1、目录结构:
javaWeb项目完整目录结构如下:

src项目用于java代码,
web目录下包含resources目录,一般用于存放静态资源。
web-inf目录下包含lib及web.xml文件,在web-inf目录下的文件收到保护,只有服务器内部能直接访问。
<welcome-file-list>
<welcome-file>/WEB-INF/jsp/index.jsp</welcome-file>
</welcome-file-list>
可以访问,因为相当于容器进行了映射。
下面也可以映射
<!--欢迎页面-->
<welcome-file-list>
<welcome-file>/index</welcome-file>
</welcome-file-list>
2、jar与WAR包的却别:
https://www.cnblogs.com/qffxj/p/10213458.html
war与war-exploded区别:
https://my.oschina.net/u/3908739/blog/1932623
3、在网页标题中加入图标:
方法一(被动式):
制作一个ico格式的图片,将图片命名为favicon.ico,像素大小为16*16,所使用的颜色不得超过16色,然后再把favicon.ico放到网站的根目录下就行了。这样的话浏览器会不停的搜索您的网站的根目录,只要它一发现了名字叫做favicon.ico 这个文件,就会将该图标显示在访问者的地址栏和收藏夹列表中了。
方法二(自动式):
在网页HEAD标记中添加如下代码:
标题栏:
<link rel="icon" href="ico地址" type="image/x-icon">
收藏夹:
<link rel="shortcut icon" href="ico地址" type="image/x-icon">
注意:图标要用 16*16 色的。。。(保证了兼容性,无论在哪个地方都可以显示)
同时在使用方法二的时候,就不一定要把图形文件放在网站的根目录下面了,你可以放在任何位置,甚至直接连结到其他网站上面的图形文件也可以,而且图形文件的文件 名也不一定要叫做 favicon.ico,可以自己随便取。 不过要注意的是使用这个做法的话,只有在把有加入上面 HTML 语法的页面加入书签的时候才会有作用。
4、javaWeb项目路径访问问题:
4.1相对路径:
在web项目中,若我们在访问路径的最前端不加上“/”,那就是使用相对路径,如下图所示:
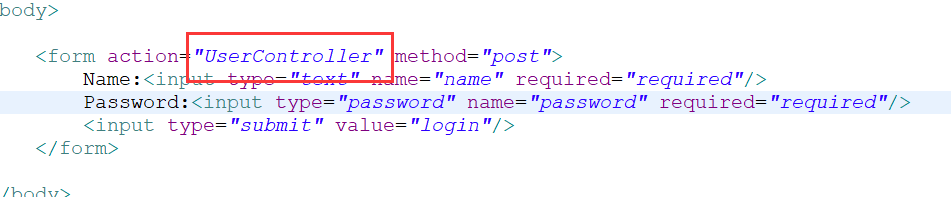
在eclipse的web项目中,前端页面(html,jsp......)的默认起始路径就是WebContent,而java文件的起始路径就是src。假设我们要访问我这个项目中的login2.html,那路径如下图:

可以看到,访问路径是不需要加上WebContent的。同理,若是想要访问servlet这种src下的Java文件,也是直接“IP地址/项目名/servlet”,不需要写上包名。
而相对路径相对的就是当前文件所在的路径的前缀,也就是上图中的http://localhost:8080/Jsp_Lab2/,也就是说,上面的form表单提交数据到UserController这个servlet,那提交路径实际上就是将UserController这个字符串与当前路径的前缀拼接起来,也就是成了http://localhost:8080/Jsp_Lab2/UserController,而这正是我项目中的UserControllerServlet这个servlet的路径。通过浏览器顶端的url显示可以得到验证:

4.2 绝对路径:
绝对路径的使用方式就是在路径的开始加上“/”,若在路径开始处加上了一个“/”,那相对路径前缀就会被“清零”,路径从最初位置开始。
那么,绝对路径的最初位置路径是什么呢?就是服务器的IP地址+端口号,比如在本机访问,那就是http://localhost:8080。也就是说使用绝对地址,那访问所写的路径将会被拼接到http://localhost:8080之后。
使用之前报404的例子来演示,在UserController前加一个‘/’表示表单提交使用绝对路径。如下图所示:
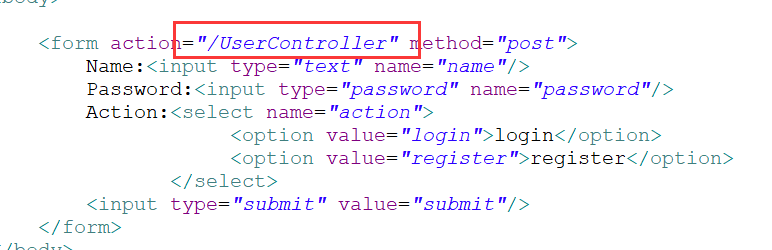
运行之后的路径如图所示:

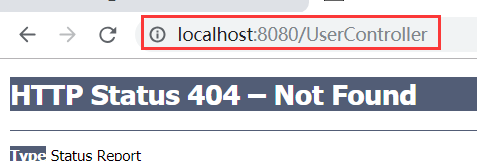
提交表单后,跳转到的页面如下所示:
总结:
1、绝对路径就是在路径开头加“/”,那路径的起始就是服务器IP地址;
2、而相对路径就是开头不加“/”,而起始就是发起跳转的文件的所在路径;
3、服务器端请求转发时,使用的地址表示:http://服务器ip:端口/项目名,重定向时表示:http://服务器ip:端口/,即使用绝对地址时请求转发不加项目名,重定向需要。
重定向是浏览器发来的,只知道发到某个服务器,但是不知道发到服务器的哪个project,所以需要自己用代码声明; 而请求转发是服务器某个 project内部的转发,转来转去都是在某个 project内部,所以不需要手动声明项目名。
https://www.cnblogs.com/tuyang1129/p/10724898.html
url路径匹配优先级规则:
首先需要明确几容易混淆的规则:
- servlet容器中的匹配规则既不是简单的通配,也不是正则表达式,而是特定的规则。所以不要用通配符或者正则表达式的匹配规则来看待servlet的url-pattern。
- Servlet 2.5开始,一个servlet可以使用多个url-pattern规则,<servlet-mapping>标签声明了与该servlet相应的匹配规则,每个<url-pattern>标签代表1个匹配规则;
- 当servlet容器接收到浏览器发起的一个url请求后,容器会用url减去当前应用的上下文路径,以剩余的字符串作为servlet映射,假如url是http://localhost:8080/appDemo/index.html,其应用上下文是appDemo,容器会将http://localhost:8080/appDemo去掉,用剩下的/index.html部分拿来做servlet的映射匹配
