MapReduce: Simplified Data Processing on Large Clusters
MapReduce是什么?
a programming model and an associated implementation for processing and generating large data sets 一个编程模型,主要用于处理大数据
Users specify a map function that processes a key/value pair to generate a set of intermediate key/value pairs, and a reduce function that merges all intermediate values associated with the same intermediate key. MapReduce由MapFunc和ReduceFunc两部分组成,MapFunc接受输入,产生intermediate,而ReduceFunc合并intermediate中键相同的list,最后输出。
中心化架构
master负责了容错、任务分配、状态控制等工作。而worker负责map和Reduce
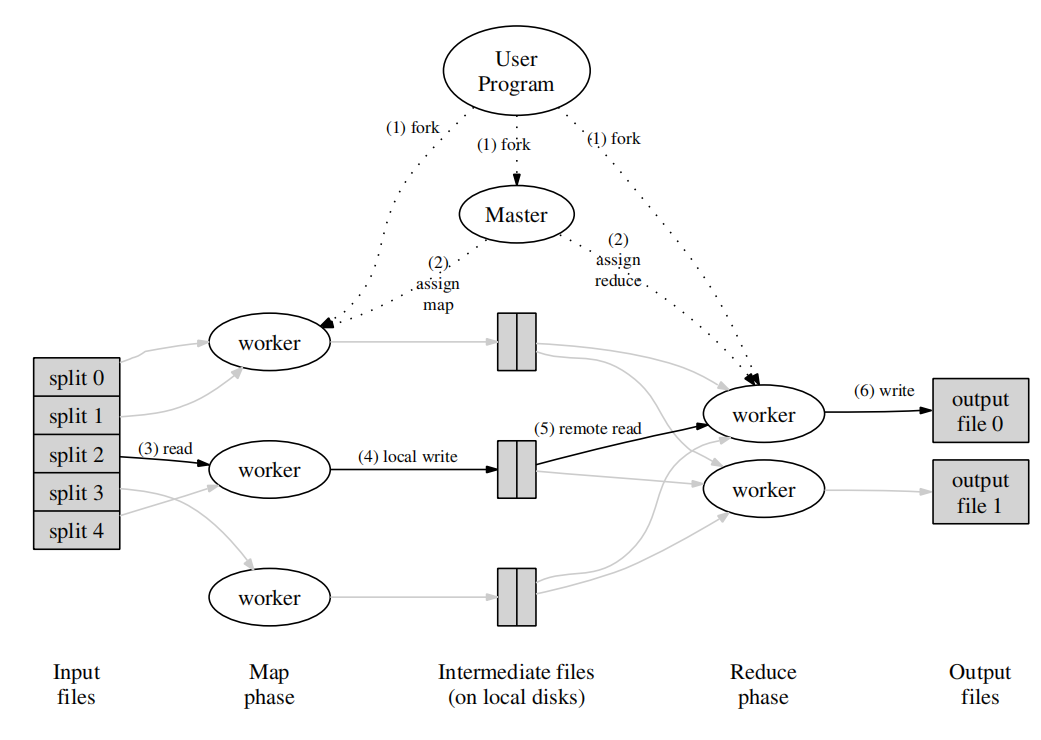
执行过程
The MapReduce library in the user program fifirst splits the input fifiles into M(方便并行化) pieces of typically 16 megabytes to 64 megabytes (MB)(文件大小可以自定义,会影响文件数量,进而影响性能) per piece (controllable by the user via an optional parameter). It then starts up many copies of the program on a cluster of machines.
