场景
MapReduce Java API-多输入路径方式:
https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/119453275
在上面的基础上,怎样用Partitioner的方式实现将学生的成绩数据
分段输出到不同的文件。
例如分为三个成绩段:
小于60分
大于等于60分小于等于80分
大于80分
Partitioner
1、Partion发生在Map阶段的最后,会先调用job.setPartitionerClass对这个List进行分区,
每个分区映射到一个Reducer。每个分区内又调用job.setSortComparatorClass设置的key
比较函数类排序。
2、 Partitioner的作用是对Mapper产生的中间结果进行分片,以便将同一个分组的数据交给同一个Reducer处理,
它直接影响Reducer阶段的复杂均衡。
3、Partitioner创建流程
① 先分析一下具体的业务逻辑,确定大概有多少个分区
②
首先书写一个类,它要继承org.apache.hadoop.mapreduce.Partitioner这个类
③
重写public int getPartition这个方法,根据具体逻辑,读数据库或者配置返回相同的数字
④
在main方法中设置Partioner的类,job.setPartitionerClass(DataPartitioner.class);
⑤ 设置Reducer的数量,job.setNumReduceTasks(6);
注:
博客:
https://blog.csdn.net/badao_liumang_qizhi
关注公众号
霸道的程序猿
获取编程相关电子书、教程推送与免费下载。
实现
1、首先新建数据集score.txt,用来进行分段输出。

1、自定义分区函数类
通过成绩判断,用return的值为0、1、2代表三个分区。
package com.badao.muloutput; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; public class StudentPartitioner extends Partitioner<IntWritable, Text> { @Override public int getPartition(IntWritable intWritable, Text text, int i) { //学生成绩 int scoreInt = intWritable.get(); //默认指定分区0 if(i==0) { return 0; } if(scoreInt < 60) { return 0; }else if(scoreInt<=80) { return 1; }else { return 2; } } }
3、定义Mapper类
package com.badao.muloutput; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class MulOutputMapper extends Mapper<LongWritable,Text,IntWritable,Text> { @Override public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] studentArr = value.toString().split(" "); if(StringUtils.isNotBlank(studentArr[1])) { IntWritable pKey = new IntWritable(Integer.parseInt(studentArr[1].trim())); context.write(pKey,value); } } }
4、定义Reduce类