- url-pattern映射匹配过程是有优先顺序的
- 而且当有一个servlet匹配成功以后,就不会去理会剩下的servlet了。
四种匹配规则:
1 精确匹配
<url-pattern>中配置的项必须与url完全精确匹配。
<servlet-mapping>
<servlet-name>MyServlet</servlet-name>
<url-pattern>/user/users.html</url-pattern>
<url-pattern>/index.html</url-pattern>
<url-pattern>/user/addUser.action</url-pattern>
</servlet-mapping>
当在浏览器中输入如下几种url时,都会被匹配到该servlet
http://localhost:8080/appDemo/user/users.html
http://localhost:8080/appDemo/index.html
http://localhost:8080/appDemo/user/addUser.action
注意:
http://localhost:8080/appDemo/user/addUser/ 是非法的url,不会被当作http://localhost:8080/appDemo/user/addUser识别
另外上述url后面可以跟任意的查询条件,都会被匹配,如
http://localhost:8080/appDemo/user/addUser?username=Tom&age=23 会被匹配到MyServlet。
2 路径匹配
以“/”字符开头,并以“/*”结尾的字符串用于路径匹配
<servlet-mapping>
<servlet-name>MyServlet</servlet-name>
<url-pattern>/user/*</url-pattern>
</servlet-mapping>
路径以/user/开始,后面的路径可以任意。比如下面的url都会被匹配。
http://localhost:8080/appDemo/user/users.html
http://localhost:8080/appDemo/user/addUser.action
http://localhost:8080/appDemo/user/updateUser.actionl
3 扩展名匹配
以“*.”开头的字符串被用于扩展名匹配
<servlet-mapping>
<servlet-name>MyServlet</servlet-name>
<url-pattern>*.jsp</url-pattern>
<url-pattern>*.action</url-pattern>
</servlet-mapping>
则任何扩展名为jsp或action的url请求都会匹配,比如下面的url都会被匹配
http://localhost:8080/appDemo/user/users.jsp
http://localhost:8080/appDemo/toHome.action
4 缺省匹配
<servlet-mapping>
<servlet-name>MyServlet</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
匹配顺序
- 精确匹配,servlet-mapping1:<url-pattern>/user/users.html</url-pattern>,servlet-mapping2:<url-pattern>/*</url-pattern>。当一个请求http://localhost:8080/appDemo/user/users.html来的时候,servlet-mapping1匹配到,不再用servlet-mapping2匹配
- 路径匹配,先最长路径匹配,再最短路径匹配servlet-mapping1:<url-pattern>/user/*</url-pattern>,servlet-mapping2:<url-pattern>/*</url-pattern>。当一个请求http://localhost:8080/appDemo/user/users.html来的时候,servlet-mapping1匹配到,不再用servlet-mapping2匹配
- 扩展名匹配,servlet-mapping1:<url-pattern>/user/*</url-pattern>,servlet-mapping2:<url-pattern>*.action</url-pattern>。当一个请求http://localhost:8080/appDemo/user/addUser.action来的时候,servlet-mapping1匹配到,不再用servlet-mapping2匹配
- 缺省匹配,以上都找不到servlet,就用默认的servlet,配置为<url-pattern>/</url-pattern>
需要注意的问题
1 路径匹配和扩展名匹配无法同时设置
匹配方法只有三种,要么是路径匹配(以“/”字符开头,并以“/*”结尾),要么是扩展名匹配(以“*.”开头),要么是精确匹配,三种匹配方法不能进行组合,不要想当然使用通配符或正则规则。
如<url-pattern>/user/*.action</url-pattern>是非法的
另外注意:<url-pattern>/aa/*/bb</url-pattern>是精确匹配,合法,这里的*不是通配的含义
2 "/*"和"/"含义并不相同
- “/*”属于路径匹配,并且可以匹配所有request,由于路径匹配的优先级仅次于精确匹配,所以“/*”会覆盖所有的扩展名匹配,很多404错误均由此引起,所以这是一种特别恶劣的匹配模式,一般只用于filter的url-pattern
