spark 2.1.1
hive正在执行中的sql可以很容易的中止,因为可以从console输出中拿到当前在yarn上的application id,然后就可以kill任务,
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = hadoop_20181218163113_65da7e1f-b4b8-4cb8-86cc-236c37aea682
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1544593827645_9409, Tracking URL = http://rm1:8088/proxy/application_1544593827645_9409/
Kill Command = /export/App/hadoop-2.6.1/bin/hadoop job -kill job_1544593827645_9409
但是相同的sql,提交到spark thrift之后,想kill就没那么容易了,需要到spark thrift的页面手工找到那个sql然后kill对应的job:
1 找到sql
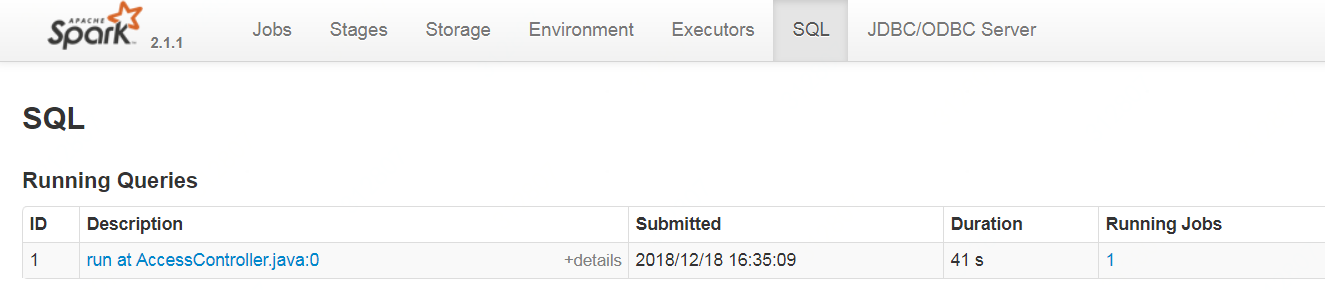
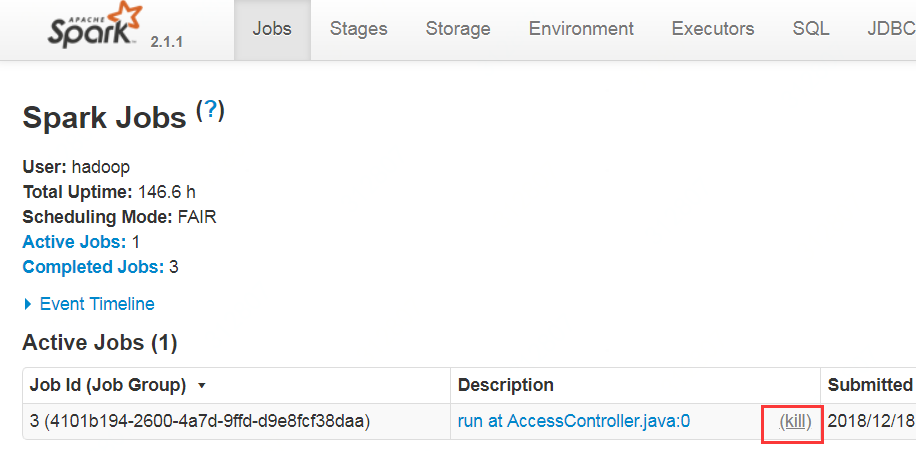
2 kill对应的job
注意到spark thrift页面还可以查看当前所有session,

并且可以查看一个session中所有执行job的情况,
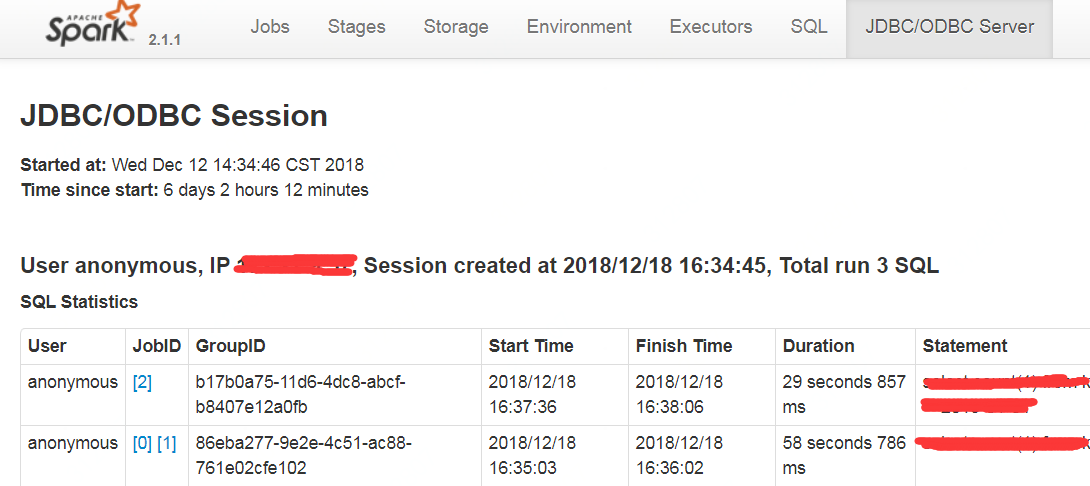
如果能够每次连接spark thrift时记下当前的session id,就可以通过session id找到当前session正在执行的job,查看代码发现,只需要增加一行即可
org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation
private def execute(): Unit = { statementId = UUID.randomUUID().toString logInfo(s"Running query '$statement' with $statementId") //modify here this.operationLog.writeOperationLog("session id : " + this.getParentSession.getSessionState.getSessionId) setState(OperationState.RUNNING)
修改后重新打包,用beeline连接spark thrift执行sql效果如下:
0: jdbc:hive2://spark_thrift:11111> select * from test_table;
session id : 0bc63382-a54a-41f8-8c2e-0323f4ebbde6
+---------+--+
| Result |
+---------+--+
+---------+--+
No rows selected (0.277 seconds)
通过session id找到job id后,就可以通过url来kill job
curl http://rm1/proxy/application_1544593827645_0134/jobs/job/kill/?id=3