1 mysql分页原理
假设数据库表student存在13条数据。
语句1:select * from student limit 9,4
语句2:slect * from student limit 4 offset 9
// 语句1和2均返回表student的第10、11、12、13行
//语句1中的4表示返回4行,9表示从表的第十行开始
//语句2中的4表示返回4行,9表示从表的第十行开始
通过limit和offset 或只通过limit可以实现分页功能
假设 numberperpage 表示每页要显示的条数
pagenumber表示页码
那么 返回第pagenumber页,每页条数为numberperpage的sql语句写法为
语句3:select * from studnet limit (pagenumber-1)*numberperpage,numberperpage
语句4:select * from student limit numberperpage offset (pagenumber-1)*numberperpage
2 mysql limit优化
MySQL limit 操作常用于程序中的分页,但是如果你没有了解过limit的机制和相关优化原理,一旦数据量上升,程序的性能将会惨不忍睹,所以下面总结几种mysql关于limit优化实例,每个实例后对应都会有演示。(演示的数据来自15年暑期实习的p2p流量数据,表数据量约300W行)
1、sql中会范的错误
- select XXX from tableA limit 1000000,10;
上面的语句是取1000000后面的10条记录,但是这样会导致mysql将1000000之前的所有数据全部扫描一次,大量浪费了时间。截图是我扫描100W数据花费的时间,大概是2S多
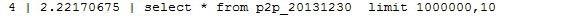
这在程序中肯定是不可忍受的。
对于mysql,优化limit最重要的一点就是尽量先用主键id的索引到起始位置,然后再截取需要的行数。
2、优化方式
(1)使用记录主键的方式进行优化
limit最大的问题在于要扫描前面不必要的数据,所以可以先对主键的条件做设定,然后记录住主键的位置再取行。
- select * from p2p_20131230 where main_id > 1000000 order by main_id limit 10;
这样执行的结果如下所示,比没有优化前提升了很多倍。
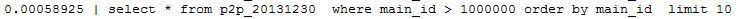
(2)使用子查询进行查询:
- select * from p2p_20131230 where main_id >= (select main_id from p2p_20131230 limit 1000000,1) limit 10;
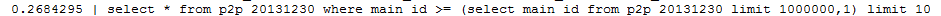
(3) 使用between关键字
如果在主键id是有序不变的情况下,还可以手动计算between的前后两个条件进行查询,这里我就不上代码了。
总结一下,上面的集中方法都是利用mysql的主键索引进行优化,当然应用中通常很难直接获得索引,基本上都是格局where后的某个条件,这个时候就可以先用条件查询出主键id,然后再用上述方式获取结果集即可。
利用表的覆盖索引来加速分页查询
我们都知道,利用了索引查询的语句中如果只包含了那个索引列(覆盖索引),那么这种情况会查询很快。
因为利用索引查找有优化算法,且数据就在查询索引上面,不用再去找相关的数据地址了,这样节省了很多时间。另外Mysql中也有相关的索引缓存,在并发高的时候利用缓存就效果更好了。
在我们的例子中,我们知道id字段是主键,自然就包含了默认的主键索引。现在让我们看看利用覆盖索引的查询效果如何:
这次我们之间查询最后一页的数据(利用覆盖索引,只包含id列),如下:
select id from product limit 866613, 20 0.2秒
相对于查询了所有列的37.44秒,提升了大概100多倍的速度
那么如果我们也要查询所有列,有两种方法,一种是id>=的形式,另一种就是利用join,看下实际情况:
SELECT * FROM product WHERE ID > =(select id from product limit 866613, 1) limit 20
查询时间为0.2秒,简直是一个质的飞跃啊,哈哈
另一种写法
SELECT * FROM product a JOIN (select id from product limit 866613, 20) b ON a.ID = b.id
查询时间也很短,赞!