- “/”是servlet中特殊的匹配模式,切该模式有且仅有一个实例,优先级最低,不会覆盖其他任何url-pattern,只是会替换servlet容器的内建default servlet ,该模式同样会匹配所有request。
- 配置“/”后,一种可能的现象是myServlet会拦截诸如http://localhost:8080/appDemo/user/addUser.action、http://localhost:8080/appDemo/user/updateUser的格式的请求,但是并不会拦截http://localhost:8080/appDemo/user/users.jsp、http://localhost:8080/appDemo/index.jsp,这是应为servlet容器有内置的“*.jsp”匹配器,而扩展名匹配的优先级高于缺省匹配,所以才会有上述现象。
Tomcat在%CATALINA_HOME%confweb.xml文件中配置了默认的Servlet,配置代码如下
https://www.cnblogs.com/whyat/p/10512191.html
jsp中动态路径的使用:
String path = request.getContextPath(); String basePath = request.getScheme()+"://"+request.getServerName()+":"+request.getServerPort()+path+"/"; <base href="<%=basePath%>">
在程序中我们一般这样使用。说到了这里,我们可以看看request常用的方法:
request.getSchema(),返回的是当前连接使用的协议,一般应用返回的是http、SSL返回的是https;
request.getServerName(),返回当前页面所在的服务器的名字;
request.getServerPort(),返回当前页面所在的服务器使用的端口,80;
request.getContextPath(),返回当前页面所在的应用的名字。
<base href="<%=basePath%>/"/> basePath后需加/表明是目录,不然base标签不起作用。
5、模态框与编辑器的冲突
// 将全屏时z-index修改为20000 editor.config.zindex = 20000;
z-index为网页元素显示层级,值越大显示越靠前。
以wangEditor为例,默认为10000,可以改小以使得模态框显示。
要使div中的内容居中显示,不仅div要设定“text-align:centr" ,内置对象要添加margin:auto;属性才能使其在firefox等其他浏览器中也能居中。
HTML是有执行顺序的,默认是自上而下执行。所以当我们的js代码在html代码下边的时候,可以正常执行,而当我们的js代码在html代码上边的时候,
可以就无法正常执行了,这时,我们需要在文档加载完毕的时候才去执行js代码,所以通常我们会这样做:
<c:if test="${requestScope.blogs.size() > 3}">
{}大括号到“间不能有空格,不然jstl不能识别。
6、中文乱码问题。
6.1 respone响应乱码:
原因
由于浏览器默认使用UTF-8码表进行编码,而servlet使用ISO-8859-1码表进行编码,传输和接收方编码不一致导致乱码的产生。
response乱码
|
01
02
03
|
response.setHeader("content-type", "text/html;charset=UTF-8");response.setCharacterEncoding("UTF-8"); |
第一句目的是为了指定浏览器以UTF-8码表打开服务器发出的数据
第二句目的是设置response使用的码表,控制response以UTF-8码表向浏览器写入数据(必须写在方法中第一行)
6.2 request请求乱码:
get:
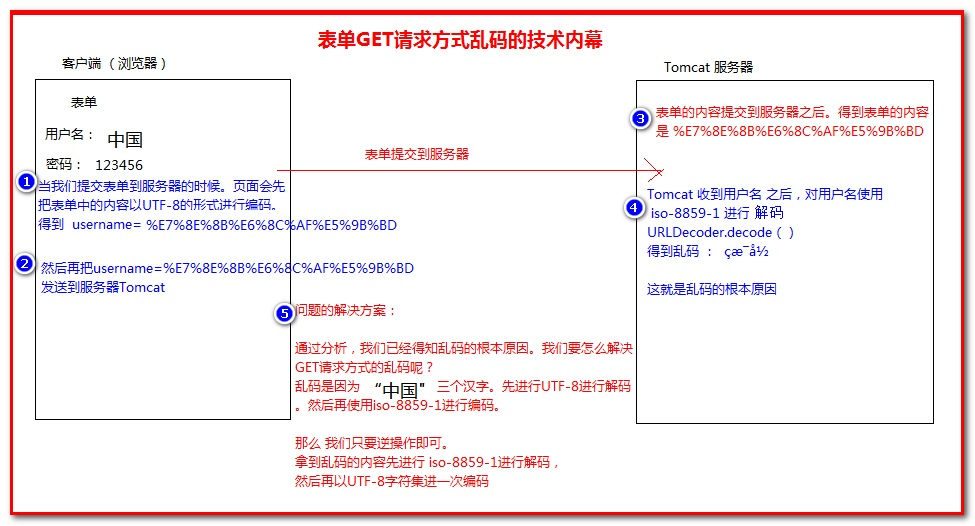
解决乱码的核心代码:
解决乱码的核心思路,就是把得到的乱码按照原来乱码的步骤逆序操作。
1、先以iso-8895-1进行解码
2、然后再以utf-8进行编码
1) 第一种方式 使用URLEncoder 和 URLDecoder 两个类 编解码
//获取客户端传递过来的用户名参数值 String username = request.getParameter("username"); System.out.println("用户名:" + username); // 先对用户名进行解码得到%E7%8E%8B%E6%8C%AF%E5%9B%BD 这样的形式 username = URLEncoder.encode(username, "ISO-8859-1"); // 再进行utf-8编码 一次得到页面上输入的文本内容 username = URLDecoder.decode(username, "UTF-8"); System.out.println("乱码解决后用户名:" + username);
第二种方式 使用 String类的方法进行编解码
username = new String(username.getBytes("ISO-8859-1"), "UTF-8");
System.out.println("乱码解决后用户名:" + username);post:
因为post是以二进制流的形式发送到的服务器。服务器收到数据后。
默认以iso-8859-1进行编码。
POST请求乱码解决,只需要在获取请求参数之前调用
request.setCharacterEncoding(“UTF-8”); 方法设置字符集 即可。
全局编码过滤时放行静态文件,不然wangEditor乱码。()
8、servlet图片上传问题
