所有算法都要达到纸上手写运行无误。
一 排序(冒泡 & 选择 & 快排)
我们通常所说的排序算法往往指的是内部排序算法,即数据记录在内存中进行排序。
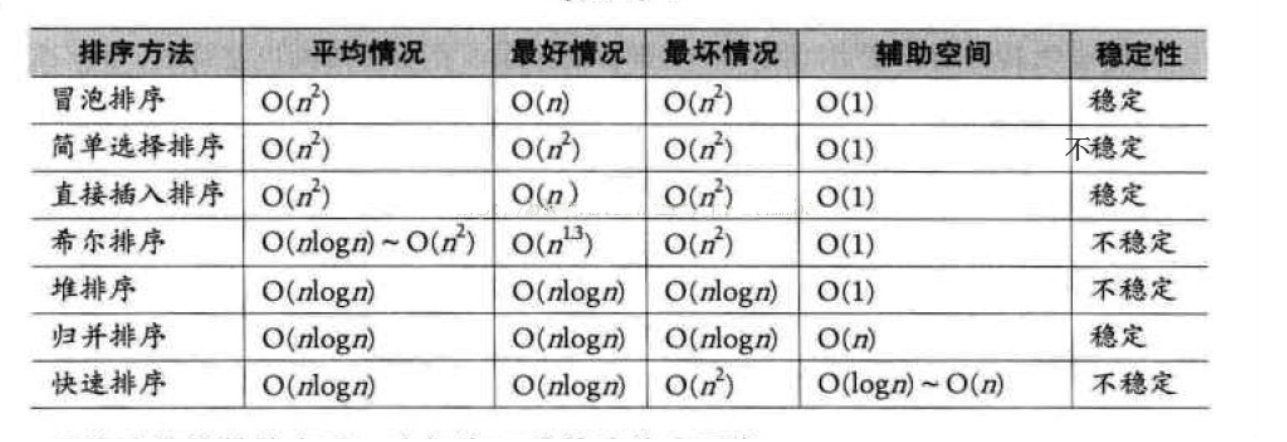
一种是比较排序,时间复杂度O(nlogn) ~ O(n^2),主要有冒泡排序,选择排序,归并排序,堆排序,快速排序等
另一种是非比较排序,时间复杂度可以达到O(n),主要有: 计数排序,基数排序,桶排序等
⚠️注意: 排序算法是否为稳定是由具体的算法实现决定的,不稳定的算法在某种条件下可以变为稳定的算法,稳定的算法在某种条件下可以变为不稳定的算法。
如下面demo中的选择排序就是稳定的。(改变line63为小于等于即为不稳定的)
(1)冒泡 & 选择
1 public class Test1120 { 2 3 public static void main(String[] args) { 4 5 int array[] = new int[]{3, 2, 1, 8, 9, 6, 7}; 6 7 selectSort(array); 8 for (int element : array) { 9 System.out.print(element + " "); 10 } 11 } 12 13 private static void swap(int array[], int left, int right) { 14 int tmp = array[left]; 15 array[left] = array[right]; 16 array[right] = tmp; 17 } 18 19 /** 20 * 逆序的冒泡 21 * 22 * @param array 数组 23 */ 24 private static void bubbleSort(int array[]) { 25 for (int i = 0; i < array.length; i++) { 26 for (int j = array.length - 1; j > i; j--) { 27 if (array[j] < array[j - 1]) { 28 swap(array, j, j - 1); 29 } 30 } 31 } 32 } 33 34 /** 35 * 优化版的冒泡 如果某次遍历没有一个元素进行了交换,那么认为之后的均有序,提前剪枝 36 * 37 * @param array 数组 38 */ 39 private static void bubbleSortV2(int array[]) { 40 boolean flag = true; 41 for (int i = 0; i < array.length && flag; i++) { 42 flag = false; 43 for (int j = array.length - 1; j > i; j--) { 44 if (array[j] < array[j - 1]) { 45 swap(array, j, j - 1); 46 flag = true; 47 } 48 } 49 } 50 } 51 52 /** 53 * 选择排序 54 * 55 * @param array 数组 56 */ 57 private static void selectSort(int array[]) { 58 //选择排序 59 int min; 60 for (int i = 0; i < array.length - 1; i++) { 61 min = i; 62 for (int j = i + 1; j < array.length; j++) { 63 if (array[j] < array[min]) { 64 min = j; 65 } 66 } 67 if (min != i) { 68 swap(array, min, i); 69 } 70 } 71 } 72 }
运行结果:
1 2 3 6 7 8 9
(2) 快排
public class ZZTest1 { public static void main(String[] args) { int[] list = {34, 3, 53, 2, 23, 7, 14, 10, 10, 10}; quick(list); for (int element : list) { System.out.print(element + " "); } System.out.println(); } private static int getMiddle(int[] list, int low, int high) { int tmp = list[low]; //数组的第一个作为中轴 while (low < high) { while (low < high && list[high] >= tmp) { high--; } list[low] = list[high]; //比中轴小的记录移到低端 while (low < high && list[low] <= tmp) { low++; } list[high] = list[low]; //比中轴大的记录移到高端 } list[low] = tmp; //中轴记录到尾 return low; //返回中轴的位置 } private static void _quickSort(int[] list, int low, int high) { if (low < high) { int middle = getMiddle(list, low, high); //将list数组进行一分为二 _quickSort(list, low, middle - 1); //对低字表进行递归排序 _quickSort(list, middle + 1, high); //对高字表进行递归排序 } } private static void quick(int[] list) { if (list.length > 0) { //查看数组是否为空 _quickSort(list, 0, list.length - 1); } } }
运行结果:
2 3 7 10 10 10 14 23 34 53
二 二分查找
1 public class Test1120 { 2 3 public static void main(String[] args) { 4 int array[] = new int[]{1, 3, 5, 7, 9, 11, 13, 15, 17, 19}; 5 int number1 = 11; 6 int number2 = 14; 7 int result1 = binarySearch(array, number1); 8 int result2 = binarySearch(array, number2); 9 System.out.println(result1); 10 System.out.println(result2); 11 } 12 13 private static int binarySearch(int array[], int num) { 14 int l, r, mid; 15 l = 0; 16 r = array.length - 1; 17 int res = -1; 18 19 while (l <= r) { 20 21 mid = (l + r) / 2; 22 if (array[mid] > num) r = mid - 1; 23 else if (array[mid] < num) l = mid + 1; 24 else return mid + 1; 25 } 26 return res; 27 } 28 }
运行结果:
6
-1
三 单链表反转(递归 & 非递归)
