1. Zookeeper可以做服务注册,服务注册后的负责均衡算法如下:
在连接Zookeeper的时候,ConnectStringParser 这个类中的将连接字符串拆分后添加到ArrayList<InetSocketAddress>这个集合中。
然后调用集合的打乱算法(random robin): Collections.shuffle(this.serverAddresses); 将IP形成一个环形。
在循环连接过程中有俩个参数:
currentIndex,lastIndex 这两个值在初始化的都是-1,当第一次连接的时候 currentIndex 变为1,lastIndex还是-1,当他们连接上的时候,将currentIndex 复制给 lastIndex ,算法如下:


2. 重试机制
平时我们配置的连接超时时间基本上都是3000ms,当有很多客户端的时候,连接不上都重试的话导致服务器压力大, 所以他们的时间间隔一般是 1,
4,8.,16,这种递增方式。
------------恢复内容开始------------
1. Zookeeper可以做服务注册,服务注册后的负责均衡算法如下:
在连接Zookeeper的时候,ConnectStringParser 这个类中的将连接字符串拆分后添加到ArrayList<InetSocketAddress>这个集合中。
然后调用集合的打乱算法(random robin): Collections.shuffle(this.serverAddresses); 将IP形成一个环形。
在循环连接过程中有俩个参数:
currentIndex,lastIndex 这两个值在初始化的都是-1,当第一次连接的时候 currentIndex 变为1,lastIndex还是-1,当他们连接上的时候,将currentIndex 复制给 lastIndex ,算法如下:
2. 重试机制
平时我们配置的连接超时时间基本上都是3000ms,当有很多客户端的时候,连接不上都重试的话导致服务器压力大, 所以他们的时间间隔一般是 1,
4,8.,16,这种递增方式。
3. Leader选举
leader选举是zookeeper遵循paxos协议进行选举主的,Leader选举是有投票过程的,过半选票。
4. Master选举
master选举是依托于zk的临时结点,谁抢到了这个临时结点的注册权并拥有了这个临时结点谁就是master。而master选举可以是任何应用以zookeeper节点的唯一性为基础去争抢创建节点从而选出master。
5. Zookeeper 服务角色
Leader: 他是在Zookeeper集群一启动的时候产生的。负责管理集群,其他服务器成为Follower,当Leader故障的时候,需要ZooKeeper能够能够快速的从Follower中选举出下一个Leader,Leader的职能:
1. 事务请求的唯一调度者和处理者,保证事务处理的正确性。
2. 集群内部各服务的调度者。
Follower: 处理客户端非事务请求,转发事务请求给Leader服务器;参与事务请求Proposal的投票;参与Leader选举投票和写功能。
Observer:用于提升服务器的集群非事务的处理能力。不参与选举和写功能。
6. Paxos协议
Paxos的目的是让整个集群的节点对某个值的变更达成一致。
Paxos算法基本上来说是大多数的决定会成整个集群的统一决定。
任何一个节点都可以提出修改数据的提案,是否通过这个决定取决于这个集群是否有超过半数的节点同意(所以Paxos协议建议集群中的节点是奇数)。
角色分析:
1. Proposer: 提出议案,提案信息包括提案编号和提案的内容。
2. Acceptor: 收到提案后可以接受的提案。
3. Learner:只能学习被批准的提案。
Paxos协议条件设定:
1. 每个议案必须有编号,且只能增长,不可重复。
2. 议案只有两种类型,提交的议案,批准的议案。
3. 如果Acceptor没有接受任何议案,那么他必须接受第一个议案。
4. 接受编号大的议案,如果小于之前接受议案编号,就不接受。
7. 算法详解
Paxos算法有两个阶段
-
Prepare阶段(第一阶段)
-
Accept阶段(第二阶段)
第一阶段
-
Proposer希望议案V。首先发出Prepare请求至大多数Acceptor。Prepare请求内容为序列号K;
-
Acceptor收到Prepare请求为编号K后,检查自己手里是否有处理过Prepare请求;
-
如果Acceptor没有接受过任何Prepare请求,那么用OK来回复Proposer,代表Acceptor必须接受收到的第一个议案;
-
否则,如果Acceptor之前接受过任何Prepare请求(如:MaxN),那么比较议案编号,如果K<MaxN,则用reject或者error回复Proposer;
-
如果K>=MaxN,那么检查之前是否有批准的议案,如果没有则用OK来回复Proposer,并记录K;
-
如果K>=MaxN,那么检查之前是否有批准的议案,如果有则回复批准的议案编号和议案内容(如:<AcceptN, AcceptV>, AcceptN为批准的议案编号,AcceptV为批准的议案内容)。

第二阶段
-
Proposer收到过半Acceptor发来的回复,回复都是OK,且没有附带任何批准过的议案编号和议案内容。那么Proposer继续提交批准请求,不过此时会连议案编号K和议案内容V一起提交(<K, V>这种数据形式)
-
Proposer收到过半Acceptor发来的回复,回复都是OK,且附带批准过的议案编号和议案内容(<pok,议案编号,议案内容>)。那么Proposer找到所有回复中AcceptN最大的那个AccpetV(假设为<pok,AcceptNx,AcceptVx>)作为提交批准请求(请求为<K,AcceptVx>)发送给Acceptor。
-
Proposer没有收到过半Acceptor发来的回复,则修改议案编号K为Kx,并将编号重新发送给Acceptors(重复Prepare阶段的过程)
-
Acceptor收到Proposer发来的Accept请求,如果编号K<MaxN则不回应或者reject。
-
Acceptor收到Proposer发来的Accept请求,如果编号K>=MaxN则批准该议案,并设置手里批准的议案为<K,接受议案的编号,接受议案的内容>,回复Proposer。
-
经过一段时间Proposer对比手里收到的Accept回复,如果超过半数,则结束流程(代表议案被批准),同时通知Leaner可以学习议案。
-
经过一段时间Proposer对比手里收到的Accept回复,如果未超过半数,则修改议案编号重新进入Prepare阶段。
Paxos流程图