首先需要明白的一点是:我们在工作空间新建一个web项目,图片上传究竟要上传到哪里去哪?这里我们要明白一点,图片是被上传到服务器上的,也就是tomcat服务器(假设您用的是tomcat)上的,比如:您的项目名是demo,您指定上传的图片路径如下:
String basePath = request.getRealPath("/images"); File file = new File(basePath, fileName)
这个路径被指定后,图片可不是被上传到workspace/demo/images下,而是apache tomcat/webapps/demo/images下,所以当您重新部署项目会造成原来上传的图片消失的情况。
9、mysql 不能select 出表中的值再update这个表。
可以增加一层嵌套或临时保存数据。
10、文件上传技术:
使用fileupload及commons-io包。
10.1 前端页面处理:
上传类型添加 mutlipart。
wangEditor与bootstrap文件上传模块只需添加地址即可,请求类型已经设定完成。
$("#exampleFormControlFile").fileinput({ language: 'zh', uploadUrl: "headerpic", //上传的地址 allowedFileExtensions : ['jpg', 'png','gif','jpeg'],//接收的文件后缀 showUpload: true, //是否显示上传按钮 showCaption: true,//是否显示标题 browseClass: "btn btn-primary", //按钮样式 dropZoneEnabled: false,//是否显示拖拽区域 maxImageWidth: 1000,//图片的最大宽度 maxImageHeight: 1000,//图片的最大高度 maxFileSize: 10240,//单位为kb,如果为0表示不限制文件大小 });
//bootstrap
editor.config.uploadImgServer = 'image'
//wangEditor
10.2 后端处理:使用servletFileUpload类对请求内容解析,当非普通表单数据时,获取到输入流,可以将该输入流传入数据库,或写入映射文件,写入本地映射文件后应该向前端放回路径,以便访问。
DiskFileItemFactory factory = new DiskFileItemFactory(); ServletFileUpload upload = new ServletFileUpload(factory); ImageUpload imageUpload = new ImageUpload(); List<String> picUrl = new ArrayList<>(); List items = null; try { items = upload.parseRequest(request); } catch (FileUploadException e) { e.printStackTrace(); } Iterator iter = items.iterator(); while(iter.hasNext()){ FileItem item = (FileItem) iter.next(); /*必须为非普通表单数据*/ if(!item.isFormField()){ logger.info("获取到文件名:"+item.getName()); String originalName = item.getName(); String[] lists = originalName.split("\."); //新名字 String newName = UUID.randomUUID()+"."+lists[lists.length-1]; logger.info("新名字为:"+newName); filename = System.currentTimeMillis() + ".jpg"; File localUrlAddr = new File(localUrl+"/"+lists[lists.length-1]); if(!localUrlAddr.exists()){ localUrlAddr.mkdirs(); } String finalUrl = localUrlAddr +"/"+newName; String fianlMappedUrl = mappedUrl + "/"+lists[lists.length-1]+"/"+newName; InputStream is = item.getInputStream(); FileOutputStream fos = new FileOutputStream(finalUrl); byte[] b = new byte[1024]; int length = 0; while (-1 != (length = is.read(b))) { fos.write(b, 0, length); } fos.flush(); fos.close(); imageUpload.setErrno(0); picUrl.add(fianlMappedUrl); } } imageUpload.setData(picUrl); Gson gson = new Gson(); String json = gson.toJson(imageUpload); response.getWriter().write(json);
11、表单校验:
前端校验:
使用bootstrap的校验失败提示。使用html的attern校验。
pattern中的正则表达式进行验证输入内容。
当某一类上有“was-validated时,bootstrap会显示校验结果,提示成功或失败信息;一般用于前端校验。
或者给输入元素添加is-invalid/is-valid类,会直接变为无效/有效,一般用于后端校验
obj[0].checkValidity()可用于检测pattern校验的结果,obj为校验的元素,需要第一个dom才能获得状态!