1 public class Test1 { 2 public static void main(String[] args) { 3 Node head = new Node(0); 4 Node node1 = new Node(1); 5 Node node2 = new Node(2); 6 Node node3 = new Node(3); 7 head.setNext(node1); 8 node1.setNext(node2); 9 node2.setNext(node3); 10 11 // 打印反转前的链表 12 Node h = head; 13 while (null != h) { 14 System.out.print(h.getData() + " "); 15 h = h.getNext(); 16 } 17 // 调用反转方法 18 // head = reverse1(head); 19 head = reverse2(head); 20 21 System.out.println(" **************************"); 22 // 打印反转后的结果 23 while (null != head) { 24 System.out.print(head.getData() + " "); 25 head = head.getNext(); 26 } 27 } 28 29 /** 30 * 递归,在反转当前节点之前先反转后续节点 31 */ 32 private static Node reverse1(Node head) { 33 // head看作是前一结点,head.getNext()是当前结点,reHead是反转后新链表的头结点 34 if (head == null || head.getNext() == null) { 35 return head;// 若为空链或者当前结点在尾结点,则直接还回 36 } 37 Node reHead = reverse1(head.getNext());// 先反转后续节点head.getNext() 38 head.getNext().setNext(head);// 将当前结点的指针域指向前一结点 39 head.setNext(null);// 前一结点的指针域令为null; 40 return reHead;// 反转后新链表的头结点 41 } 42 43 44 /** 45 * 遍历,将当前节点的下一个节点缓存后更改当前节点指针 46 */ 47 private static Node reverse2(Node head) { 48 if (head == null) { 49 return null; 50 } 51 Node pre = head;// 上一结点 52 Node cur = head.getNext();// 当前结点 53 Node tmp;// 临时结点,用于保存当前结点的指针域(即下一结点) 54 while (cur != null) {// 当前结点为null,说明位于尾结点 55 tmp = cur.getNext(); 56 cur.setNext(pre);// 反转指针域的指向 57 58 // 指针往下移动 59 pre = cur; 60 cur = tmp; 61 } 62 // 最后将原链表的头节点的指针域置为null,还回新链表的头结点,即原链表的尾结点 63 head.setNext(null); 64 65 return pre; 66 } 67 } 68 69 class Node { 70 private int data; 71 private Node next; 72 73 public Node(int Data) { 74 this.data = Data; 75 } 76 77 public int getData() { 78 return data; 79 } 80 81 public void setData(int Data) { 82 this.data = Data; 83 } 84 85 public Node getNext() { 86 return next; 87 } 88 89 public void setNext(Node Next) { 90 this.next = Next; 91 } 92 }
四 单链表是否成环
1 class Node { 2 Node next; 3 int val; 4 5 Node(int val) { 6 this.val = val; 7 } 8 } 9 10 11 public class Solution { 12 public static void main(String[] args) { 13 Node n1 = new Node(1); 14 Node n2 = new Node(2); 15 Node n3 = new Node(3); 16 Node n4 = new Node(4); 17 Node n5 = new Node(5); 18 19 n1.next = n2; 20 n2.next = n3; 21 n3.next = n4; 22 n4.next = n5; 23 n5.next = n3; 24 25 System.out.println(isCircle(n1)); 26 System.out.println(isCircle2(n1)); 27 } 28 29 private static boolean isCircle(Node n) { 30 Node slow = n; 31 Node fast = n.next; 32 33 while (fast != null) { 34 if (slow == fast) { 35 return true; 36 } 37 slow = slow.next; 38 fast = fast.next.next; 39 if (fast == null) { 40 return false; 41 } 42 } 43 return true;//元素只有一个,我们认为也算成环 44 } 45 46 private static boolean isCircle2(Node n) { 47 HashSet<Node> hashSet = Sets.newHashSet(); 48 while (n != null) { 49 if (hashSet.contains(n)) { 50 return true; 51 } else { 52 hashSet.add(n); 53 } 54 n = n.next; 55 if (n == null) { 56 return false; 57 } 58 } 59 return true; 60 } 61 }
五 逆波兰求表达式的值(stack应用)
1 问题描述:
2 中缀表达式 -> 后缀表达式
中缀表达式a + b*c + (d * e + f) * g,其转换成后缀表达式则为a b c * + d e * f + g * +。
转换过程需要用到栈,具体过程如下:
1)如果遇到操作数,我们就直接将其输出。
2)如果遇到操作符,则我们将其放入到栈中,遇到左括号时我们也将其放入栈中。
3)如果遇到一个右括号,则将栈元素弹出,将弹出的操作符输出直到遇到左括号为止。注意,左括号只弹出并不输出。
4)如果遇到任何其他的操作符,如(“+”, “*”,“(”)等,从栈中弹出元素直到遇到发现更低优先级的元素(或者栈为空)为止。弹出完这些元素后,才将遇到的操作符压入到栈中。有一点需要注意,只有在遇到" ) "的情况下我们才弹出" ( ",其他情况我们都不会弹出" ( "。
5)如果我们读到了输入的末尾,则将栈中所有元素依次弹出。
3 转换过程实例
规则很多,还是用实例比较容易说清楚整个过程。以上面的转换为例,输入为a + b * c + (d * e + f)*g,处理过程如下:
1)首先读到a,直接输出。
2)读到“+”,将其放入到栈中。
3)读到b,直接输出。
此时栈和输出的情况如下:

4)读到“*”,因为栈顶元素"+"优先级比" * " 低,所以将" * "直接压入栈中。
5)读到c,直接输出。
此时栈和输出情况如下:

6)读到" + ",因为栈顶元素" * "的优先级比它高,所以弹出" * "并输出, 同理,栈中下一个元素" + "优先级与读到的操作符" + "一样,所以也要弹出并输出。然后再将读到的" + "压入栈中。
此时栈和输出情况如下:

7)下一个读到的为"(",它优先级最高,所以直接放入到栈中。
8)读到d,将其直接输出。
此时栈和输出情况如下:

9)读到" * ",由于只有遇到" ) "的时候左括号"("才会弹出,所以" * "直接压入栈中。
10)读到e,直接输出。
此时栈和输出情况如下:

11)读到" + ",弹出" * "并输出,然后将"+"压入栈中。
12)读到f,直接输出。
此时栈和输出情况:

13)接下来读到“)”,则直接将栈中元素弹出并输出直到遇到"("为止。这里右括号前只有一个操作符"+"被弹出并输出。

14)读到" * ",压入栈中。读到g,直接输出。

15)此时输入数据已经读到末尾,栈中还有两个操作符“*”和" + ",直接弹出并输出。

至此整个转换过程完成。
4 代码实现
