Python函数式编程(map()、filter()和reduce())详解
所谓函数式编程,是指代码中每一块都是不可变的,都由纯函数的形式组成。这里的纯函数,是指函数本身相互独立、互不影响,对于相同的输入,总会有相同的输出。
除此之外,函数式编程还具有一个特点,即允许把函数本身作为参数传入另一个函数,还允许返回一个函数。
例如,想让列表中的元素值都变为原来的两倍,可以使用如下函数实现:
def multiply_2(list): for index in range(0, len(list)): list[index] *= 2 return list
需要注意的是,这段代码不是一个纯函数的形式,因为列表中元素的值被改变了,如果多次调用 multiply_2() 函数,那么每次得到的结果都不一样。
而要想让 multiply_2() 成为一个纯函数的形式,就得重新创建一个新的列表并返回,也就是写成下面这种形式:
def multiply_2_pure(list): new_list = [] for item in list: new_list.append(item * 2) return new_list
函数式编程的优点,主要在于其纯函数和不可变的特性使程序更加健壮,易于调试和测试;缺点主要在于限制多,难写。
注意,纯粹的函数式编程语言(比如 Scala),其编写的函数中是没有变量的,因此可以保证,只要输入是确定的,输出就是确定的;而允许使用变量的程序设计语言,由于函数内部的变量状态不确定,同样的输入,可能得到不同的输出。
Python 允许使用变量,所以它并不是一门纯函数式编程语言。Python 仅对函数式编程提供了部分支持,主要包括 map()、filter() 和 reduce() 这 3 个函数,它们通常都结合 lambda 匿名函数一起使用。接下来就对这 3 个函数的用法做逐一介绍。
Python map()函数
map() 函数的基本语法格式如下:
map(function, iterable)
其中,function 参数表示要传入一个函数,其可以是内置函数、自定义函数或者 lambda 匿名函数;iterable 表示一个或多个可迭代对象,可以是列表、字符串等。
map() 函数的功能是对可迭代对象中的每个元素,都调用指定的函数,并返回一个 map 对象。
注意,该函数返回的是一个 map 对象,不能直接输出,可以通过 for 循环或者 list() 函数来显示。
【例 1】还是对列表中的每个元素乘以 2。
listDemo = [1, 2, 3, 4, 5]new_list = map(lambda x: x * 2, listDemo)print(list(new_list))
运行结果为:[2, 4, 6, 8, 10]
【例 2】map() 函数可传入多个可迭代对象作为参数。
listDemo1 = [1, 2, 3, 4, 5]listDemo2 = [3, 4, 5, 6, 7]new_list = map(lambda x,y: x + y, listDemo1,listDemo2)print(list(new_list))
运行结果为:[4, 6, 8, 10, 12]
注意,由于 map() 函数是直接由用 C 语言写的,运行时不需要通过 Python 解释器间接调用,并且内部做了诸多优化,所以相比其他方法,此方法的运行效率最高。
Python filter()函数
filter()函数的基本语法格式如下:
filter(function, iterable)
此格式中,funcition 参数表示要传入一个函数,iterable 表示一个可迭代对象。
filter() 函数的功能是对 iterable 中的每个元素,都使用 function 函数判断,并返回 True 或者 False,最后将返回 True 的元素组成一个新的可遍历的集合。
【例 3】返回一个列表中的所有偶数。
listDemo = [1, 2, 3, 4, 5]new_list = filter(lambda x: x % 2 == 0, listDemo)print(list(new_list))
运行结果为:[2, 4]
【例 4】filter() 函数可以接受多个可迭代对象。
listDemo = [1, 2, 3, 4, 5]new_list = map(lambda x,y: x-y>0,[3,5,6],[1,5,8] )print(list(new_list))
运行结果为:[True, False, False]
Python reduce()函数
reduce() 函数通常用来对一个集合做一些累积操作,其基本语法格式为:
reduce(function, iterable)
其中,function 规定必须是一个包含 2 个参数的函数;iterable 表示可迭代对象。
注意,由于 reduce() 函数在 Python 3.x 中已经被移除,放入了 functools 模块,因此在使用该函数之前,需先导入 functools 模块。