<div class="form-group row" id="validateUserName"> <label for="inputUserName" class="col-sm-2 col-form-label">用户名</label> <div class="col-sm-10"> <input type="text" class="form-control" id="inputUserName" placeholder="请输入用户名" name="userName" pattern="[A-Za-z0-9u4e00-u9fa5]{2,50}" required onkeyup="validateUserName($(this))"
onblur="validateUserName($(this))"> <div class="invalid-feedback"><small>用户名应为2-50位字母或数字或中文!</small></div> </div> </div>
JS操作
if(!obj[0].checkValidity()){ obj.siblings(".invalid-feedback").text("用户名应为2-50位字母或数字或中文!"); obj.removeClass("is-invalid"); obj.parent().addClass("was-validated"); }else{ $.ajax({ type: "GET", url: "namevalidate?userName="+obj.val(), success: function (result) { if(result == "yes"){ obj.siblings(".invalid-feedback").text("用户名应为2-50位字母或数字或中文!"); obj.removeClass("is-invalid"); obj.parent().addClass("was-validated"); }else{ obj.parent().removeClass("was-validated"); obj.siblings(".invalid-feedback").text("用户名已经被占用了!"); obj.addClass("is-invalid"); } } }); }
后端校验:
前端校验成功后,发Ajax请求查询用户名是否被占用。
12、javaweb Filter
过滤器实际上就是对web资源进行拦截,做一些处理后再交给下一个过滤器或servlet处理
通常都是用来拦截request进行处理的,也可以对返回的response进行拦截处理
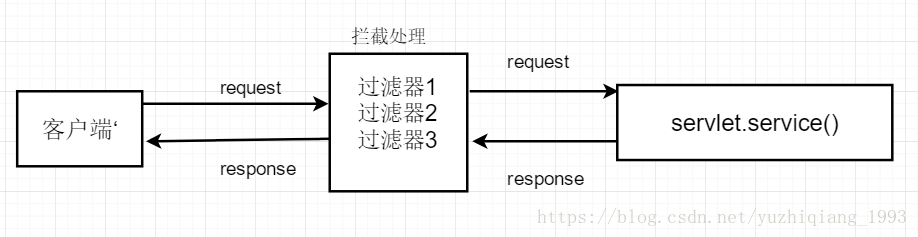
应用场景
自动登录
统一设置编码格式
访问权限控制
敏感字符过滤等
创建Filter
在Servlet中我们一般都会对request和response中的字符集编码进行配置,如果Servlet过多字符集编码发生变化时修改起码会很麻烦,这些通用的字符集编码配置等工作我们可以放到Filter中来实现。
下面我们来创建一个处理字符集编码的Filter。
@WebFilter(filterName = "CharsetFilter") public class CharsetFilter implements Filter { public void destroy() { /*销毁时调用*/ } public void doFilter(ServletRequest req, ServletResponse resp, FilterChain chain) throws ServletException, IOException { /*过滤方法 主要是对request和response进行一些处理,然后交给下一个过滤器或Servlet处理*/ chain.doFilter(req, resp);//交给下一个过滤器或servlet处理 } public void init(FilterConfig config) throws ServletException { /*初始化方法 接收一个FilterConfig类型的参数 该参数是对Filter的一些配置*/ } }
配置Filter
可配置的属性有这些
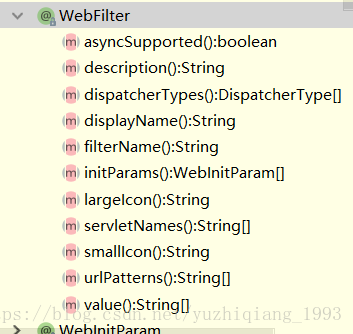
常用配置项
urlPatterns
配置要拦截的资源
- 以指定资源匹配。例如
"/index.jsp" - 以目录匹配。例如
"/servlet/*" - 以后缀名匹配,例如
"*.jsp" - 通配符,拦截所有web资源。
"/*"
**initParams **
配置初始化参数,跟Servlet配置一样
例如
initParams = { @WebInitParam(name = "key",value = "value") }
dispatcherTypes **
配置拦截的类型,可配置多个。默认为DispatcherType.REQUEST**
例如
dispatcherTypes = {DispatcherType.ASYNC,DispatcherType.ERROR}其中DispatcherType是个枚举类型,有下面几个值
FORWARD,//转发的 INCLUDE,//包含在页面的 REQUEST,//请求的 ASYNC,//异步的 ERROR;//出错的
需要注意的是
过滤器是在服务器启动时就会创建的,只会创建一个实例,常驻内存,也就是说服务器一启动就会执行Filter的init(FilterConfig config)方法.