1 package com.balfish.hotel.zzAlgorithm; 2 3 import com.google.common.collect.ImmutableMap; 4 5 import java.util.Stack; 6 import java.util.regex.Pattern; 7 8 /** 9 * 中缀表达式 -> 逆波兰表达式(后缀表达式) -> 计算结果 10 * <p> 11 * 仅为了说明算法的实现,我们假设操作数均为0-9,符号只有加减乘除和括号 12 * <p> 13 * Created by yhm on 2017/11/21 AM11:26. 14 */ 15 public class Test1121 { 16 17 /** 18 * guava jar 19 * 获得符号对应的优先级,我们假设只有'#', '+', '-', '*', '/', '(', ')' 20 */ 21 private static final ImmutableMap<Character, Integer> map = ImmutableMap 22 .<Character, Integer>builder() 23 .put('#', 0) //初始栈 24 .put('(', 1) 25 .put('+', 2) 26 .put('-', 2) 27 .put('*', 3) 28 .put('/', 3) 29 .put(')', 4) 30 .build(); 31 32 public static void main(String[] args) { 33 System.out.println(middleToSuffixExpression("a + b * c + (d * e + f)*g")); 34 System.out.println(middleToSuffixExpression("5 * (3 + 4) - 6 + 8/2")); 35 System.out.println(calSuffixExpression(middleToSuffixExpression("5 * (3 + 4) - 6 + 8/2"))); 36 } 37 38 /** 39 * 中缀表达式转成后缀表达式 40 * a + b*c + (d * e + f) * g -> abc*+de*f+g*+ 41 * 42 * @param middle 中缀表达式 43 * @return 后缀表达式 44 */ 45 private static String middleToSuffixExpression(String middle) { 46 MyStack<Character> charStack = new MyStack<>(); 47 StringBuilder stringBuilder = new StringBuilder(); 48 charStack.push('#'); 49 50 for (char c : middle.toCharArray()) { 51 if (c == ' ') { 52 continue; 53 } 54 55 if (map.get(c) == null) { //不是操作符 56 stringBuilder.append(c); 57 continue; 58 } 59 60 if (c == '(') { 61 charStack.push(c); 62 } else if (c == ')') { 63 while (true) { 64 Character peek = charStack.peek(); 65 charStack.pop(); 66 if (peek == '(') { 67 break; 68 } 69 stringBuilder.append(peek); 70 } 71 } else { 72 while (true) { 73 Character peek = charStack.peek(); 74 if (map.get(c) > map.get(peek)) { 75 charStack.push(c); 76 break; 77 } 78 // 栈顶优先级高,需要弹出 79 charStack.pop(); 80 stringBuilder.append(peek); 81 } 82 } 83 } 84 85 // 剩余的符号全部弹出 86 while (true) { 87 Character peek = charStack.peek(); 88 if (peek == '#') { 89 break; 90 } 91 charStack.pop(); 92 stringBuilder.append(peek); 93 } 94 return stringBuilder.toString(); 95 } 96 97 /** 98 * 计算后缀表达式 99 * 100 * @param suffix 后缀表达式 101 * @return 结果,方便起见,我们假设结果为int不暴栈 102 */ 103 private static Integer calSuffixExpression(String suffix) { 104 Stack<Integer> stack = new Stack<>(); 105 for (char c : suffix.toCharArray()) { 106 if (Pattern.compile("[0-9]").matcher(String.valueOf(c)).matches()) { 107 stack.push(c - '0'); 108 } else { 109 int second = stack.peek(); 110 stack.pop(); 111 int first = stack.peek(); 112 stack.pop(); 113 Integer tmp = cal(first, second, c); 114 stack.push(tmp); 115 } 116 } 117 return stack.peek(); 118 } 119 120 private static Integer cal(int first, int second, char c) { 121 Integer ret = null; 122 switch (c) { 123 case '+': 124 ret = first + second; 125 break; 126 case '-': 127 ret = first - second; 128 break; 129 case '*': 130 ret = first * second; 131 break; 132 case '/': 133 ret = first / second; 134 break; 135 } 136 return ret; 137 } 138 }
六 大数各个位相加和直到是个一位数
2012年3月11日dlut周赛1002
LOVELY-POINT
TimeLimit: 1 Second MemoryLimit: 32 Megabyte
Totalsubmit: 154 Accepted: 42
Description
The fascination of a Lolita is n^n.n is a positive integer which is her age.
For example, consider the her age n=4. 4*4*4*4=256. Adding the 2 ,the 5,and the 6 yields a value of 13. Since 13 is not a single digit, the process must be repeated. Adding the 1 and the 3 yeilds 4, the lovely-point of the Lolita is 4.
Input
Output
Sample Input
4
3
0
Sample Output
4
9
接触到的第一道数论题,开始以为是大数运算问题,其实可以步步求余来简化。
那么本题的关键在于一个%9
我们看这样的例子abc-->表示为100*a +10*b +c 那么进行各个位的数值相加运算后是什么结果呢?
我们认为是(100*a +10*b +c )%9的余数,因为(100*a +10*b +c )可以写成(99*a +9*b)+(a+b+c),推广之~那么我们步步对9求余,如果能被9整除则结果为9,否则继续求余。