【例 5】计算某个列表元素的乘积。
import functoolslistDemo = [1, 2, 3, 4, 5]product = functools.reduce(lambda x, y: x * y, listDemo)print(product)
运行结果为:120
总结
通常来说,当对集合中的元素进行一些操作时,如果操作非常简单,比如相加、累积这种,那么应该优先考虑使用 map()、filter()、reduce() 实现。另外,在数据量非常多的情况下(比如机器学习的应用),一般更倾向于函数式编程的表示,因为效率更高。
当然,在数据量不多的情况下,使用 for 循环等方式也可以。不过,如果要对集合中的元素做一些比较复杂的操作,考虑到代码的可读性,通常会使用 for 循环。
以下摘自参考gxhlh网友
5.3全 局语句global
在函数体中可以引用全局变量,但如果函数内部的变量名是第一次出现且在赋值语句之前(变量赋值),则解释为定义局部变量。
[例22]函数体错误引用全局变量的示例。
m = 100
n = 200
def f():
print(m+5)
n += 10
f()
如果要为定义在函数外的全局变量赋值,可以使用global语句,表明变量是在外面定义的全局变量。global 语句可以指定多个全局变量,例如“global x, y, z”。一 般应该尽量避免这样使用全局变量,全局变量会导致程序的可读性差。
[例23]全局语句global
pi = 3.141592653589793 #全局变量
e = 2.718281828459045 #全局变量
def my_func():
global pi #全局变量,与前面的全局变量pi指向相同的对象
pi = 3.14 #改变了全局变量的值
print('global pi =', pi) #输出全局变量的值
e = 2.718 #局部变量,与前面的全局变量e指向不同的对象
print('local e =', e) #输出局部变量的值
#测试代码
print('module pi =', pi) #输出全局变量的值
print('module e =', e) #输出全局变量的值
my_func() #调用函数
print('module pi =', pi) #输出全局变量的值,该值在函数中已被更改
print('module e =', e) #输出全局变量的值

5.4非局部语句nonlocal
在函数体中可以定义嵌套函数,在嵌套函数中如果要为定义在上级函数体的局部变量赋值,可以使用nonlocal语句,表明变量不是所在块的局部变量而是在上级函数体中定义的局部变量,nonlocal语句可以指定多个非局部变量。例如“nonlocalx,y,z".
[例24]非局部语句
def outer_func():
tax_rate = 0.17 #上级函数体中的局部变量
print('outer func tax rate =', tax_rate) #输出上级函数体中局部变量的值
def innner_func():
nonlocal tax_rate #不是所在块的局部变量,而是在上级函数体中定义的局部变量
tax_rate = 0.05 #上级函数体中的局部变量重新赋值
print('inner func tax rate =', tax_rate) #输出上级函数体中局部变量的值
innner_func() #调用函数
print('outer func tax rate =', tax_rate) #输出上级函数体中局部变量的值(已更改)
#测试代码
outer_func()

5.5 类成员变量
类成员变量是在类中声明的变量,包括静态变量和实例变量,其有效范围(作用域)为类定义体内。
在外部,通过创建类的对象实例,然后通过“对象.实例变量”访问类的实例变量,或者通过“类.静态变量”访问类的静态变量。
5.6 输出局部变量和全局变量
在程序运行过程中,在上下文中会生成各种局部变量和全局变量,使用内置函数global和locals()可以查看并输出局部变量和全局变量列表。
[例25]局部变量和全局变量列表示例(locals_ globals. py)。
a=1
b=2
def f(a, b):
x = 'abc'
y = 'xyz'
for i in range(2): #i=0~1
j = i
k = i**2
print(locals())
f(1,2)
print(globals())
在这里插入图片描述
6、递归函数
6.1递归函 数的定义
递归函数即自调用函数,在函数体内部直接或间接地自己调用自己,即函数的嵌套调用是函数本身。递归函数常用来实现数值计算的方法。
[例26]使 用递归函数实现阶乘
def factorial(n):
if n == 1: return 1
return n * factorial(n - 1)
#测试代码
for i in range(1,10): #输出1~9的阶乘
print(i,'! =', factorial(i))
在这里插入图片描述