One of the copies of the program is special – the master. The rest are workers that are assigned work by the master. There are M map tasks and R reduce tasks to assign. The master picks idle workers and assigns each one a map task or a reduce task.(空闲调度)
A worker who is assigned a map task reads the contents of the corresponding input split. It parses key/value pairs out of the input data and passes each pair to the user-defifined Map function. The intermediate key/value pairs produced by the Map function are buffered in memory.(将中间数据保存在内存中,提高性能)
Periodically, the buffered pairs are written to local disk,(把内存的数据周期写进磁盘,我的理解:一方面减少内存压力,一方面持久化) partitioned into R regions by the partitioning function. (磁盘被分区成R区,对应R个reduce任务,这里需要使用分区函数,一般是hash(key)mod R)The locations of these buffered pairs on the local disk are passed back to the master, who is responsible for forwarding these locations to the reduce workers.(这里应该是任务完成后,才发送磁盘分区的位置给master,然后所以Map任务完成后,master发给对应的Reduce)
When a reduce worker is notifified by the master about these locations, it uses remote procedure calls to read the buffered data from the local disks of the map workers.(ReduceWorker通过RPC获取map worker中的数据) When a reduce worker has read all intermediate data, it sorts it by the intermediate keys so that all occurrences of the same key are grouped together.(在读取所有的中间数据后,才进行数据排序与组合) The sorting is needed because typically many different keys map to the same reduce task. If the amount of intermediate data is too large to fifit in memory, an external sort is used.(如果数据规模太大无法在内存中直接排序,就进行外部排序)
The reduce worker iterates over the sorted intermediate data and for each unique intermediate key encountered, it passes the key and the corresponding set of intermediate values to the user’s Reduce function. The output of the Reduce function is appended to a fifinal output fifile for this reduce partition.
When all map tasks and reduce tasks have been completed, the master wakes up the user program. At this point, the MapReduce call in the user program returns back to the user code.
输入:M个map task, 输出:R个 reduce results,中间数据: M*R
容错
Worker Failure
The master pings every worker periodically. If no response is received from a worker in a certain amount of time, the master marks the worker as failed. Any map tasks completed by the worker are reset back to their initial idle state, and therefore become eligible for scheduling on other workers. Similarly, any map task or reduce task in progress on a failed worker is also reset to idle and becomes eligible for rescheduling
定时通信,判断worker是否故障。故障worker的状态置为failed,所执行的任务被重置并重分配给其他worker。 (下文有说,其实已经完成的Reduce任务可以不重分配,因为已经保存到全局文件系统了)
When a map task is executed fifirst by worker A and then later executed by worker B (because A failed), all workers executing reduce tasks are notifified of the reexecution. Any reduce task that has not already read the data from worker A will read the data from worker B.
这里的理解是:如果一个Reduce Worker接收到了A的信息,那么它就不需要再次去读取相应的map task产生的数据了,所以这里只是通知了“has not already read the data”的reduce worker
Master Failure
It is easy to make the master write periodic checkpoints of the master data structures described above. If the master task dies, a new copy can be started from the last checkpointed state. However, given that there is only a single master, its failure is unlikely; therefore our current implementation aborts the MapReduce computation if the master fails. Clients can check for this condition and retry the MapReduce operation if they desire. 周期性写入磁盘,创建checkpoint
性能设计
- The MapReduce master takes the location information of the input fifiles into account and attempts to schedule a maptask on a machine that contains a replica of the corresponding input data. Failing that, it attempts to schedule a map task near a replica of that task’s input data (e.g., on a worker machine that is on the same network switch as the machine containing the data). When running large MapReduce operations on a signifificant fraction of the workers in a cluster, most input data is read locally and consumes no network bandwidth.(master在调度任务的时候会考虑“距离”问题,M个输入更多的是来自本地操作,以便减小网络压力)
- We subdivide the map phase into M pieces and the reduce phase into R pieces, as described above. Ideally, M and R should be much larger than the number of worker machines. Having each worker perform many different tasks improves dynamic load balancing, and also speeds up recovery when a worker fails: the many map tasks it has completed can be spread out across all the other worker machines(一个机器运行多个worker)
- We have a general mechanism to alleviate the problem of stragglers. When a MapReduce operation is close to completion, the master schedules backup executions of the remaining in-progress tasks(备用任务,当整个MR的工作快要完成的时候,选择部分idle的worker去重新执行当前未完成的任务)
- ....
从服务使用者的角度看,MapReduce只是由Map和Reduce两个函数组成,这可能会让人对mapreduce有所轻视(事实上,在我不了解map和Reduce细节的时候,我也是这样的)。但仔细一想,这却恰恰是mapreduce设计合理之处。它隐藏了底层的诸如差错控制、调度、数据存储与转发等细节,而只暴露出两个API,使得使用门槛大大降低。
通过阅读这篇论文(也许这算得上是早期的分布式计算了?),也让我对分布式领域有了更多的兴趣。下面就阅读GFS和BigTable,继续学习吧~~