#include <iostream>
#include <cstring>
#include <cstdio>
#include <stack>
using namespace std;
int main()
{
//freopen("in.txt","r",stdin);
int n;
while(cin >> n)
{
int flag=0;
if (n==0)break;
int temp=n;
for(int i=0;i<temp-1;i++)
{
if(n%9==0)
{
flag=1;
break;
}
n%=9;
n=n*temp;
}
if(flag==1)cout << 9 << endl;
else
{
if(n>9)n%=9;
cout << n << endl;
}
}
return 0;
}
七 欧拉函数
在数论,对正整数n,欧拉函数是少于或等于n的数中与n互质的数的数目。此函数以其首名研究者欧拉命名,它又称为Euler's totient function、φ函数、欧拉商数等。 例如φ(8)=4,因为1,3,5,7均和8互质。 从欧拉函数引伸出来在环论方面的事实和拉格朗日定理构成了欧拉定理的证明。
简介
φ函数的值
φ(1)=1(唯一和1互质的数就是1本身)。
若n是质数p的k次幂,φ(n)=p^k-p^(k-1)=(p-1)p^(k-1),因为除了p的倍数外,其他数都跟n互质。
欧拉函数是积性函数——若m,n互质,φ(mn)=φ(m)φ(n)。
特殊性质:当n为奇数时,φ(2n)=φ(n), 证明于上述类似。
证明
设A, B, C是跟m, n, mn互质的数的集,据中国剩余定理,A*B和C可建立一一对应的关系。因此φ(n)的值使用算术基本定理便知,
若 n= ∏p^(α(下标p))
则φ(n)=∏(p-1)p^(α(下标p)-1)=n∏(1-1/p)
例如φ(72)=φ(2^3×3^2)=(2-1)2^(3-1)×(3-1)3^(2-1)=24
与欧拉定理、费马小定理的关系
对任何两个互质的正整数a, m, m>=2有
a^φ(m)≡1(mod m)
即欧拉定理
当m是质数p时,此式则为:
a^(p-1)≡1(mod p)
即费马小定理。
欧拉函数的编程实现
利用欧拉函数和它本身不同质因数的关系,用筛法计算出某个范围内所有数的欧拉函数值。
欧拉函数和它本身不同质因数的关系:欧拉函数ψ(N)=N{∏p|N}(1-1/p)。(P是数N的质因数)
如:
ψ(10)=10×(1-1/2)×(1-1/5)=4;
ψ(30)=30×(1-1/2)×(1-1/3)×(1-1/5)=8;
ψ(49)=49×(1-1/7)=42。
#include <stdlib.h>
#include<stdio.h>
#define N 100
int main()
{
int *phi,i,j;
int *prime;
prime=(int*)malloc((N+1)*sizeof(int));
prime[0]=prime[1]=0;
for(i=2;i<=N;i++)
prime[i]=1;
for(i=2;i*i<=N;i++)
{
if(prime[i])
{
for(j=i*i;j<=N;j+=i)
prime[j]=0;
}
} //这段求出了N内的所有素数
phi=(int*)malloc((N+1)*sizeof(int));
for(i=1;i<=N;i++)
phi[i]=i;
for(i=2;i<=N;i++)
{
if(prime[i])
{
for(j=i;j<=N;j+=i)
phi[j]=phi[j]/i*(i-1); //此处注意先/i再*(i-1),否则范围较大时会溢出
}
}
for(i=1;i<N;i++)
printf("%d %d
",i,phi[i]);
return 0;
}
八 rmq算法:区间最值查询
1. 概述
RMQ(Range Minimum/Maximum Query),即区间最值查询,是指这样一个问题:对于长度为n的数列A,回答若干询问RMQ(A,i,j)(i,j<=n),返回数列A中下标在i,j之间的最小/大值。这两个问题是在实际应用中经常遇到的问题,下面介绍一下解决这两种问题的比较高效的算法。当然,该问题也可以用线段树(也叫区间树)解决,算法复杂度为:O(N)~O(logN),这里我们暂不介绍。
2.RMQ算法
对于该问题,最容易想到的解决方案是遍历,复杂度是O(n)。但当数据量非常大且查询很频繁时,该算法无法在有效的时间内查询出正解。
本节介绍了一种比较高效的在线算法(ST算法)解决这个问题。所谓在线算法,是指用户每输入一个查询便马上处理一个查询。该算法一般用较长的时间做预处理,待信息充足以后便可以用较少的时间回答每个查询。ST(Sparse Table)算法是一个非常有名的在线处理RMQ问题的算法,它可以在O(nlogn)时间内进行预处理,然后在O(1)时间内回答每个查询。
(一)首先是预处理,用动态规划(DP)解决。
设A[i]是要求区间最值的数列,F[i, j]表示从第i个数起连续2^j个数中的最大值。(DP的状态)
例如:
A数列为:3 2 4 5 6 8 1 2 9 7
F[1,0]表示第1个数起,长度为2^0=1的最大值,其实就是3这个数。同理 F[1,1] = max(3,2) = 3, F[1,2]=max(3,2,4,5) = 5,F[1,3] = max(3,2,4,5,6,8,1,2) = 8;
并且我们可以容易的看出F[i,0]就等于A[i]。(DP的初始值)
这样,DP的状态、初值都已经有了,剩下的就是状态转移方程。
我们把F[i,j]平均分成两段(因为f[i,j]一定是偶数个数字),从 i 到i + 2 ^ (j - 1) - 1为一段,i + 2 ^ (j - 1)到i + 2 ^ j - 1为一段(长度都为2 ^ (j - 1))。用上例说明,当i=1,j=3时就是3,2,4,5 和 6,8,1,2这两段。F[i,j]就是这两段各自最大值中的最大值。于是我们得到了状态转移方程F[i, j]=max(F[i,j-1], F[i + 2^(j-1),j-1])。
void RMQ(int num) //预处理->O(nlogn)
{
for(int j = 1; j < 20; ++j)
for(int i = 1; i <= num; ++i)
if(i + (1 << j) - 1 <= num)
{
maxsum[i][j] = max(maxsum[i][j - 1], maxsum[i + (1 << (j - 1))][j - 1]);
minsum[i][j] = min(minsum[i][j - 1], minsum[i + (1 << (j - 1))][j - 1]);
}
}
这里我们需要注意的是循环的顺序,我们发现外层是j,内层所i,这是为什么呢?可以是i在外,j在内吗?
答案是不可以。因为我们需要理解这个状态转移方程的意义。
状态转移方程的含义是:先更新所有长度为F[i,0]即1个元素,然后通过2个1个元素的最值,获得所有长度为F[i,1]即2个元素的最值,然后再通过2个2个元素的最值,获得所有长度为F[i,2]即4个元素的最值,以此类推更新所有长度的最值。
而如果是i在外,j在内的话,我们更新的顺序就是F[1,0],F[1,1],F[1,2],F[1,3],表示更新从1开始1个元素,2个元素,4个元素,8个元素(A[0],A[1],....A[7])的最值,这里F[1,3] = max(max(A[0],A[1],A[2],A[3]),max(A[4],A[5],A[6],A[7]))的值,但是我们根本没有计算max(A[0],A[1],A[2],A[3])和max(A[4],A[5],A[6],A[7]),所以这样的方法肯定是错误的。
(二)然后是查询。
假如我们需要查询的区间为(i,j),那么我们需要找到覆盖这个闭区间(左边界取i,右边界取j)的最小幂(可以重复,比如查询5,6,7,8,9,我们可以查询5678和6789)。
因为这个区间的长度为j - i + 1,所以我们可以取k=log2( j - i + 1),则有:RMQ(A, i, j)=max{F[i , k], F[ j - 2 ^ k + 1, k]}。
举例说明,要求区间[2,8]的最大值,k = log2(8 - 2 + 1)= 2,即求max(F[2, 2],F[8 - 2 ^ 2 + 1, 2]) = max(F[2, 2],F[5, 2]);
在这里我们也需要注意一个地方,就是<<运算符和+-运算符的优先级。
比如这个表达式:5 - 1 << 2是多少?