6.2递归函数的原理
递归提供了建立数学模型的一种直接方法,与数学上的数学归纳法相对应。
每个递归函数必须包括以下两个主要部分。
(1)终止条件:表示递归的结束条件,用于返回函数值,不再递归调用。例如,factorial()函数的结束条件为“n等于1”。
(2)递归步骤:递归步骤把第n步的参数值的函数与第n-1步的参数值的函数关联。
例如,对于factorial(),其递归步骤为“n * factorial(n- 1)”。
另外,一序列的参数值必须逐渐收敛到结束条件。例如,对于factorial(),每次递归调用参数值n均递减1,所以一序列参数值逐渐收敛到结束条件(n=1)。
例如,调和数的计算公式如下。
H。=1十1/2+…+1/n
故可以使用递归函数实现。
(1)终止条件: H。= 1
当n==l时
(2)递归步骤: H。= H。-1+ 1/n
当n>1时
每次递归,n严格递减,故逐渐收敛于1。
[例27]使 用递归函数实现调和数 。
def harmonic(n):
if n == 1: return 1.0 #终止条件
return harmonic(n-1) + 1.0/n #递归步骤
#测试代码
for i in range(1,10): #输出1~9阶的调和数
print('H', i, ' =', harmonic(i))
在这里插入图片描述
6.3编写递归函数时需要注意的问题
虽然使用递归函数可以实现简洁、优雅的程序,但在编写递归雨数时应该注意如下几个问题。
(1)必须设置终止条件。
缺少终止条件的递归函数将导致无限递归函数调用,其最终结果是系统会耗尽内存,此时Python会抛出错误RuntimeError, 并报告错误信息“maximum recursion depth exceeded(超过最大递归深度)”。
在递归函数中一般需要设置终止条件。在sys模块中,函数getrecursionlimit()和setrecursionlimit()用于获取和设置最大递归次数。例如:
import sys
sys. getrecursionlimit()#获取最大递归次数:1000
sys. setrecursionl imit(2000)#设置最大递归次数为2000
(2)必须保证收敛。
递归调用所解决子问题的规模必须小于原始问题的规模,否则会导致无限递归函数调用
(3)必须保证内存和运算消耗控制在定范围内。
递归函数代码虽然看起来简单,但往往会导致过量的递归函数调用,从而消耗过量的内存(导致内存溢出),或过量的运算能力(运行时间过长)。
6.4 递归函数的应用:最大公约数
用于计算最大公约数问题的递归方法称为欧几里得算法,其描述如下:
如果p>q,则p和q的最大公约数等于q和p % q的最大公约数。
故可以使用递归函数实现,步骤如下。
(1)终止条件: gcd(p,q) = p #当q==0时
(2)递归步骤: gcd(q, p%q) #当q>1时
每次递归,p%q严格递减,故逐渐收敛于0。
[例28]使用递归函数计算最大公约数。
import sys
def gcd(p, q): #使用递归函数计算p和q的最大公约数
if q == 0: return p #如果q=0,返回p
return gcd(q, p % q) #否则,递归调用gcd(q, p % q)
#测试代码
p = int(sys.argv[1]) #p=命令行第一个参数
q = int(sys.argv[2]) #q=命令行第二个参数
print(gcd(p, q)) #计算并输出p和q的最大公约数
在这里插入图片描述
6.5 递归函数的应用:汉诺塔
汉诺塔(Towers of Hanoi, 又称河内塔)源自于印度的古老传说:大梵天创造世界的时候,在世界中心贝拿勒斯的圣庙里做了3根金刚石柱子,在一根柱子上从下往上按照大小顺序摞着64片黄金圆盘,称之为汉诺塔。
大梵天命令婆罗门把圆盘从一根柱子上按大小顺序重新摆放到另一根柱子上,并且规定在3根柱子之间一次只能移动个圆盘,且小圆盘上不能放置大圆盘。这个游戏称为汉诺塔益智游戏。
汉诺塔益智游戏问题很容易使用递归函数实现。假设柱子的编号为a、b、c,定义函数hanoi(n, a, b, c)表示把n个圆盘从柱子a移到柱子c(可以经由柱子b),则有:
(1)终止条件。当n==1时,hanoi(n, a, b, c)为终止条件。即如果柱子a上只有一个圆盘,则可以直接将其移动到柱子c上。
(2)递归步骤。hanoi(n,a, b, c)可以分解为3个步骤,即hanoi(n-1,a,c,b)、hanoi(1,a,b,c)和hanoi(n-1,b,a.c)。 如果柱子a上有n个圆盘,可以看成柱子a上有一个圆盘(底盘)和(n- 1)个圆盘,首先需要把柱子a上面的(n-1)个圆盘移动到柱子b.即调用hanoi(n-1,a,c,b); 然后把柱子a上的最后一个圆盘移动到柱子c,即调用hanoi(1,a,b.c);再将柱子b上的(n- 1)个圆盘移动到柱子c,即调用hanoi(n-1,b,a,c)。
每次递归,n严格递减,故逐渐收敛于1.