当Filter被移除或服务器正常关闭时,会执行destroy方法
Servlet的Load-on-start:filter没有
1、load-on-startup 标签作用:用来控制容器启动时,是否加载Servlet。
多个Filter的执行顺序
在我们的请求到达Servle之间是可以经过多个Filter的,一般来说,建议Filter之间不要有关联,各自处理各自的逻辑即可。这样,我们也无需关心执行顺序问题。
如果一定要确保执行顺序,就要对配置进行修改了,执行顺序如下
- 在web.xml中,filter执行顺序跟
<filter-mapping>的顺序有关,先声明的先执行 - 使用注解配置的话,filter的执行顺序跟名称的字母顺序有关,例如AFilter会比BFilter先执行
- 如果既有在web.xml中声明的Filter,也有通过注解配置的Filter,那么会优先执行web.xml中配置的Filter
13、javaweb listener
1.Listener
1.1Listener的概述
1.1.1什么是Listener
监听器就是一个Java类(狗仔)用来监听其他的JavaBean的变化
在javaweb中监听器就是监听三个域对象的状态的。request,session,servletContext
1.1.2监听器的应用
主要在Swing编程.
在Android大量应用
1.1.3监听器的术语
一个狗仔偷拍明星出轨
事件源 :被监听的对象.(目标对象) 明星
监听器对象:监听的对象. 狗仔
注册(绑定):将"监听器"对象注册给"事件源". 当事件源发生某些行为,监听对象将被执行 在偷拍明星楼下蹲点
事件:事件源行为的称呼. 出轨1.2javaweb的监听器
javaweb的监听器:监听ServletContext,HttpSession,ServletRequest三个域对象状态
事件源和监听器绑定的过程:通过配置web.xml完成
Servlet中提供了8个监听器
- 一类:监听三个域对象的创建和销毁的监听器
| 对象类型 | 对应的监听器 |
|---|---|
| ServletContext | ServletContextListener |
| HttpSession | HttpSessionListener |
| HttpServletRequest | ServletRequestListener |
- 二类:监听三个域对象的属性变更的监听器.(属性添加,属性移除,属性替换)
对象类型 对应的监听器 ServletContext ServletContextAttributeListener HttpServletRequest ServletRequestAttributeListener HttpSession HttpSessionAttributeListener
- 三类:监听HttpSession对象中的JavaBean的状态的改变.(绑定,解除绑定,钝化和活化)2个
| 对象类型 | 对应的监听器 |
|---|---|
| HttpSession | HttpSessionBindingListener(绑定,解除绑定) |
| HttpSession | HttpSessionActivationListener(钝化和活化) |
编写步骤:
1.编写一个类
实现监听器接口
重写方法
2.编写配置文件(大部分需要)
注册listener
1.3一类监听器:监听三个域对象的创建和销毁的监听器
1.3.1ServletContextListener
监听ServletContext对象的创建和销毁
ServletContext对象何时创建和销毁:应用在,它就在
创建:服务器启动时候,服务器可以为每个WEB应用创建一个单独的ServletContext.
销毁:服务器关闭的时候,或者项目从服务器中移除.企业中应用
初始化工作.
加载配置文件:Spring框架,ContextLoaderListener
1.3.2HttpSessionListener
监听HttpSession对象的创建和销毁
HttpSession对象何时创建和销毁的:
创建:服务器第一次访问Servlet时,调用getSession()方法的时候. 如果访问的是jsp则直接创建。
销毁:session过期了(默认30分钟)
session.invalidate()手动销毁
非正常关闭服务器(正常关闭序列化到硬盘)1.3.3ServletRequestListener
监听request对象的创建和销毁
问题
ServletRequest对象何时创建和销毁
创建:客户端向服务器发送请求的时候
销毁:服务器为这次请求作出了响应时候https://blog.csdn.net/chendengcd/article/details/74856840
14、cookie与session实现免登录
很多同学学习cookie不看路径(可选),但是你要知道下面四个坑
1、服务器端每次访问的cookie是每次请求头中发送给服务器端的
2、客户端每次请求只发送当前路径下和“直系”关系的父路径的cookie(父路径的页面是不能访问子路径和兄弟路径的cookie的)
3、setcookie如果不设置路径,默认为当前页面的路径,父亲路径的页面是无法访问的
4"/"这个根路径可以在任何路径下访问,求简单可以把cookie都放在这里。
5、当携带cookie访问时,没有路径
https://blog.csdn.net/a754895/article/details/82632747
15、并发问题
https://blog.csdn.net/qq_33535433/article/details/78992353
javaWEB中一般不需要特殊考虑,servlet虽然为单例,但只要不定义类变量则不会有线程安全问题。
Session的实现原理:
服务器创建session出来后,会把session的id号,以cookie的形式回写给客户机,这样,只要客户机的浏览器不关,再去访问服务器时,都会带着session的id号去,服务器发现客户机浏览器带session id过来了,就会使用内存中与之对应的session为之服务。
注:在自己开发过程中同一浏览器登录不同的用户时,session会被覆盖,但是不同浏览器登录就不会被覆盖原因是sessionId不同。
https://blog.csdn.net/shadowcw/article/details/84823545
JDBC事务
在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务!