答案是:4 * 2 * 2 = 16。所以我们要写成5 - (1 << 2)才是5-1 * 2 * 2 = 1
#include <cstdio>
#include <iostream>
#include <cmath>
using namespace std;
const int N=100005;
int minsum[N][21],maxsum[N][21];
// f(i,j)表示i~i+(2^j)-1中最大或者最小值;
//f(i,j)=max(f(i,j-1),f(i+2^(j-1),j-1)
void RMQ(int n)
{
for(int j=1;j<=20;j++)
for(int i=1;i<=n;i++)
{ if(i+(1<<(j-1))<=n)
{ maxsum[i][j]=max(maxsum[i][j-1],maxsum[i+(1<<(j-1))][j-1]);
minsum[i][j]=min(minsum[i][j-1],minsum[i+(1<<(j-1))][j-1]);
}
}
}
int main()
{
int n,m,i,j,k,maxans,minans;
cin>>n>>m;
for(i=1;i<=n;i++)
{
scanf("%d",&maxsum[i][0]);
minsum[i][0]=maxsum[i][0];
}
RMQ(n);
while(m--)
{
scanf("%d%d",&i,&j);
//我们可以取k=log2( j - i + 1),则有:
//i~j的最大值=max{F[i , k], F[ j - 2 ^ k + 1, k]}。
k=log10(j-i+1.0)/log10(2.0);
maxans=max(maxsum[i][k],maxsum[j-(1<<k)+1][k]);
minans=min(minsum[i][k],minsum[j-(1<<k)+1][k]);
printf("%d
",maxans-minans);
}
return 0;
}
九 动态规划:一道理想收入问题
public class DpDemo {
public static void main(String[] args) {
// f[i] = max{f[i-1],f[j]*v[i]/v[j]} (1<=j<i)
double v[] = {1, 10, 5, 9, 8};
double ii = v.length;
double f[] = new double[5];
f[0] = v[0];
// for (int i = 1; i < ii; i++) {
// for (int j = 0 ;j < i ; j++) {
// f[i] = Math.max(f[i - 1], f[j] * v[i] / v[j]);
// }
// }
for (int i = 1; i < ii; i++) {
double maxx = -1;
maxx = Math.max(maxx, f[i - 1] / v[i - 1]);
f[i] = Math.max(f[i - 1], maxx * v[i]);
}
System.out.println(f[f.length - 1]);
}
}
十 一个素数有多少种连续素数相加方案(poj 2739)
简单题 素数打表 根据数据量 用n2算法遍历 开一个save【k】素数存前k个素数和即可。
#include <iostream>
#include <cstdio>
#include <memory.h>
#include <cmath>
using namespace std;
const int maxn=10002;
int pri[maxn+1];
int save[2000+1];
int s[2000+1];
void make_pri()
{
pri[0]=0;
pri[1]=0;
for(int i=2;i<=maxn;i++)
{
pri[i]=1;
}
for(int i=2;i*i<=maxn;i++)
{
if(pri[i])
{
for(int j=i*i;j<=maxn;j+=i)
pri[j]=0;
}
}
}
void init()
{
memset(save,0,sizeof(save));
memset(s,0,sizeof(s));
int i,j=2;
s[1]=2;
for(i=3;i<=maxn;i++)
{
if(pri[i]==1)
{
s[j++]=i;
}
}
for(int i=1;i<=2000;i++)
{
save[i]=save[i-1]+s[i];
}
}
int main()
{
//freopen("in.txt","r",stdin);
memset(save,0,sizeof(save));
make_pri();
init();
int n;
while(cin >> n && n!=0)
{
int cnt=0;
int last;
if(pri[n]==1)
{
for(int i=2000;i>=1;i--)
{
if(s[i]==n)
{
last=i;
}
}
}
else
{
for(int i=2000;i>=1;i--)
{
if(s[i]<n && s[i+1]>n)
{
last=i;
}
}
}
for(int i=last;i>=1;i--)
{
for(int j=i-1;j>=0;j--)
{
if(save[i]-save[j]==n)
{
cnt++;
}
}
}
cout << cnt << endl;
}
return 0;
}
十一 二维有序数组查找问题
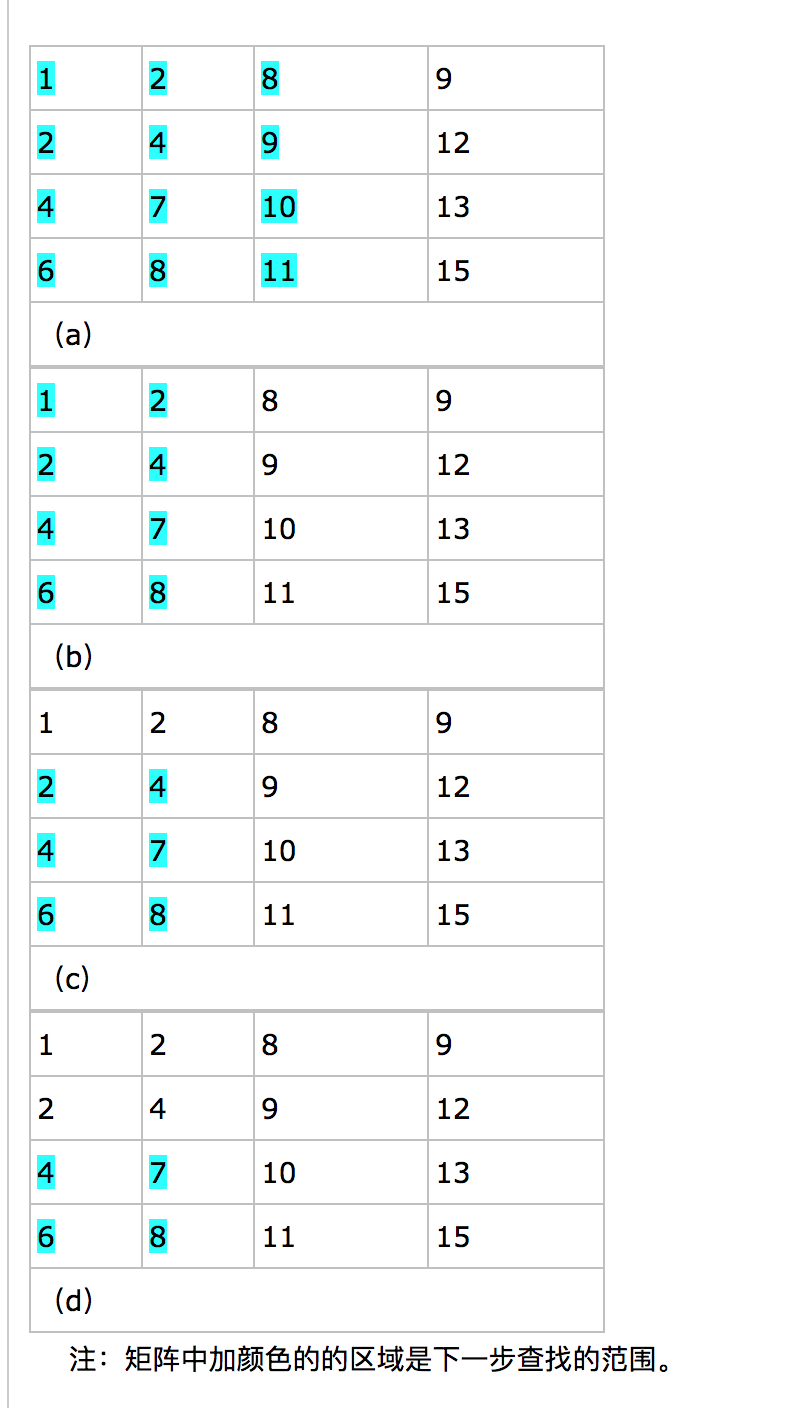
题目: 在一个二维数组中,每一行都按照从左到右递增的顺序排序,诶一列都按照从上到下递增的顺序排序,请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否包含了该整数
| 1 | 2 | 8 | 9 |
| 2 | 4 | 9 | 12 |
| 4 | 7 | 10 | 13 |
| 6 | 8 | 11 | 15 |
- 数组中选取的数字(图中全黑的位置)刚好是要查找的数字(相等),查找过程结束;
- 选取的数字小于要查找的数字,那么根据数组排序的规则,要查找的数字应该在当前位置的右边或者下边(如下图2.1(a)所示)
- 选取的数字大于要查找的数字,那么要查找的数字应该在当前选取的位置的上边或者左边。

/**
* @param num 被查找的二维数组
* @param rows 行数
* @param columns 列数
* @param number 要查找的数字
* @return 是否找到要查找的数字(number)
*/
public static Boolean Find(int num[][], int rows, int columns, int number) {
Boolean found = false;
int row = 0;
int column = columns - 1;
if (rows > 0 && columns > 0) {
while (row < rows && column >= 0) {
if (num[row][column] == number) //查找到
{
found = true;
break;
} else if (num[row][column] > number) {
--column; //删除列
} else {
++row; //删除行
}
}
}
return found;
}
public static void main(String[] args) {
//初始化数字的值
int num[][] = {{1, 2, 8, 9}, {2, 4, 9, 12}, {4, 7, 10, 13}, {6, 8, 11, 15}};
System.out.println(Find(num, 4, 4, 7)); //在数组中
System.out.println(Find(num, 4, 4, 5)); //5不在数组中
}
十二 不用临时空间实现swap(a, b)
public static void main(String[] args) { // 加法方式 int a = 1; int b = 2; a = a ^ b; b = a ^ b; a = a ^ b; System.out.println(a); System.out.println(b); //异或 a = 1; b = 2; a = a + b; b = a - b; a = a - b; System.out.println(a); System.out.println(b); }
十三 怎样从10亿查询词中找出出现频率最高的10个
1. 问题描述
在大规模数据处理中,常遇到的一类问题是,在海量数据中找出出现频率最高的前K个数,或者从海量数据中找出最大的前K个数,这类问题通常称为“top K”问题,如:在搜索引擎中,统计搜索最热门的10个查询词;在歌曲库中统计下载率最高的前10首歌等等。
2. 当前解决方案
针对top k类问题,通常比较好的方案是【分治+trie树/hash+小顶堆】,即先将数据集按照hash方法分解成多个小数据集,然后使用trie树或者hash统计每个小数据集中的query词频,之后用小顶堆求出每个数据集中出频率最高的前K个数,最后在所有top K中求出最终的top K。
实际上,最优的解决方案应该是最符合实际设计需求的方案,在实际应用中,可能有足够大的内存,那么直接将数据扔到内存中一次性处理即可,也可能机器有多个核,这样可以采用多线程处理整个数据集。