[例29]使用递归 函数实现汉诺塔问题。
#将n个从小到大依次排列的圆盘从柱子a移动到柱子c上,柱子b作为中间缓冲
def hanoi(n,a,b,c):
if n==1: print(a,'->',c) #只有一个圆盘,直接将圆盘从柱子a移动到柱子c上
else:
hanoi(n-1,a,c,b) #先将n-1个圆盘从柱子a移动到柱子b上(采用递归方式)
hanoi(1,a,b,c) #然后将最大的圆盘从柱子a移动到柱子c上
hanoi(n-1,b,a,c) #再将n-1个圆盘从柱子b移动到柱子c上(采用递归方式)
#测试代码
hanoi(4,'A','B','C')

7、内置函数的使用
在python语言中提供了若干内置函数,用于实现常用的功能,可以直接使用。
7.1 内置函数一览表
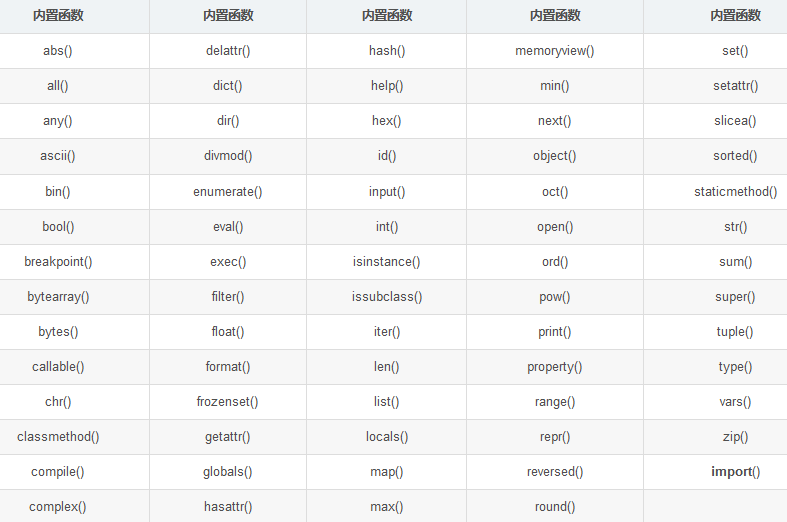
内置函数 内置函数 内置函数 内置函数 内置函数
abs() delattr() hash() memoryview() set()
all() dict() help() min() setattr()
any() dir() hex() next() slicea()
ascii() divmod() id() object() sorted()
bin() enumerate() input() oct() staticmethod()
bool() eval() int() open() str()
breakpoint() exec() isinstance() ord() sum()
bytearray() filter() issubclass() pow() super()
bytes() float() iter() print() tuple()
callable() format() len() property() type()
chr() frozenset() list() range() vars()
classmethod() getattr() locals() repr() zip()
compile() globals() map() reversed() import()
complex() hasattr() max() round()
各个内置函数的具体功能和用法,可通过访问 https://docs.python.org/zh-cn/3/library/functions.html 进行查看。
需要注意的是,开发者不建议使用以上内置函数的名字作为标识符使用(作为某个变量、函数、类、模板或其他对象的名称),虽然这样做 Python 解释器不会报错,但这会导致同名的内置函数被覆盖,从而无法使用。
8、Python函数式编程基础
Python是面向对象的程序设计语言,也是面向过程的程序语言,同时也支持函数式编程。
Pyhon标准库functools 提供了若干关于函数的函数,提供了Haskell和Standard ML中的函数式程序设计工具。
8.1作为对象的函数
在Python语言中函数也是对象,故函数对象可以赋值给变量。
[例30]作为对象的函数。
f=abs
type(f) #输出:<class 'builtin function or_ method'>
f(-123) #返回绝对值输出:123
8.2 高阶函数
函数对象也可以作为参数传递给函数,还可以作为函数的返回值。参数为函数对象的函数或返回函数对象的函数称为高阶函数,即函数的函数。
[例31]高阶函数。
def compute(f, s): #f为函数对象,s为系列对象
return f(s)
compute(min,(1,5,3,2))
8.3 map()函数
map() 函数的基本语法格式如下:
map(function, iterable)
其中,function 参数表示要传入一个函数,其可以是内置函数、自定义函数或者 lambda 匿名函数;iterable 表示一个或多个可迭代对象,可以是列表、字符串等。
map() 函数的功能是对可迭代对象中的每个元素,都调用指定的函数,并返回一个 map 对象。
注意,该函数返回的是一个 map 对象,不能直接输出,可以通过 for 循环或者 list() 函数来显示。
【例32】还是对列表中的每个元素乘以 2。
listDemo = [1, 2, 3, 4, 5]
new_list = map(lambda x: x * 2, listDemo)
print(list(new_list))
运行结果为:
[2, 4, 6, 8, 10]
【例33】map() 函数可传入多个可迭代对象作为参数。
listDemo1 = [1, 2, 3, 4, 5]
listDemo2 = [3, 4, 5, 6, 7]
