百度百科:快速排序(Quicksort)是对冒泡排序的一种改进,由C. A. R. Hoare在1962年提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
维基百科:快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。
步骤为:
- 从数列中挑出一个元素,称为 "基准"(pivot)。
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会退出,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
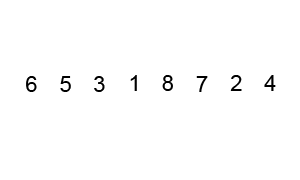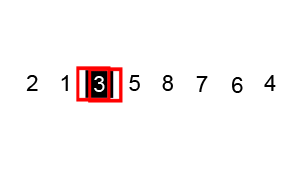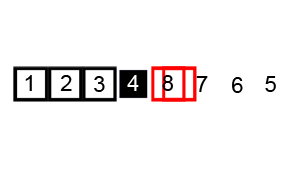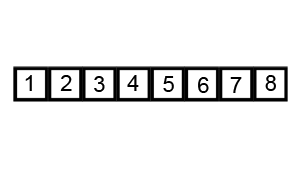
快速排序是在原地排序,就像插入排序,不用额外的空间。其效率依赖于输入数据的排序情况。最坏的情况原数据有序或者逆序,是O(n2)。
快速排序与归并排序的比较:两者都能达到O(nlgn)的时间复杂度,而且归并排序最差的情况下也能保证O(nlgn)的时间复杂度,而快速排序最差情况的时间复杂度是O(n2);但是,在实际的使用中,快速排序通常比归并排序快(3倍左右),而且快速排序是就地排序,在计算机虚拟内存/缓冲中的表现较好。
改进:
(1)划分子数组足够小时,直接采用插入排序;
(2)partition过程中元素的选取:1.随机选取;2.三点中值选取。