本文针对不同的应用场景,介绍了适合相应应用场景的解决方案。
3. 解决方案
3.1 单机+单核+足够大内存
设每个查询词平均占8Byte,则10亿个查询词所需的内存大约是10^9*8=8G内存。如果你有这么大的内存,直接在内存中对查询词进行排序,顺序遍历找出10个出现频率最大的10个即可。这种方法简单快速,更加实用。当然,也可以先用HashMap求出每个词出现的频率,然后求出出现频率最大的10个词。
3.2 单机+多核+足够大内存
这时可以直接在内存中实用hash方法将数据划分成n个partition,每个partition交给一个线程处理,线程的处理逻辑是同3.1节类似,最后一个线程将结果归并。
该方法存在一个瓶颈会明显影响效率,即数据倾斜,每个线程的处理速度可能不同,快的线程需要等待慢的线程,最终的处理速度取决于慢的线程。解决方法是,将数据划分成c*n个partition(c>1),每个线程处理完当前partition后主动取下一个partition继续处理,直到所有数据处理完毕,最后由一个线程进行归并。
3.3 单机+单核+受限内存
这种情况下,需要将原数据文件切割成一个一个小文件,如,采用hash(x)%M,将原文件中的数据切割成M小文件,如果小文件仍大于内存大小,继续采用hash的方法对数据文件进行切割,直到每个小文件小于内存大小,这样,每个文件可放到内存中处理。采用3.1节的方法依次处理每个小文件。
3.4 多机+受限内存
这种情况下,为了合理利用多台机器的资源,可将数据分发到多台机器上,每台机器采用3.3节中的策略解决本地的数据。可采用hash+socket方法进行数据分发。
从实际应用的角度考虑,3.1~3.4节的方案并不可行,因为在大规模数据处理环境下,作业效率并不是首要考虑的问题,算法的扩展性和容错性才是首要考虑的。算法应该具有良好的扩展性,以便数据量进一步加大(随着业务的发展,数据量加大是必然的)时,在不修改算法框架的前提下,可达到近似的线性比;算法应该具有容错性,即当前某个文件处理失败后,能自动将其交给另外一个线程继续处理,而不是从头开始处理。
Top k问题很适合采用MapReduce框架解决,用户只需编写一个map函数和两个reduce 函数,然后提交到Hadoop(采用mapchain和reducechain)上即可解决该问题。对于map函数,采用hash算法,将hash值相同的数据交给同一个reduce task;对于第一个reduce函数,采用HashMap统计出每个词出现的频率,对于第二个reduce 函数,统计所有reduce task输出数据中的top k即可。
4. 总结
Top K问题是一个非常常见的问题,公司一般不会自己写个程序进行计算,而是提交到自己核心的数据处理平台上计算,该平台的计算效率可能不如直接写程序高,但它具有良好的扩展性和容错性,而这才是企业最看重的。
十四 最长公共子序列 和 最长公共子串
口水题,状态转移方程为:
![]()
public class ZZTest { public static void main(String[] args) { int[] m = new int[]{1, 2, 3, 4, 5}; int[] n = new int[]{2, 3, 5}; longCommonSubstring(m, n); longCommonSubSequence(m, n); } private static void longCommonSubstring(int[] m, int[] n) { int dp[][] = new int[10][10]; dp[0][0] = 0; dp[0][1] = 0; dp[1][0] = 1; for (int i = 1; i < m.length; i++) { for (int j = 1; j < n.length; j++) { dp[i][j] = m[i] == n[j] ? dp[i - 1][j - 1] + 1 : Math.max(dp[i - 1][j], dp[i][j - 1]); System.out.println(String.format("dp[%s][%s] = %s", i, j, dp[i][j])); } } System.out.println(dp[m.length - 1][n.length - 1]); } private static void longCommonSubSequence(int[] m, int[] n) { int dp[][] = new int[10][10]; dp[0][0] = 0; dp[0][1] = 0; dp[1][0] = 1; int len; int max_len = 0; for (int i = 1; i < m.length; i++) { for (int j = 1; j < n.length; j++) { if (m[i] == n[j]) { len = dp[i - 1][j - 1] + 1; } else { len = 1; } max_len = Math.max(max_len, len); } } System.out.println(max_len); } }
运行结果:
dp[1][1] = 1 dp[1][2] = 1 dp[2][1] = 2 dp[2][2] = 2 dp[3][1] = 2 dp[3][2] = 2 dp[4][1] = 2 dp[4][2] = 3 3 2
十五 随机数概率变形0/1概率p和p-1 改变概率为1/2
题目:已知一随机发生器,产生0的概率是p,产生1的概率是1-p,现在要你构造一个发生器,
使得它构造0和1的概率均为1/2
题目解答:
两次调用该RANDOM函数,如果其概率为P(x),调用2次
P(1) = p P(0) = 1-p
P'(1) =p P'(0) = 1-p
概率如下:
11 p*p 10 p*(1-p)
01 (1-p)*p 00 (1-p)*(1-p)


int random_0_1() { int i = RANDOM(); int j = RANDOM(); int result; while (true) { if (i == 0 && j == 1) { result = 0; break; } else if (i == 1 && j == 0) { result = 1; break; } else continue; } return result; }
扩展:
已知一随机发生器,产生0的概率是p,产生1的概率是1-p,现在要你构造一个发生器,
使得它构造0和1的概率均为1/2;构造一个发生器,使得它构造1、2、3的概率均为1/3;...,
构造一个发生器,使得它构造1、2、3、...n的概率均为1/n,要求复杂度最低。
解答:
对n=2,认为01表示0、10表示1,等概率,其他情况放弃
对n=3,认为001表示1、010表示2,100表示3,等概率,其他情况放弃
对n=4,认为0001表示1、0010表示2,0100表示3,1000表示4,等概率,其他情况放弃
首先是1/2的情况,我们一次性生成两个数值,如果是00或者11丢弃,否则留下,01为1,10为0,他们的概率都是p*(1-p)是相等的,所以等概率了。然后是1/n的情况了,我们以5为例,此时我们取x=2,因为C(2x,x)=C(4,2)=6是比5大的最小的x,此时我们就是一次性生成4位二进制,把1出现个数不是2的都丢弃,这时候剩下六个:0011,0101,0110,1001,1010,1100,取最小的5个,即丢弃1100,那么我们对于前5个分别编号1到5,这时候他们的概率都是p*p*(1-p)*(1-p)相等了。
关键是找那个最小的x,使得C(2x,x)>=n这样能提升查找效率
十六 全排列组合
public class ZZTest2 { public static void main(String[] args) { int a[] = new int[]{1, 2, 3, 4}; func(a, 0); } private static void func(int[] a, int index) { if (index == a.length) { System.out.println(Arrays.toString(a)); return; } for (int i = index; i < a.length; i++) { swap(a, index, i); func(a, index + 1); swap(a, i, index); } } private static void swap(int[] a, int index, int i) { int tmp = a[index]; a[index] = a[i]; a[i] = tmp; } }
十七 数组小和(单调和) - 归并排序
问题描述:
在s[0]的左边小于或等于s[0]的数的和为0
在s[1]的左边小于或等于s[1]的数的和为1
在s[2]的左边小于或等于s[2]的数的和为1+3=4
在s[3]的左边小于或等于s[3]的数的和为1
在s[4]的左边小于或等于s[4]的数的和为1+3+2=6
在s[5]的左边小于或等于s[5]的数的和为1+3+5+2+4=15
所以s的小和为0+1+4+1+6+15=27
给定一个数组s,实现函数返回s的小和。