其实两者用的都是一个原理嘛,所以效果也差不多
mysql分表的3种方法
一,先说一下为什么要分表

当一张的数据达到几百万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了。分表的
目的就在于此,减小数据库的负担,缩短查询时间。 根据个人经验,mysql执行一个sql的过程如下: 1,接收到sql;2,把sql放到排队队列中 ;3,执行sql;4,返回执行结果。 在这个执行过程中最花时间在什么地方呢? 第一,是排队等待的时间, 第二,sql的执行时间。其实这二个是一回事,等待的同时,肯定有sql在执行。所以我们要缩短sql的执行时间。 mysql中有一种机制是表锁定和行锁定,为什么要出现这种机制,是为了保证数据的完整性; 我举个例子来说吧,如果有二个sql都要修改同一张表的同一条数据,这个时候怎么办呢,是不是二个sql都可以同
时修改这条数据呢? 很显然mysql对这种情况的处理是,一种是表锁定(myisam存储引擎),一个是行锁定(innodb存储引擎)。表
锁定表示你们都不能对这张表进行操作,必须等我对表操作完才行。行锁定也一样,别的sql必须等我对这条数据操
作完了,才能对这条数据进行操作.如果数据太多,一次执行的时间太长,等待的时间就越长,这也是我们为什么要分表的原因。
二,分表
1,做mysql集群,例如:利用mysql cluster ,mysql proxy,mysql replication,drdb等等 有人会问mysql集群,根分表有什么关系吗?虽然它不是实际意义上的分表,但是它启到了分表的作用,做集群的
意义是什么呢?为一个数据库减轻负担,说白了就是减少sql排队队列中的sql的数量,举个例子:有10个sql请求
,如果放在一个数据库服务器的排队队列中,他要等很长时间,如果把这10个sql请求,分配到5个数据库服务器的
排队队列中,一个数据库服务器的队列中只有2个,这样等待时间是不是大大的缩短了呢?这已经很明显了。所以我
把它列到了分表的范围以内,我做过一些mysql的集群:
linux mysql proxy 的安装,配置,以及读写分离 mysql replication 互为主从的安装及配置,以及数据同步 优点:扩展性好,没有多个分表后的复杂操作(php代码) 缺点:单个表的数据量还是没有变,一次操作所花的时间还是那么多,硬件开销大。
2,预先估计会出现大数据量并且访问频繁的表,将其分为若干个表
这种预估大差不差的,论坛里面发表帖子的表,时间长了这张表肯定很大,几十万,几百万都有可能。 聊天室里面信
息表,几十个人在一起一聊一个晚上,时间长了,这张表的数据肯定很大。像这样的情况很多。所以这种能预估出来的
大数据量表,我们就事先分出个N个表,这个N是多少,根据实际情况而定。以聊天信息表为例: 我事先建100个这样的表,message_00,message_01,message_02..........message_98,message_99.然
后根据用户的ID来判断这个用户的聊天信息放到哪张表里面,你可以用hash的方式来获得,可以用求余的方式来获得,
方法很多,各人想各人的吧。下面用hash的方法来获得表名: 查看复制打印? <?php function get_hash_table($table,$userid) { $str = crc32($userid); if($str<0){ $hash = "0".substr(abs($str), 0, 1); }else{ $hash = substr($str, 0, 2); } return $table."_".$hash; } echo get_hash_table('message','user18991'); //结果为message_10 echo get_hash_table('message','user34523'); //结果为message_13 ?> 说明一下,上面的这个方法,告诉我们user18991这个用户的消息都记录在message_10这张表里,user34523这个用
户的消息都记录在message_13这张表里,读取的时候,只要从各自的表中读取就行了。 优点:避免一张表出现几百万条数据,缩短了一条sql的执行时间 缺点:当一种规则确定时,打破这条规则会很麻烦,上面的例子中我用的hash算法是crc32,如果我现在不想用这个算
法了,改用md5后,会使同一个用户的消息被存储到不同的表中,这样数据乱套了。扩展性很差。
3,利用merge存储引擎来实现分表
我觉得这种方法比较适合,那些没有事先考虑,而已经出现了得,数据查询慢的情况。这个时候如果要把已有的大
数据量表分开比较痛苦,最痛苦的事就是改代码,因为程序里面的sql语句已经写好了,现在一张表要分成几十张表,
甚至上百张表,这样sql语句是不是要重写呢?举个例子,我很喜欢举子 mysql>show engines;的时候你会发现mrg_myisam其实就是merge。 mysql> CREATE TABLE IF NOT EXISTS `user1` ( -> `id` int(11) NOT NULL AUTO_INCREMENT, -> `name` varchar(50) DEFAULT NULL, -> `sex` int(1) NOT NULL DEFAULT '0', -> PRIMARY KEY (`id`) -> ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ; Query OK, 0 rows affected (0.05 sec) mysql> CREATE TABLE IF NOT EXISTS `user2` ( -> `id` int(11) NOT NULL AUTO_INCREMENT, -> `name` varchar(50) DEFAULT NULL, -> `sex` int(1) NOT NULL DEFAULT '0', -> PRIMARY KEY (`id`) -> ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ; Query OK, 0 rows affected (0.01 sec) mysql> INSERT INTO `user1` (`name`, `sex`) VALUES('张映', 0); Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO `user2` (`name`, `sex`) VALUES('tank', 1); Query OK, 1 row affected (0.00 sec) mysql> CREATE TABLE