前一节聊了子查询,当然很简单的一个应用;子查询的应用还有很多,如充当临时表等,这个可以后续用到再说;
今天主要说一说分组(group by);分组就是以某一个列(包含计算列)来分组统计,通常会跟随使用聚合函数(这个后续再说);
有点类似于excel的数据透视表;如:员工信息表emp、员工的部门编号是deptid;
今天主要说一说分组(group by);分组就是以某一个列(包含计算列)来分组统计,通常会跟随使用聚合函数(这个后续再说);
有点类似于excel的数据透视表;如:员工信息表emp、员工的部门编号是deptid;
1 /* 2 分组查询:以部门编码为分组依据,查询每个部门有多少员工 3 */ 4 select deptid,count(eid) 5 from emp 6 group by deptid 7 --需要注意的是:select子句后面的所有项如果不是聚合函数,那么必须在group by 子句中列出 8 --如:以部门编号及性别分组 9 select deptid,sex,count(eid) 10 from emp 11 group by deptid,sex 12 --分组后的过滤:列举部门人数高于30人的部门编号及人数 13 select deptid,count(eid) as perno 14 from emp 15 group by deptid 16 having COUNT(eid)>30

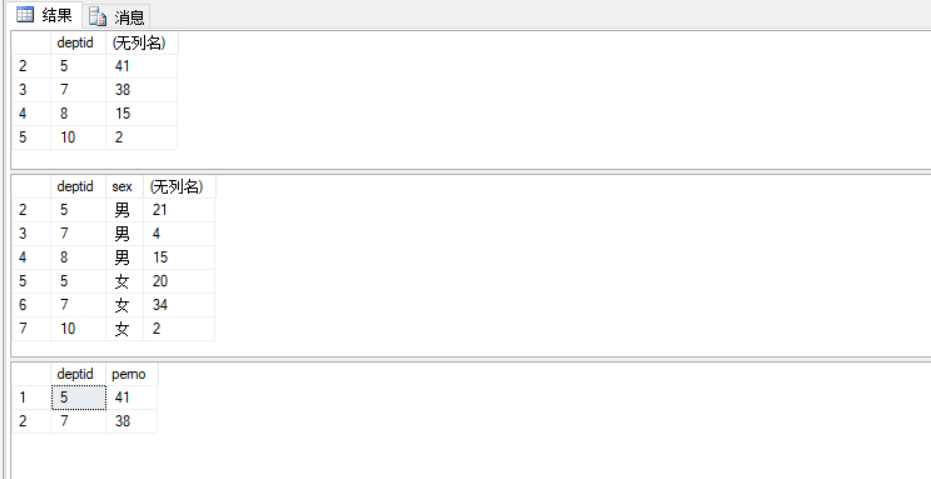
当然count(eid)在数据记录不多的时候也常常写成count(*),其实用count(主键)方式来写更加高效;
另外,需要注意的是:having与where之间是有区别的;
1、where子句需要写在group by前,having需要写在其后
2、where 是在查询结果之前就已经筛选掉了不符合where条件的记录,而having是在查询出结果之后过滤
1、where子句需要写在group by前,having需要写在其后
2、where 是在查询结果之前就已经筛选掉了不符合where条件的记录,而having是在查询出结果之后过滤