public class Test1121 { public static void main(String[] args) { int[] arr = {1, 3, 5, 2, 4, 6}; System.out.println(getSmallSum(arr)); } public static int getSmallSum(int[] arr) { if (arr == null || arr.length == 0) { return 0; } return mergeSortRecursion(arr, 0, arr.length - 1); } /** * 递归实现归并排序 * * @param arr * @param l * @param r * @return 返回数组小和 */ public static int mergeSortRecursion(int[] arr, int l, int r) { if (l == r) { // 当待排序数组长度为1时,递归开始回溯,进行merge操作 return 0; } int mid = (l + r) / 2; return mergeSortRecursion(arr, l, mid) + mergeSortRecursion(arr, mid + 1, r) + merge(arr, l, mid, r); } /** * 合并两个已排好序的数组s[left...mid]和s[mid+1...right] * * @param arr * @param left * @param mid * @param right * @return 返回合并过程中累加的数组小和 */ public static int merge(int[] arr, int left, int mid, int right) { int[] temp = new int[right - left + 1]; // 辅助存储空间 O(n) int index = 0; int i = left; int j = mid + 1; int smallSum = 0; // 新增,用来累加数组小和 while (i <= mid && j <= right) { if (arr[i] <= arr[j]) { // 当前一个数组元素小于或等于后一个数组元素时,累加小和 // s[i] <= s[j] -> s[i] <= s[j]...s[right] smallSum += arr[i] * (right - j + 1); temp[index++] = arr[i++]; } else { temp[index++] = arr[j++]; } } while (i <= mid) { temp[index++] = arr[i++]; } while (j <= right) { temp[index++] = arr[j++]; } for (int k = 0; k < temp.length; k++) { arr[left++] = temp[k]; } return smallSum; } }
牛客网有道数组单调和,实际上和该题为同一道题。
另一道数组中的逆序对,与该题解法类似,只是merge时逆序对的累加条件和算法有所不同,此时merge操作的代码如下:
/** * 合并两个已排好序的数组s[left...mid]和s[mid+1...right] * * @param arr * @param left * @param mid * @param right * @return 返回合并过程中累加逆序对 */ public static int merge(int[] arr, int left, int mid, int right) { int[] temp = new int[right - left + 1]; // 辅助存储空间 O(n) int index = 0; int i = left; int j = mid + 1; int inverseNum = 0; // 新增,用来累加数组逆序对 while (i <= mid && j <= right) { if (arr[i] <= arr[j]) { temp[index++] = arr[i++]; } else { // 当前一个数组元素大于后一个数组元素时,累加逆序对 // s[i] > s[j] -> s[i]...s[mid] > s[j] inverseNum += (mid - i + 1); temp[index++] = arr[j++]; } } while (i <= mid) { temp[index++] = arr[i++]; } while (j <= right) { temp[index++] = arr[j++]; } for (int k = 0; k < temp.length; k++) { arr[left++] = temp[k]; } return inverseNum; }
十八 二叉树的先序,中序,后序,层次遍历

class Node { private Node left; private Node right; private char c; public Node getLeft() { return left; } public void setLeft(Node left) { this.left = left; } public Node getRight() { return right; } public void setRight(Node right) { this.right = right; } public char getC() { return c; } public void setC(char c) { this.c = c; } } public class Test1121 { private static String str = "abd##eg##h##c#f##"; private static int count = str.length(); public static void main(String[] args) { Node node = initTree(); System.out.print("先序遍历结果:"); preOrder(node); System.out.println(); System.out.print("中序遍历结果:"); inOrder(node); System.out.println(); System.out.print("后序遍历结果:"); postOrder(node); System.out.println(); System.out.print("层次遍历结果:"); levelOrder(node); System.out.println(); System.out.print("二叉树的深度是:"); System.out.println(getDepth(node)); System.out.println(getDepth2(node)); } /** * 递归初始化树 */ private static Node initTree() { char c = str.charAt(str.length() - count--); if (c == '#') { return null; } Node node = new Node(); node.setC(c); node.setLeft(initTree()); node.setRight(initTree()); return node; } /** * 非递归先序遍历树 */ private static void preOrder(Node node) { Stack<Node> stack = new Stack<>(); stack.push(node); while (!stack.isEmpty()) { Node top = stack.pop(); if (top == null) { continue; } System.out.print(top.getC()); stack.push(top.getRight()); stack.push(top.getLeft()); } } /** * 非递归中序遍历树 */ private static void inOrder(Node node) { Stack<Node> stack = new Stack<>(); while (node != null || !stack.isEmpty()) { if (node != null) { stack.push(node); node = node.getLeft(); } else { node = stack.pop(); System.out.print(node.getC()); node = node.getRight(); } } } /** * 非递归后序遍历树 */ private static void postOrder(Node node) { Stack<Node> stack = new Stack<>(); Node flag = new Node(); while (node != null || !stack.isEmpty()) { while (node != null) { stack.push(node); node = node.getLeft(); } node = stack.peek(); if (node.getRight() == null || node.getRight() == flag) { System.out.print(node.getC()); flag = node; stack.pop(); if (stack.isEmpty()) { return; } node = null; } else { node = node.getRight(); } } } /** * 层次遍历遍历树 */ private static