总结:整个过程可以分为两步,第一步申请,申请始终取最大值,如果不是则拒绝。第二步判断是否过半,如果没有过半,就重复提交,如果过半了,就批准了。
ZAB协议
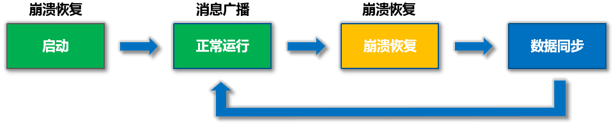
1. 崩溃回复
选举Leader
2. 消息广播
3. 数据同步
直接差异化同步
先回滚再差异化同步
仅回滚同步
全量同步
Leader选举
在zkServer.sh文件中,找到这么一句:
ZOOMAIN="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.local.only=$JMXLOCALONLY org.apache.zookeeper.server.quorum.QuorumPeerMain"
这一句指明了ZooKeeper在祁东的时候的Main方法的类。
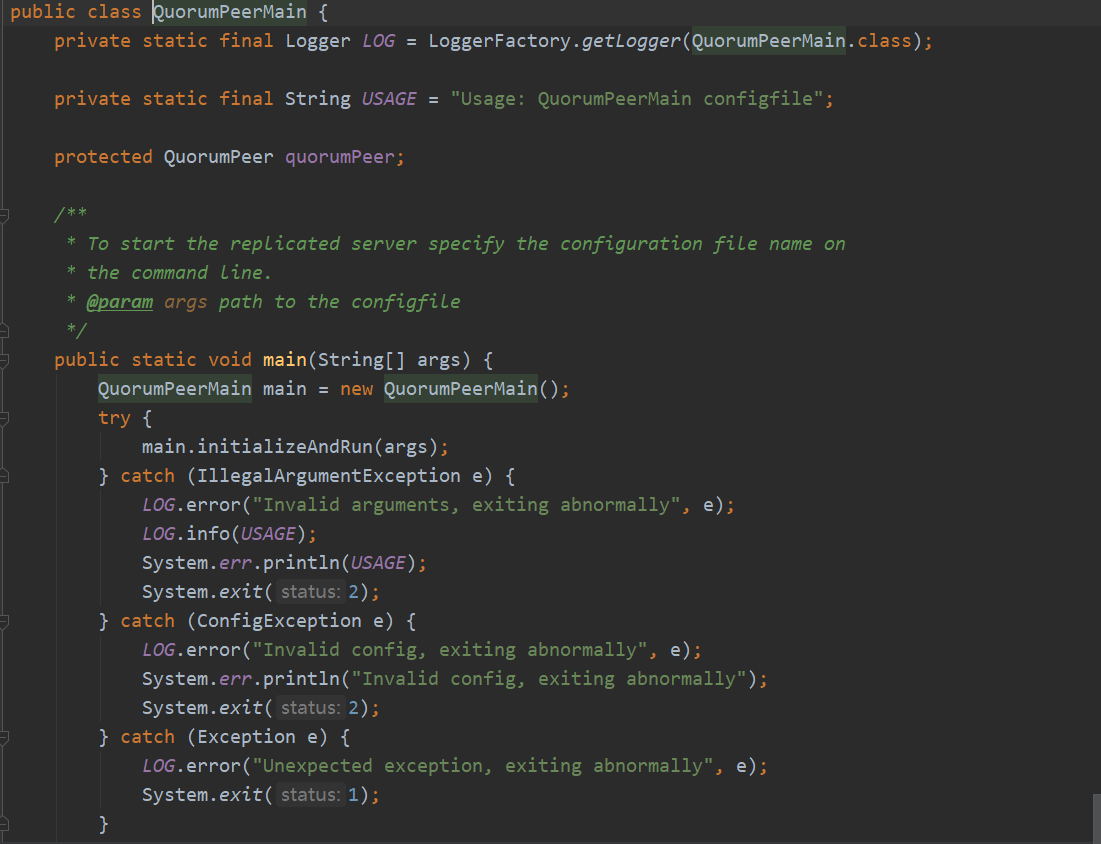
找到这个类后,他确实有自己的main方法,接下来我们看他的main方法:
1. 当ZooKeeper每一个节点启动起来的时候,他就生成一个QuorumPeer的进程。
2. initializeAndRun 为启动的方法。
3. QuorumPeerConfig 加载了我们在启动时候配置的配置文件。(conf/zoo.cfg)。
4. DatadirCleanupManager 这个类是用来定时的自动清理缓存和快照的信息的。
5. runFromConfig 这个方法中的ServerCnxnFactory这个类是用来客户端和服务端之间通讯用的,通讯采用的是NIO。
这里面需要注意的是:setZKDatabase 这个指定的是创建的DataTree存放的位置和快照存放的信息等。QuorumPeer是一个线程类,继承自Thread。
最后这个调用start方法,在这个start方法里,有三个方法:LoadDataBase(),cnxnFactory.start(),startLeaderElection().
6. loadDataBase 这个方法主要用来处理快照数据。
7. cnxnFactory.start(); 这个方法是启动通讯连接。
8. startLeaderElection();这个方法用来Leader选举
这个方法是个同步方法,首先获取了当前的选票,
responder = new ResponderThread();
responder.start();
ResponderThread这个类是一个线程类,当这个类start的时候,重写了他的run() 方法。
9. 在run方法中,选举真的进行。获取当前选票的状态(LOOKING, FOLLOWING, LEADING, OBSERVING)