new_list = map(lambda x,y: x + y, listDemo1,listDemo2)
print(list(new_list))
运行结果为:
[4, 6, 8, 10, 12]
注意,由于 map() 函数是直接由用 C 语言写的,运行时不需要通过 Python 解释器间接调用,并且内部做了诸多优化,所以相比其他方法,此方法的运行效率最高。
8.4 filter()函数
filter()函数的基本语法格式如下:
filter(function, iterable)
此格式中,funcition 参数表示要传入一个函数,iterable 表示一个可迭代对象。
filter() 函数的功能是对 iterable 中的每个元素,都使用 function 函数判断,并返回 True 或者 False,最后将返回 True 的元素组成一个新的可遍历的集合。
【例34】返回一个列表中的所有偶数。
listDemo = [1, 2, 3, 4, 5]
new_list = filter(lambda x: x % 2 == 0, listDemo)
print(list(new_list))
运行结果为:
[2, 4]
【例35】filter() 函数可以接受多个可迭代对象。
listDemo = [1, 2, 3, 4, 5]
new_list = map(lambda x,y: x-y>0,[3,5,6],[1,5,8] )
print(list(new_list))
运行结果为:
[True, False, False]
8.5 reduce()函数
reduce() 函数通常用来对一个集合做一些累积操作,其基本语法格式为:
reduce(function, iterable)
其中,function 规定必须是一个包含 2 个参数的函数;iterable 表示可迭代对象。
注意,由于 reduce() 函数在 Python 3.x 中已经被移除,放入了 functools 模块,因此在使用该函数之前,需先导入 functools 模块。
【例36】计算某个列表元素的乘积。
import functools
listDemo = [1, 2, 3, 4, 5]
product = functools.reduce(lambda x, y: x * y, listDemo)
print(product)
运行结果为:
120
小结:
通常来说,当对集合中的元素进行一些操作时,如果操作非常简单,比如相加、累积这种,那么应该优先考虑使用 map()、filter()、reduce() 实现。另外,在数据量非常多的情况下(比如机器学习的应用),一般更倾向于函数式编程的表示,因为效率更高。
当然,在数据量不多的情况下,使用 for 循环等方式也可以。不过,如果要对集合中的元素做一些比较复杂的操作,考虑到代码的可读性,通常会使用 for 循环。
8.6 lambda表达式(匿名函数)及用法
lambda 表达式(又称匿名函数)是现代编程语言争相引入的一种语法,如果说函数是命名的、方便复用的代码块,那么 lambda 表达式则是功能更灵活的代码块,它可以在程序中被传递和调用。
回顾局部函数
def get_math_func(type) :
# 定义一个计算平方的局部函数
def square(n) : # ①
return n * n
# 定义一个计算立方的局部函数
def cube(n) : # ②
return n * n * n
# 定义一个计算阶乘的局部函数
def factorial(n) : # ③
result = 1
for index in range(2 , n + 1):
result *= index
return result
# 返回局部函数
if type == "square" :
return square
if type == "cube" :
return cube
else:
return factorial
# 调用get_math_func(),程序返回一个嵌套函数
math_func = get_math_func("cube") # 得到cube函数
print(math_func(5)) # 输出125
math_func = get_math_func("square") # 得到square函数
print(math_func(5)) # 输出25
math_func = get_math_func("other") # 得到factorial函数
print(math_func(5)) # 输出120
程序中,定义了一个 get_math_func() 函数,该函数将返回另一个函数。接下来在 get_math_func() 函数体内的 ①、②、③ 号代码分别定义了三个局部函数,最后 get_math_func() 函数会根据所传入的参数,使用这三个局部函数之一作为返回值。
