书上的代码:


1 # coding: utf-8 2 3 # In[1]: 4 5 import matplotlib.pyplot as plt 6 import numpy as np 7 import tensorflow as tf 8 from pylab import * 9 10 11 # In[19]: 12 13 def show_activation(activation,y_lim=5): 14 x=np.arange(-10., 10., 0.01) 15 ts_x = tf.Variable(x) 16 ts_y =activation(ts_x ) 17 with tf.Session() as sess: 18 init = tf.global_variables_initializer() 19 sess.run(init) 20 y=sess.run(ts_y) 21 ax = gca() 22 ax.spines['right'].set_color('none') 23 ax.spines['top'].set_color('none') 24 ax.spines['bottom'].set_position(('data',0)) 25 ax.spines['left'].set_position(('data',0)) 26 ax.xaxis.set_ticks_position('bottom') 27 ax.yaxis.set_ticks_position('left') 28 lines=plt.plot(x,y) 29 plt.setp(lines, color='b', linewidth=3.0) 30 plt.ylim(y_lim*-1-0.1,y_lim+0.1) 31 plt.xlim(-10,10) 32 33 plt.show() 34 35 36 # In[20]: 37 38 show_activation(tf.nn.sigmoid,y_lim=1) 39 40 41 # In[4]: 42 43 show_activation(tf.nn.softsign,y_lim=1) 44 45 46 # In[5]: 47 48 show_activation(tf.nn.tanh,y_lim=1) 49 50 51 # In[6]: 52 53 show_activation(tf.nn.relu,y_lim=10) 54 55 56 # In[7]: 57 58 show_activation(tf.nn.softplus,y_lim=10) 59 60 61 # In[8]: 62 63 show_activation(tf.nn.elu,y_lim=10) 64 65 66 # In[14]: 67 68 a = tf.constant([[1.0,2.0],[1.0,2.0],[1.0,2.0]]) 69 sess = tf.Session() 70 print(sess.run(tf.sigmoid(a))) 71 72 73 # In[ ]:
sigmoid激活函数:
S(x)=1/(1+e-x)

优点在于输出映射在0-1内,单调连续,适合做输出层,求导容易。
缺点在于软饱和性,即当x趋于无穷大时,一阶导数趋于0,容易产生梯度消失,神经网络的改善缓慢或消失。
softsign激活函数:
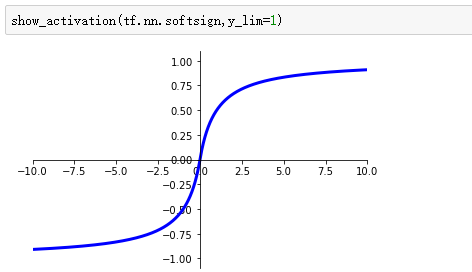
tanh激活函数:
tanh(x)=(1-e-2x)/(1+e-2x)

也具有软饱和性,收敛速度比sigmoid快,但是仍无法解决梯度消失的问题。
relu激活函数:
f(x)=max(x,0)

缺点:当relu在x<0时硬饱和,即在负半轴,激活函数的一阶导数等于0。
优点:由于x>0时导数为1,所以relu能在正半轴保持梯度的不衰减,缓解梯度消失的问题。
但是随着训练的进行,部分落入硬饱和区,权重无法更新。
softplus激活函数:
relu的平滑版本f(x)=log(1+exp(x))
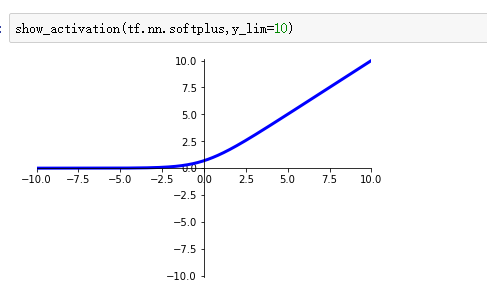
此外还有的激活函数如下数张图:
等等..............................................................................................
......................................................................................................
输入数据特征相差明显时,tanh效果较好,不明显时,sigmoid较好。二者在使用时需要对输入进行规范化,减少进入平坦区的可能。
relu是比较流行的激活函数,不需要输入量的规范化等...