IF NOT EXISTS `alluser` ( -> `id` int(11) NOT NULL AUTO_INCREMENT, -> `name` varchar(50) DEFAULT NULL, -> `sex` int(1) NOT NULL DEFAULT '0', -> INDEX(id) -> ) TYPE=MERGE UNION=(user1,user2) INSERT_METHOD=LAST AUTO_INCREMENT=1 ; Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> select id,name,sex from alluser; +----+--------+-----+ | id | name | sex | +----+--------+-----+ | 1 | 张映 | 0 | | 1 | tank | 1 | +----+--------+-----+ 2 rows in set (0.00 sec) mysql> INSERT INTO `alluser` (`name`, `sex`) VALUES('tank2', 0); Query OK, 1 row affected (0.00 sec) mysql> select id,name,sex from user2 -> ; +----+-------+-----+ | id | name | sex | +----+-------+-----+ | 1 | tank | 1 | | 2 | tank2 | 0 | +----+-------+-----+ 2 rows in set (0.00 sec) 从上面的操作中,我不知道你有没有发现点什么?假如我有一张用户表user,有50W条数据,现在要拆成二张表user1
和user2,每张表25W条数据, INSERT INTO user1(user1.id,user1.name,user1.sex)SELECT (user.id,user.name,user.sex)FROM
user where user.id <= 250000 INSERT INTO user2(user2.id,user2.name,user2.sex)SELECT (user.id,user.name,user.sex)FROM
user where user.id > 250000 这样我就成功的将一张user表,分成了二个表,这个时候有一个问题,代码中的sql语句怎么办,以前是一张表,现在
变成二张表了,代码改动很大,这样给程序员带来了很大的工作量,有没有好的办法解决这一点呢?办法是把以前的user
表备份一下,然后删除掉,上面的操作中我建立了一个alluser表,只把这个alluser表的表名改成user就行了。但是,
不是所有的mysql操作都能用的 a,如果你使用 alter table 来把 merge 表变为其它表类型,到底层表的映射就被丢失了。取而代之的,来自底层
myisam 表的行被复制到已更换的表中,该表随后被指定新类型。 b,网上看到一些说replace不起作用,我试了一下可以起作用的。晕一个先 mysql> UPDATE alluser SET sex=REPLACE(sex, 0, 1) where id=2; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> select * from alluser; +----+--------+-----+ | id | name | sex | +----+--------+-----+ | 1 | 张映 | 0 | | 1 | tank | 1 | | 2 | tank2 | 1 | +----+--------+-----+ 3 rows in set (0.00 sec) c,一个 merge 表不能在整个表上维持 unique 约束。当你执行一个 insert,数据进入第一个或者最后一个 myisam 表
(取决于 insert_method 选项的值)。mysql 确保唯一键值在那个 myisam 表里保持唯一,但不是跨集合里所有的表。 d,当你创建一个 merge 表之时,没有检查去确保底层表的存在以及有相同的机构。当 merge 表被使用之时,mysql 检查每
个被映射的表的记录长度是否相等,但这并不十分可靠。如果你从不相似的 myisam 表创建一个 merge 表,你非常有可能撞见奇怪的问题。 好困睡觉了,c和d在网上看到的,没有测试,大家试一下吧。 优点:扩展性好,并且程序代码改动的不是很大 缺点:这种方法的效果比第二种要差一点
三,总结一下
上面提到的三种方法,我实际做过二种,第一种和第二种。第三种没有做过,所以说的细一点。哈哈。 做什么事都有一个度,超过个度就过变得很差,不能一味的做数据库服务器集群,硬件是要花钱买的,也不要一味的分表,分出来1000表,
mysql的存储归根到底还以文件的形势存在硬盘上面,一张表对应三个文件,1000个分表就是对应3000个文件,这样检索起来也会变的很慢。
我的建议是 方法1和方法2结合的方式来进行分表 方法1和方法3结合的方式来进行分表 我的二个建议适合不同的情况,根据个人情况而定,我觉得会有很多人选择方法1和方法3结合的方式
mysql教程
1、数据类型
MySQL支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型。
https://www.runoob.com/mysql/mysql-data-types.html
Mysql的int与integer没有区别
int(1)与int(10)区别:
INT(1) 和 INT(10)本身没有区别,但是加上(M)值后,会有显示宽度的设置。
https://www.cnblogs.com/wanghaokun/p/5967663.html
Decimal类型:
https://www.cnblogs.com/owenma/p/7097602.html
日期与时间类型:
java中的localdate,localtime,localdatetime可以用于与MySQL中的日期时间对应。
date java.sql.Date
Datetime java.sql.Timestamp
Timestamp java.sql.Timestamp
Time java.sql.Time
Year java.sql.Date
除了year,所有的日期可以用Date处理。
