一、索引介绍
1.1、什么是索引?
一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句的优化显然是重中之重。说起加速查询,就不得不提到索引了。
1.2、为什么要使用索引?
索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要。 索引优化应该是对查询性能优化最有效的手段了。索引能够轻易将查询性能提高好几个数量级。
索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。
二、索引的原理
通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
2.1、索引的数据结构
任何一种数据结构都不是凭空产生的,一定会有它的背景和使用场景,我们现在总结一下,我们需要这种数据结构能够做些什么,其实很简单,那就是:每次查找数据时把磁盘IO次数控制在一个很小的数量级,最好是常数数量级。那么我们就想到如果一个高度可控的多路搜索树是否能满足需求呢?就这样,b+树应运而生。
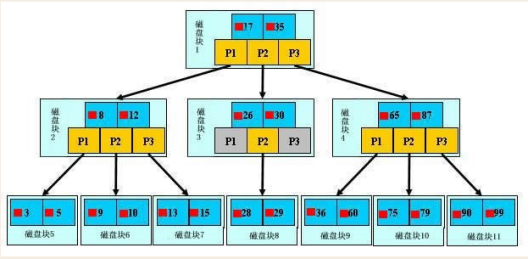
如上图,是一颗b+树,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非叶子节点不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
2.2、b+树的查找过程
如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
三、MySQL的索引分类
1、普通索引index:加速查找
2、唯一索引
主键索引:primary key :加速查找+约束(不为空且唯一)
唯一索引:unique:加速查找+约束 (唯一)
3、联合索引
-primary key(id,name):联合主键索引
-unique(id,name):联合唯一索引
-index(id,name):联合普通索引
4、全文索引fulltext :用于搜索很长一篇文章的时候,效果最好。
5、空间索引spatial :了解就好,几乎不用
四、添加索引需遵循的原则
4.1、最左前缀匹配原则:必须按照从左到右的顺序匹配
如果创建索引:create index ix_name_email on s1(name,email) //组合索引
select * from s1 where name='egon'; //可以
select * from s1 where name='egon' and email='asdf'; //可以
select * from s1 where email='alex@oldboy.com'; //不可以
mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配。
比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。所以,把需要范围查询的索引尽量放在靠后的位置。
最左前缀示例:
1 mysql> select * from s1 where id>3 and name='egon' and email='alex333@oldboy.com' and gender='male'; 2 Empty set (0.39 sec) //未创建索引 3 4 5 6 mysql> create index idx on s1(id,name,email,gender); //创建索引 7 Query OK, 0 rows affected (15.27 sec) 8 Records: 0 Duplicates: 0 Warnings: 0 9 10 11 12 mysql> select * from s1 where id>3 and name='egon' and email='alex333@oldboy.com' and gender='male'; 13 Empty set (0.43 sec) //未遵循最左前缀原则 14 15 16 17 mysql> drop index idx on s1; 18 Query OK, 0 rows affected (0.16 sec) 19 Records: 0 Duplicates: 0 Warnings: 0 //删除刚才创建的错误索引 20 21 22 23 mysql> create index idx on s1(name,email,gender,id); //创建正确的索引 24 Query OK, 0 rows affected (15.97 sec) 25 Records: 0 Duplicates: 0 Warnings: 0 26 27 28 29 mysql> select * from s1 where id>3 and name='egon' and email='alex333@oldboy.com' and gender='male'; 30 Empty set (0.03 sec) //遵循最左前缀原则
4.2、索引列不能参与计算
索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’ 就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值, 但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。 所以语句应该写成create_time = unix_timestamp(’2014-05-29’);
五、索引无法命中的情况
- like '%xx'
select * from tb1 where email like '%cn';
特别的:如果是 select * from tb1 where email like 'cn%'; 则可以使用到索引
两边都有“%”,则索引也不起作用,这时候,如果想让 select * from tb1 where email like '%cn%' 的索引起作用,最好使用覆盖索引,即select查询的字段就是索引字段。
- 使用函数
select * from tb1 where reverse(email) = 'wupeiqi';
- or
select * from tb1 where nid = 1 or name = 'seven@live.com';
特别的:如果or条件中,所有的字段都有索引,则会走索引。只要有一个字段没索引,则不走索引。
- 类型不一致
如果列是字符串类型,传入条件是必须用引号引起来,不然索引失效
select * from tb1 where email = 999;
- !=
select * from tb1 where email != 'alex'
特别的:如果是主键,则还是会走索引
select * from tb1 where nid != 123
-is null 或者is not null 也无法使用索引
- >
select * from tb1 where email > 'alex'
特别的:如果是主键或索引是整数类型,则还是会走索引
select * from tb1 where nid > 123
select * from tb1 where num > 123
- order by
select name from s1 order by email desc; //不走索引
当根据索引排序时候,select查询的字段如果不是索引,则不走索引
select email from s1 order by email desc; //走索引
特别的:如果对主键排序,则还是走索引:
select * from tb1 order by nid desc; //走索引
- 组合索引最左前缀
如果组合索引为:(name,email)
name and email //使用索引
name //使用索引
email //不使用索引