事务特性
- 事务的原子性( Atomicity):一组事务,要么成功;要么撤回。
- 一致性 (Consistency):事务执行后,数据库状态与其他业务规则保持一致。如转账业务,无论事务执行成功否,参与转账的两个账号余额之和应该是不变的。
- 隔离性(Isolation):事务独立运行。即多个事务之间的隔离特性,可配置。一个事务处理后的结果,影响了其他事务,那么其他事务会撤回。事务的100%隔离,需要牺牲速度。
- 持久性(Durability):事务一旦提交就持久化至硬盘。软、硬件崩溃后,InnoDB数据表驱动会利用日志文件重构修改。可靠性和高速度不可兼得, innodb_flush_log_at_trx_commit 选项 决定什么时候吧事务保存到日志里。
事务隔离级别:
serilizeble:最高级别。不会出现问题,速率很慢。(锁表)
repletable-read:有虚读(幻读)出现。mysql默认隔离级别。(应该是会锁住行。)查找数据时上一次查找的值不会变,但可能多出几行。
read-commited:有不可重复读出现。读另一个事务已提交的数据,如果另一个事务改了某一个值,会导致该值在两次读取不一致。主要是针对行的。
read-uncommited,有脏读出现。读另一个事务未提交的数据。
事务传播特性(spring):
Statement:
PrepareStatement:
callableStatement:
- Statement继承自Wrapper
- PreparedStatement继承自Statement
- CallableStatement继承自PreparedStatement
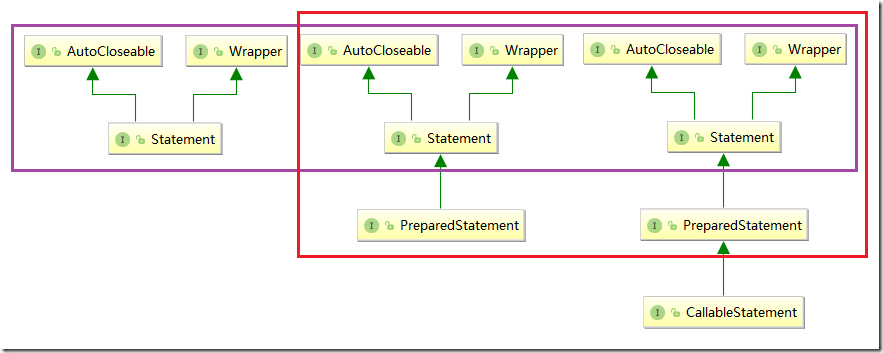
- Statement接口提供了执行语句和获取结果的基本方法;
- PreparedStatement接口添加了处理输入参数的方法;
- CallableStatement接口添加了调用存储过程核函数以及处理输出参数的方法。
使用PreparedStatement能够预防SQL注入攻击
- executeQuery
- executeUpdate
- execute
- Batch
statement操作:
Batch
execute结果处理
键值返回
超时设置
数据返回检索
CallableStatement详解
1、什么是视图:
视图是一种虚拟存在的表,对于使用视图的用户来说基本上是透明的。视图并不在数据库中实际存在,行和列数据来自定义视图的查询中使用的表,并且是在使用视图时动态生产的。
2、视图相对于普通的表的优势主要包括以下几项:
a、简单:使用视图的用户完全不需要关系后面对于的表的结构、关联条件和筛选条件,对用户来说已经是过滤好的复合条件的结果集;
b、安全:使用视图的用户只能访问他们被允许查询的结果集,对表的权限管理并不能限制到某个行某个列,但是通过视图就可以简单地实现;
c、数据独立:一旦视图的结构确定了,可以屏蔽表结构变化对用户对影响,源表增加列对视图没有影响;源表修改列名,则可以通过修改视图来解决,不会造成对访问者对影响。
创建语法例子:
CREATE OR REPLACE VIEW `area_list_view` AS
SELECT d.id as did,d.`address`,d.area_id,a.id as aid,a.`name` FROM address d,area a WHERE d.area_id = a.id;
https://www.cnblogs.com/noteless/p/10307273.html
函数:
https://www.cnblogs.com/qdhxhz/p/10825538.html
16、全站查询
查询是对数据库内容的查询。主要有几种方式:
16.1 数据库的模糊查询,使用like:
select * from table where col like %??%;
该方式查询较慢,不能使用索引。
16.2 使用mysql自带的全文索引
Mysql全文索引的使用
前言
在MySQL 5.6版本以前,只有MyISAM存储引擎支持全文引擎.在5.6版本中,InnoDB加入了对全文索引的支持,但是不支持中文全文索引.在5.7.6版本,MySQL内置了ngram全文解析器,用来支持亚洲语种的分词.
在学习之前,请确认自己的MySQL版本大于5.7.6.我的版本为5.7.20.同时文中的所有操作都基于InnoDB存储引擎.
什么是全文索引?
如果有搞过lucene,solr,es之类的,理解起来会方便许多.
