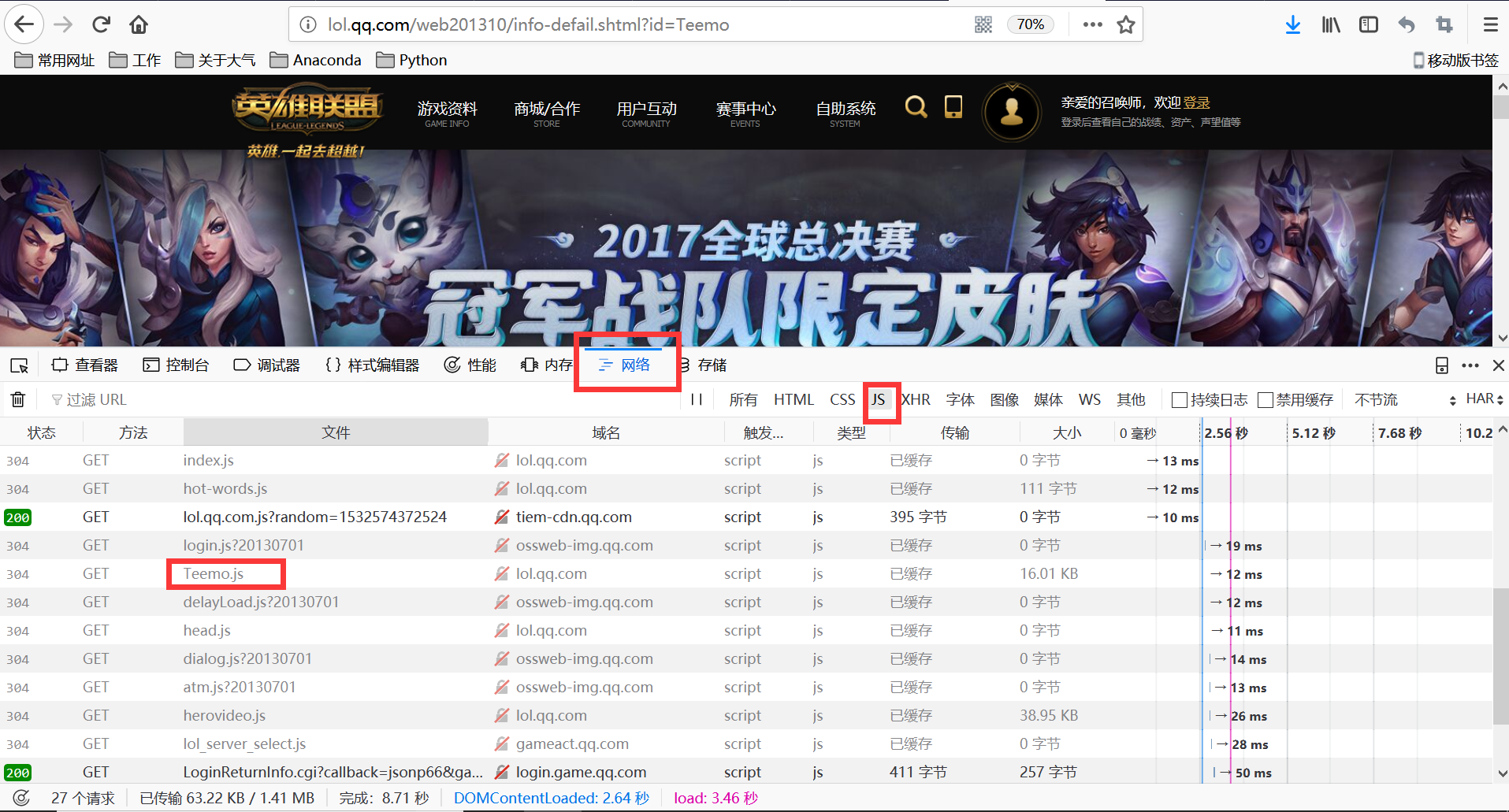
打开gs文件,可以看到皮肤以及其对应的数字都在里面。

#######写代码,找到了皮肤对应的网址,就可以写代码了
import urllib.request, requests, json, re, os
url = r'http://lol.qq.com/biz/hero/champion.js'
data = requests.get(url).text
id_name = re.compile(r'LOLherojs.champion={"keys":(.+?),"data"')
ids = re.findall(id_name, data)
names = list(json.loads(ids[0]).values())
for name in names:
img_js_url = r'http://lol.qq.com/biz/hero/%s.js' % name
data1 = requests.get(img_js_url).text
img_ids = re.findall(re.compile(r'"skins":(.+?)"info"'), data1)
data2 = re.findall(re.compile(r'"id":"(.+?)"'), img_ids[0])
for id in data2:
img_url = r'http://ossweb-img.qq.com/images/lol/web201310/skin/big%s.jpg' % id
base_path = r'D:pycharm_projects estlolskin'
if not os.path.exists(os.path.join(base_path, name)):
os.mkdir(os.path.join(base_path, name))
png_name = str(name) + id + '.png'
save_png_path = os.path.join(base_path, name, png_name)
urllib.request.urlretrieve(img_url, save_png_path)
######解析
import urllib.request, requests, json, re, os # 要用到的库,也可以说包
url = r'http://lol.qq.com/biz/hero/champion.js' # url:统一资源定位符,此处是一个变量。将champion.js的网址以字符串的形式赋值给url
data = requests.get(url).text # 利用 request里面的get()函数将champion.js里面的内容写到一个txt文件中,将该文件命名为data
id_name = re.compile(r'LOLherojs.champion={"keys":(.+?),"data"') # "keys":(.+?),"data"将data里我们需要的部分也就是英雄id和其对应的数标记一下,方便后面取出来。利用re里面的预先编译函数,可以让这一步进行的更流畅
ids = re.findall(id_name, data)#利用re里面的额遍历查询函数把上一部标记的部分以列表的形式返回,结果是将我们需要的部分作为列表的第一个元素返回,列表只有一个元素
names = list(json.loads(ids[0]).values())#json.loads(ids[0])利用json里面的loads函数将上一步列表的第一个元素变为字典,然后.values()将字典的各个元素存到叠加器里里面,list函数再将其强制转换成列表,列表的元素为[英雄id:数字,英雄id:数字.....]
for name in names: #这一步处理英雄皮肤的gs文件如上一步类似
img_js_url = r'http://lol.qq.com/biz/hero/%s.js' % name #皮肤的网址中英雄id这一部分是变的,利用%占位符来进行改变
data1 = requests.get(img_js_url).text
img_ids = re.findall(re.compile(r'"skins":(.+?)"info"'), data1)
data2 = re.findall(re.compile(r'"id":"(.+?)"'), img_ids[0])
for id in data2: #这一步是存储图
img_url = r'http://ossweb-img.qq.com/images/lol/web201310/skin/big%s.jpg' % id #图的网址
base_path = r'D:pycharm_projects estlolskin' #你要把图存放在哪个目录
if not os.path.exists(os.path.join(base_path, name)): #os.path.join(base_path, name)将base_path, name两个路径组合,os是个处理文件夹的库 此句用来判断组合后的目录是否存在
os.mkdir(os.path.join(base_path, name))# 用if判断,如果上一步中的目录不存在存在,os.mkdir,新建该目录
png_name = str(name) + id + '.png'#图的命名包括二部分 英雄id+皮肤id
save_png_path = os.path.join(base_path, name, png_name) #创建子文件夹,每个英雄一个文件夹
urllib.request.urlretrieve(img_url, save_png_path)#将img_url网址下的图片不占资源地保存到上一步创建的文件夹中