在定义了会返回函数的 get_math_func() 函数之后,接下来程序调用 get_math_func() 函数时即可返回所需的函数
由于局部函数的作用域默认仅停留在其封闭函数之内,因此这三个局部函数的函数名的作用太有限了,即仅仅是在程序的 if 语句中作为返回值使用。一旦离开了 get_math_func() 函数体,这三个局部函数的函数名就失去了意义。
既然局部函数的函数名没有太大的意义,那么就考虑使用 lambda 表达式来简化局部函数的写法。
使用 lambda 表达式代替局部函数
如果使用 lambda 表达式来简化 get_math_func() 函数,则可以将程序改写成如下形式:
def get_math_func(type) :
result=1
# 该函数返回的是Lambda表达式
if type == 'square':
return lambda n: n * n # ①
elif type == 'cube':
return lambda n: n * n * n # ②
else:
return lambda n: (1 + n) * n / 2 # ③
# 调用get_math_func(),程序返回一个嵌套函数
math_func = get_math_func("cube")
print(math_func(5)) # 输出125
math_func = get_math_func("square")
print(math_func(5)) # 输出25
math_func = get_math_func("other")
print(math_func(5)) # 输出15.0
在上面代码中,return 后面的部分使用 lambda 关键字定义的就是 lambda 表达式,Python 要求 lambda 表达式只能是单行表达式。
注意:由于 lambda 表达式只能是单行表达式,不允许使用更复杂的函数形式,因此上面 ③ 号代码处改为计算 1+2+3+…+n 的总和。
lambda 表达式的语法格式如下:
lambda [parameter_list] : 表达式
从上面的语法格式可以看出 lambda 表达式的几个要点:
lambda 表达式必须使用 lambda 关键字定义。
在 lambda 关键字之后、冒号左边的是参数列表,可以没有参数,也可以有多个参数。如果有多个参数,则需要用逗号隔开,冒号右边是该 lambda 表达式的返回值。
实际上,lambda 表达式的本质就是匿名的、单行函数体的函数。因此,lambda 表达式可以写成函数的形式。
例如,对于如下 lambda 表达式:
lambda x , y:x + y
可改写为如下函数形式:
def add(x, y):
return x+ y
上面定义函数时使用了简化语法:当函数体只有一行代码时,可以直接把函数体的代码放在与函数头同一行。
总体来说,函数比 lambda 表达式的适应性更强,lambda 表达式只能创建简单的函数对象(它只适合函数体为单行的情形)。但 lambda 表达式依然有如下两个用途:
对于单行函数,使用 lambda 表达式可以省去定义函数的过程,让代码更加简洁。
对于不需要多次复用的函数,使用 lambda 表达式可以在用完之后立即释放,提高了性能。
下面代码示范了通过 lambda 表达式来调用 Python 内置的 map() 函数:
# 传入计算平方的lambda表达式作为参数
x = map(lambda x: x*x , range(8))
print([e for e in x]) # [0, 1, 4, 9, 16, 25, 36, 49]
# 传入计算平方的lambda表达式作为参数
y = map(lambda x: x*x if x % 2 == 0 else 0, range(8))
print([e for e in y]) # [0, 0, 4, 0, 16, 0, 36, 0]
正如从上面代码所看到的,内置的 map() 函数的第一个参数需要传入函数,此处传入了函数的简化形式:lambda 表达式,这样程序更加简洁,而且性能更好。
小结:
lambda 表达式是 Python 编程的核心机制之一。Python 语言既支持面向过程编程,也支持面向对象编程。而 lambda 表达式是 Python 面向过程编程的语法基础,因此必须引起重视。
Python 的 lambda 表达式只是单行函数的简化版本,因此 lambda 表达式的功能比较简单。
参考:C语言中文网
原文链接:https://blog.csdn.net/qq_44721831/article/details/102883028