日常我们使用MySQL查询时,大部分的查询都是定值或者范围查询.类似于下面这样:
select *
from table
where id = 1
select *
from table
where id > 20
但是当在MySQL中存储了文本,比如某个字段的值为坚决贯彻党的十八大精神,我们想用贯彻和十八大作为关键字时都可以搜索到这条记录.那么只能使用like关键字.而对于like我们知道,当不是用左边前缀搜索的时候,无法命中索引,因此对于这条语句select * from articles where content like '%贯彻%',MySQL只能进行全表扫描,逐一进行匹配.这样的效率极其低下.
而全文索引呢,通过建立倒排索引,可以极大的提升检索效率.
倒排索引(英语:Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。
对于倒排索引,这里不再展开,有兴趣的朋友可以自行了解一下.
目前,MySQL仅可以在char,varchar,text属性的列上建立全文索引.
如何创建全文索引?
创建全文索引的时机与创建其他类型的索引没什么不同,可以在建表时候创建,也可以通过alter语句创建.这里贴一下建表的同时建立全文索引.
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR (200),
body TEXT,
FULLTEXT (title, body) WITH PARSER ngram
) ENGINE = INNODB DEFAULT CHARSET=utf8mb4 COMMENT='文章表';
上述语句建立了一个article表,且对其中的title和body字段建立了全文索引.
使用alter语句建立索引示例如下:
ALTER TABLE articles ADD FULLTEXT INDEX title_body_index (title,body) WITH PARSER ngram;
如何使用全文索引进行搜索?
MySQL的全文索引查询有多种模式,我们一般经常使用两种.
1. 自然语言搜索
就是普通的包含关键词的搜索.
2. BOOLEAN MODE
这个模式和lucene中的BooleanQuery很像,可以通过一些操作符,来指定搜索词在结果中的包含情况.比如 +嘻哈表示必须包含嘻哈, -嘻哈表示必须不包含,默认为误操作符,代表可以出现可以不出现,但是出现时在查询结果集中的排名较高一些.也就是该结果和搜索词的相关性高一些.
具体包含的所有操作符可以通过MySQL查询来查看:
mysql> show variables like '%ft_boolean_syntax%';
+-------------------+----------------+
| Variable_name | Value |
+-------------------+----------------+
| ft_boolean_syntax | + -><()~*:""&| |
+-------------------+----------------+
1 row in set (0.05 sec)
使用自然语言搜索如下:
mysql> SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('精神' IN NATURAL LANGUAGE MODE);
+----+-----------------+-------------------------+
| id | title | body |
+----+-----------------+-------------------------+
| 1 | 弘扬正能量 | 贯彻党的18大精神 |
+----+-----------------+-------------------------+
1 row in set (0.00 sec)
mysql> SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('精神');
+----+-----------------+-------------------------+
| id | title | body |
+----+-----------------+-------------------------+
| 1 | 弘扬正能量 | 贯彻党的18大精神 |
+----+-----------------+-------------------------+
1 row in set (0.00 sec)
可以看到,搜索结果命中了一条,且在不指定搜索模式的情况下,默认模式为自然语言搜索.
使用boolean搜索如下:
mysql> SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('+精神' IN BOOLEAN MODE);
+----+-----------------+-------------------------+
| id | title | body |
+----+-----------------+-------------------------+
| 1 | 弘扬正能量 | 贯彻党的18大精神 |
+----+-----------------+-------------------------+
1 row in set (0.00 sec)
mysql> SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('+精神 -贯彻' IN BOOLEAN MODE);
Empty set (0.01 sec)
当搜索必须命中精神时,命中了一条数据,当在加上不能包含贯彻的时候,无命中结果.
总结
InnoDB支持全文索引,当然是个好消息,在一些小的全文搜索场景下,可以只使用关系型数据库就搞定了.
他的效率比起like当然是高了不少,但是我没有测试过在千万级数据量下的搜索效率,因为搞出千万级的测试数据是在是太麻烦了.不过我想在大数据量的情景下表现应该不是很好.
对于全文索引的需求,如果只是很小的数据量,且对搜索结果的精确度和可定制化程度要求不高的话,可以使用MySQL的全文索引,如果是专门的做搜索,对搜索中的分词以及结果都有较高的要求,建议还是使用lucene,es相关的哪一套全文搜索工具包来做.
mysql索引讲解:、
https://www.cnblogs.com/xiaoliwang/p/8887873.html
注意事项:
ALTER TABLE blog ADD FULLTEXT INDEX fullContentIndex (blogTitle,blogContent) WITH PARSER ngram;
innoDB使用ngram插件实现中文索引,需要加上WITH PARSER ngram。不然搜索不到中文。
ngram使用教程:
https://www.jianshu.com/p/c48106149b6a/
聚集索引,非聚集索引?
需实现的技术:
1、图片直接上传至数据库;完成? 文件上传进度监控?
2、全局的拦截器观察是否登录,全局编码过滤;完成
3、用户信息校验,主要是用户注册时;完成
4、使用cookie实现免登录; ?完成 jkblog与jkblog/有何区别
5、阅读数,评论功能;完成。
6、线程安全与事务管理;完成
7、全文索引;完成。ealasticserach。
8、页脚;完成?怎么让页脚固定再页面下方?
9、用户互相关注;
10、