void levelOrder(Node node) { Queue<Node> queue = new LinkedBlockingQueue<>(); queue.add(node); while (!queue.isEmpty()) { Node first = queue.remove(); System.out.print(first.getC()); if (first.getLeft() != null) { queue.add(first.getLeft()); } if (first.getRight() != null) { queue.add(first.getRight()); } } } /** * 递归求树深度 */ private static int getDepth(Node node) { if (node == null) { return 0; } int left = getDepth(node.getLeft()); int right = getDepth(node.getRight()); return left > right ? left + 1 : right + 1; } /** * 非递归求树深度 */ private static int getDepth2(Node node) { Queue<Node> queue = new LinkedBlockingQueue<>(); queue.add(node); int cur; int last; int level = 0; while (!queue.isEmpty()) { cur = 0; last = queue.size(); while (cur < last) { Node first = queue.remove(); cur++; if (first.getLeft() != null) { queue.add(first.getLeft()); } if (first.getLeft() != null) { queue.add(first.getRight()); } } level++; } return level; } }
运行结果:
先序遍历结果:abdeghcf
中序遍历结果:dbgehacf
后序遍历结果:dghebfca
层次遍历结果:abcdegh
二叉树的深度是:4
4
十九 找出未打卡的员工(很多双鞋只有一个有一只,找出来)
题目:输入两行数据,第一行为全部员工的 id,第二行为某一天打卡的员工 id,已知只有一个员工没有打卡,求出未打卡员工的 id。(员工 id 不重复,每行输入的 id 未排序)
输入:
1001 1003 1002 1005 1004
1002 1003 1001 1004
输出:
1005
分析:可以用两个 List,第一个 List 保存所有员工的 id,第二个 List 保存打卡员工的 id,从第一个List 中把第二个 List 的数据都删除,最终剩下的就是未打卡员工的 id。
更好的方法:异或,两行数据中未打卡员工的 id 出现了一次,其余员工的 id 都出现了2次,两个相同的数异或为0。
public static void main(String[] args) { Scanner scan = new Scanner(System.in); while (scan.hasNext()) { String[] ids = scan.nextLine().split(" "); String[] marks = scan.nextLine().split(" "); int result = 0; for (int i = 0; i < ids.length; i++) { result ^= Integer.parseInt(ids[i]); } for (int i = 0; i < marks.length; i++) { result ^= Integer.parseInt(marks[i]); } System.out.println(result); } }
二十 括号字符串是否合法
某个字符串只包括(和),判断其中的括号是否匹配正确,比如(()())正确,((())()错误,不允许使用栈。
这种类似题的常见思路是栈,对于左括号入栈,如果遇到右括号,判断此时栈顶是不是左括号,是则将其出栈,不是则该括号序列不合法。
面试官要求不能使用栈,可以使用计数器,利用int count字段。
public static boolean checkBrackets(String str) { char[] cs = str.toCharArray(); int count = 0; for (int i = 0; i < cs.length; i++) { if (cs[i] == '(') count++; else { count--; if (count < 0) { return false; } } } return count == 0; }
二十一 扑克牌随机发牌
对于52张牌,实现一个随机打算扑克牌顺序的程序。52张牌使用 int 数组模拟。
该算法的难点是如何保证随机性?有个经典算法shuffle,思路就是遍历数组,在剩下的元素里再随机取一个元素,然后再在剩下的元素里再随机取一个元素。每次取完元素后,我们就不会让这个元素参与下一次的选取。
注意这儿是0 ≤ j ≤ i,包括j=i的情况,因为可能洗牌后某个牌未发生交换,比如第51张牌还是原来的第51张牌。
public void randomCards() { int[] data = new int[52]; Random random= new Random(); for (int i = 0; i < data.length; i++) data[i] = i; for (int i = data.length - 1; i > 0; i--) { int temp = random.nextInt(i+1); //产生 [0,i] 之间的随机数 swap(data,i,temp); } }
二十二 金条付费(智力题)
你让工人为你工作7天,回报是一根金条,这个金条平分成相连的7段,你必须在每天结束的时候给他们一段金条,如果只允许你两次把金条弄断,你如何给你的工人付费?
答案:切成一段,两段,和四段.
第1天: 给出1.
第2天: 给出2,还回1.
第3天: 给出1.
第4天: 给出4,还回1+2.
第5天: 给出1.
第6天: 给出2,还回1.
第7天: 给出1.
二十三 字符串反转
1. 递归法。 除非指定让用递归写,否则不推荐。(递归效率低,增加函数调用开销)
private static String recursionReverse(String str) { if ((null == str) || (str.length() <= 1)) { return str; } return reverse(str.substring(1)) + str.charAt(0); }
2. 非递归数组元素交换 高效写法
private static String reverse(String str) { if (org.apache.commons.lang3.StringUtils.isEmpty(str)) { return org.apache.commons.lang3.StringUtils.EMPTY; } char[] chars = str.toCharArray(); int length = chars.length; char c; for (int i = 0; i < length >> 1; i++) { c = chars[i]; chars[i] = chars[length - i - 1]; chars[length - i - 1] = c; } return String.valueOf(chars); }
3. 当然不一定用char[],StringBuilder也可以 高效写法,同2,只是换种方式
private static String stringBufferReverse(String str) { if ((null == str) || (str.length() <= 1 )) { return str; } StringBuilder result = new StringBuilder(str); for (int i = 0; i < (str.length() / 2); i++) { int swapIndex = str.length() - 1 - i; char swap = result.charAt(swapIndex); result.setCharAt(swapIndex, result.charAt(i)); result.setCharAt(i, swap); } return result.toString(); }
二十四 赛马
25匹马,速度都不同,但每匹马的速度都是定值。现在只有5条赛道,无法计时,即每赛一场最多只能知道5匹马的相对快慢。问最少赛几场可以找出25匹马中速度最快的前3名?
答案:
- 25匹马分成5组,先进行5场比赛
- 再将刚才5场的冠军进行第6场比赛,得到第一名。按照第6场比赛的名词把前面5场比赛所在的组命名为 A、B、C、D、E 组,即 A 组的冠军是第6场第一名,B 组的冠军是第二名 …
- 分析第2名和第3名的可能性,如果确定有多于3匹马比某匹马快,那它可以被淘汰了。因为 D 组是第6场的第四名,整个D 组被淘汰了,同意整个 E 组被淘汰。剩下可能是整体的第2、3名的就是C组的第1名、B组的1、2名、A组的第2、3名。取这5匹马进行第7场比赛
-所以,一共需要7场比赛