package com.badao.muloutput; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class MulOutputReducer extends Reducer<IntWritable,Text,NullWritable,Text> { @Override public void reduce(IntWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException { for(Text value:values) { context.write(NullWritable.get(),value); } } }
5、新建Job类
package com.badao.muloutput; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.reduce.IntSumReducer; import java.io.IOException; public class MulOutputJob { public static void main(String[] args) throws InterruptedException, IOException, ClassNotFoundException { wordCountLocal(); } public static void wordCountLocal()throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); System.setProperty("HADOOP_USER_NAME","root"); conf.set("fs.defaultFS","hdfs://192.168.148.128:9000"); //实例化一个作业,word count是作业的名字 Job job = Job.getInstance(conf, "muloutput"); //指定通过哪个类找到对应的jar包 job.setJarByClass(MulOutputJob.class); //为job设置Mapper类 job.setMapperClass(MulOutputMapper.class); //为job设置reduce类 job.setReducerClass(MulOutputReducer.class); //设置Partitioner类 job.setPartitionerClass(StudentPartitioner.class); //设置reduce的个数为3 job.setNumReduceTasks(3); //mapper输出格式 job.setMapOutputKeyClass(IntWritable.class); job.setMapOutputValueClass(Text.class); //reduce输出格式 job.setOutputKeyClass(NullWritable.class); job.setOutputValueClass(Text.class); //为job设置输入路径,输入路径是存在的文件夹/文件 FileInputFormat.addInputPath(job,new Path("/score.txt")); //为job设置输出路径 FileOutputFormat.setOutputPath(job,new Path("/muloutput8")); job.waitForCompletion(true); } }
6、将数据集上传到HDFS指定的目录下,运行job查看输出结果
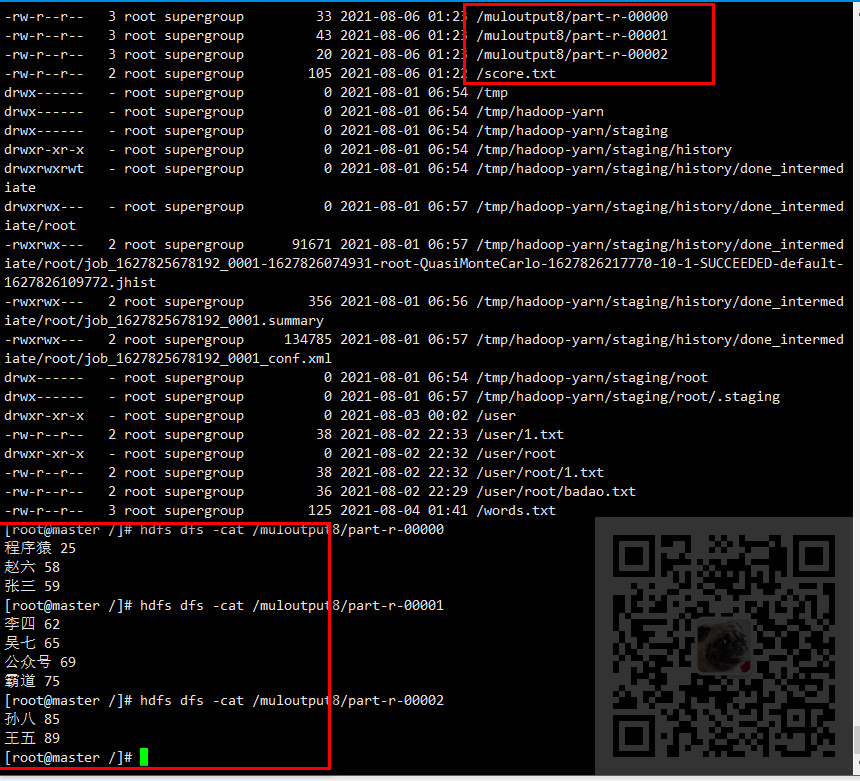
注意事项
这里要注意坑点,因为这里在分解数据时是按照一个空格来拆分的,所以数据集中
每个key和value之间只能有一个空格。
并且不要再数据集的最后面添加多余的换行,不然会导致不能正常输出数据。
比如这里查看数据时发现多了个换行

然后找不到不出统计数据的原因,就在代码中将每步的结果输出下
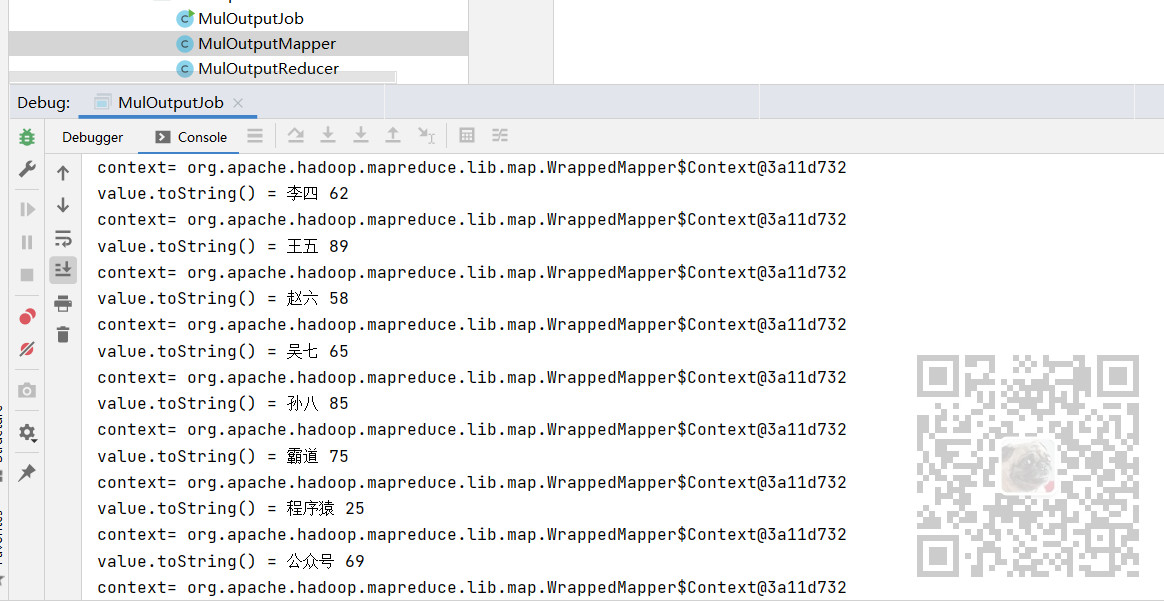
如果是上面多了换行的话,下面输出key-value时就会有异常数据,都跟上面这样是正常的。