Date date = new Date(System.currentTimeMillis()); LocalDate localdate = LocalDate.now(); LocalTime localtime = LocalTime.now(); LocalDateTime datetimelocal = LocalDateTime.now(); LocalDateTime dateime2 = datetimelocal.plusYears(50); java.sql.Date sqlDate = java.sql.Date.valueOf(localdate); java.sql.Time times = java.sql.Time.valueOf(localtime); java.sql.Timestamp timestamp = java.sql.Timestamp.valueOf(datetimelocal); String sql = "insert into date_test values (?,?,?,?,?)"; MysqlUtil.insertData(getConnection(), sql, localdate,localtime,localdate.getYear(),dateime2,datetimelocal);
日期和时间类型
表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。
每个时间类型有一个有效值范围和一个"零"值,当指定不合法的MySQL不能表示的值时使用"零"值。
TIMESTAMP类型有专有的自动更新特性,将在后面描述。
| 类型 | 大小 ( bytes) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 |
1970-01-01 00:00:00/2038 结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 |
YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
字符串类型
字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET。该节描述了这些类型如何工作以及如何在查询中使用这些类型。
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串 |
| VARCHAR | 0-65535 bytes | 变长字符串 |
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
注意:char(n) 和 varchar(n) 中括号中 n 代表字符的个数,并不代表字节个数,比如 CHAR(30) 就可以存储 30 个字符。
CHAR 和 VARCHAR 类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
BINARY 和 VARBINARY 类似于 CHAR 和 VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。这说明它们没有字符集,并且排序和比较基于列值字节的数值值。
BLOB 是一个二进制大对象,可以容纳可变数量的数据。有 4 种 BLOB 类型:TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB。它们区别在于可容纳存储范围不同。
有 4 种 TEXT 类型:TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT。对应的这 4 种 BLOB 类型,可存储的最大长度不同,可根据实际情况选择。
MySQL 正则表达式
在前面的章节我们已经了解到MySQL可以通过 LIKE ...% 来进行模糊匹配。
MySQL 同样也支持其他正则表达式的匹配, MySQL中使用 REGEXP 操作符来进行正则表达式匹配。
如果您了解PHP或Perl,那么操作起来就非常简单,因为MySQL的正则表达式匹配与这些脚本的类似。
下表中的正则模式可应用于 REGEXP 操作符中。
| 模式 | 描述 |
|---|---|
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 ' ' 或 ' ' 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 ' ' 或 ' ' 之前的位置。 |
| . | 匹配除 " " 之外的任何单个字符。要匹配包括 ' ' 在内的任何字符,请使用像 '[. ]' 的模式。 |
| [...] | 字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。 |
| [^...] | 负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'。 |
| p1|p2|p3 | 匹配 p1 或 p2 或 p3。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。 |
实例
了解以上的正则需求后,我们就可以根据自己的需求来编写带有正则表达式的SQL语句。以下我们将列出几个小实例(表名:person_tbl )来加深我们的理解:
查找name字段中以'st'为开头的所有数据:
mysql> SELECT name FROM person_tbl WHERE name REGEXP '^st';
查找name字段中以'ok'为结尾的所有数据:
mysql> SELECT name FROM person_tbl WHERE name REGEXP 'ok$';
查找name字段中包含'mar'字符串的所有数据:
mysql> SELECT name FROM person_tbl WHERE name REGEXP 'mar';
查找name字段中以元音字符开头或以'ok'字符串结尾的所有数据:
mysql> SELECT name FROM person_tbl WHERE name REGEXP '^[aeiou]|ok$';
创建索引及唯一索引。
https://www.runoob.com/mysql/mysql-index.html
https://www.runoob.com/mysql/mysql-functions.html
https://blog.csdn.net/weixin_42570248/article/details/89099989
Char与VarChar区别及选择:
https://blog.csdn.net/weixin_42570248/article/details/89786882